
2023-3-19 08:12:44 Author: gynvael.coldwind.pl(查看原文) 阅读量:10 收藏
Disclaimer: I am not a lawyer. Furthermore, remember that laws differ between countries.
Let me preface this post by saying that I don't have answers – I have only (interesting) questions. And perhaps the answer to the question in the headline eventually will follow Betteridge's law of headlines anyway.
So what is all this about?
In reverse-engineering there is a concept called clean room design. In short, it's a method of "copying" (and I'm using this term very loosely) someone's implementation of an idea without infringing on their copyrights. And while the term is a bit more generic, I will focus on it's application to software (code). In short, the method boils down to 3 steps:
- Reverse-engineers analyze the source software and prepare detailed documentation about how things look like and how they are done.
- Lawyers review the documentation to make sure no piece of code was included (or more generally: no copyrightable items were included).
- Software engineers implement a new piece of software based on this documentation.
The idea behind clean room design is that while code is copyrightable, algorithms and ideas generally are not. Therefore, while directly copying code is basically illegal in many countries, describing the idea and re-implementing it by someone who never saw the original code seems to be legally fine. Note that this method does nothing about software patents – this is only about "bypassing" copyrights.
All in all this method is quite expensive – neither lawyers, nor reverse-engineers, nor software engineers are cheap.
And this is where Large Language Models (LLMs) come in.
The recently released GPT-4 is surprisingly decent both in source code analysis and documentation-based implementation. Sure, it makes a lot of mistakes, but we can assume improved models will appear in the next 5-10 years (including specialized models for exactly this job), so for the sake of the discussion let's assume LLMs eventually will be pretty decent in both tasks. Now, let's augment the clean room design process with LLMs. Here's what we arrive at:
- Code is fed to LLM asking it to describe what it does without quoting the code.
- Maybe lawyers review the generated documentation? Or maybe LLM does this too?
- Generated description is fed to LLM asking it to generate code based on it.
The outcome is basically the same at a fraction of the cost.
Furthermore this can be heavily automatized, in the edge case having the form of tool that can be run on a given directory: ./llm-clean-room ./product.
Consequences of cheap and automated clean room design in case of software are hard to predict, but here are some guesses:
- A large corporation might decide it's a more viable strategy to "clone" a piece of software than to comply with e.g. the highly restrictive viral open-source AGPL license.
- A competitor might "clone" a piece of software from the another company for the fraction of the initial development cost.
- There might be a large shift to SaaS model as a defense tactic, as copyright on code would effectively be ineffective.
- EULAs might start to include clauses disallowing the product to be fed into LLMs for any reason (though I doubt this would be effective at all).
- On the flip side, it might also mean longer life for some orphaned / deprecated products.
So far I did omit a few elephants in the room, so let's point them out:
- First of all there is no consensus about the ownership of the outputted code. Yes, we have the case of the US Copyright Office leaning towards not granting copyrights for AI generated art, however as of now this has not been tested in case of code unless I'm mistaking.
- Second of all, the generated code itself might be based on the source material LLM was taught on, therefore potentially infringing copyrights of original authors. See for example the GitHub Copilot lawsuit.
- "Cloning" a project like this is of course only one thing. Debugging it until it works and further maintenance and development is another issue.
- I shudder just thinking about all the security issues introduced in this "cloning" process.
To summarize, we do live in interesting times.
P.S. below you'll find two tiny test examples of applied clean room design using GPT-4.
Tiny example 1: a small ad-hoc tool
The question arose when I was playing with GPT-4 trying to figure out what uses might it have. Given my background as a reverse-engineer I thought about the clean room method and decided to try it out.
The initial example consisted of an ad-hoc script I've written to convert a CSV file with conference talk submissions to a more readable HTML format. Here's a screenshot of what my script generated:

And here's the original code: https://gist.github.com/gynvael/0f9e229c3a0ad308fc91c0a7233bd4df. As you can see this is indeed a very simple ad-hoc script.
Next, I've fed this script to ChatGPT (GPT-4 model) with the following prompts:
Describe what this Python code does without quoting any pieces of the code. Do not include any names of variables either.
---
[code followed]
Add a description of the order of columns in the CSV file.
Here's what GPT-4 generated (note: I had to remove field names in CSV description output since my prompt didn't instruct GPT-4 to do it):
The given Python code does the following:
1. Imports the csv module to handle CSV files.
2. Defines a function that takes a string as input and returns a new string with certain characters replaced by their corresponding HTML entities or tags. This is done to sanitize the input for displaying it as HTML.
3. Prints the beginning of an HTML document, including a simple CSS style block to style the content.
4. Opens a CSV file named 'cfp.csv' and reads its contents using a CSV reader.
5. Iterates through the rows of the CSV file, skipping the first row (header) and processes the remaining rows.
6. For each row, the function defined earlier is applied to every element in the row. Then, some specific elements (such as names, company, topic, category, level, abstract, language, and additional information) are extracted from the sanitized row.
7. If the topic and abstract are both empty, the row is skipped.
8. For each remaining row, an HTML div with class "entry" is printed, containing formatted information about the speaker, the topic, the target audience, and additional details.
9. Closes the HTML document by printing the closing tags.
Overall, this script reads a CSV file containing conference proposal data and generates an HTML document to display the information in a human-readable format.
The order of columns in the CSV file is as follows:
1. A unique identifier for the entry.
2. The first name of the speaker.
3. The last name of the speaker.
4. (Skipped column)
5. (Skipped column)
6. (Skipped column)
7. The company or organization the speaker is affiliated with.
8. A short biography of the speaker.
9. The title or subject of the proposed talk.
10. The category or field to which the talk belongs.
11. The intended audience level for the talk (e.g., beginner, intermediate, advanced).
12. A brief description or summary of the talk.
13. The language in which the talk will be presented.
14. Any additional information or notes related to the proposal.
Next, I've started a new ChatGPT session and fed it the description above with the following prompt:
Generate a Python script that does the following:
The code generated can be seen here: https://gist.github.com/gynvael/993cd2de1f0f0cba072813c02a5bfde7. It is observably different from the original. And it does the similar thing – here's a screenshot of its output:

Time it took: Around 10 minutes.
Total cost: 3 messages from my GPT-4 quota (which is at this moment 25 messages every 3 hours in the ~$20 ChatGPT Plus monthly subscription).
Tiny example 2: the absolutely slow metaballs
Looking for another example – a bit larger but not by much (8k token limit) – to try this out I found this old post from 2008 with metaballs:
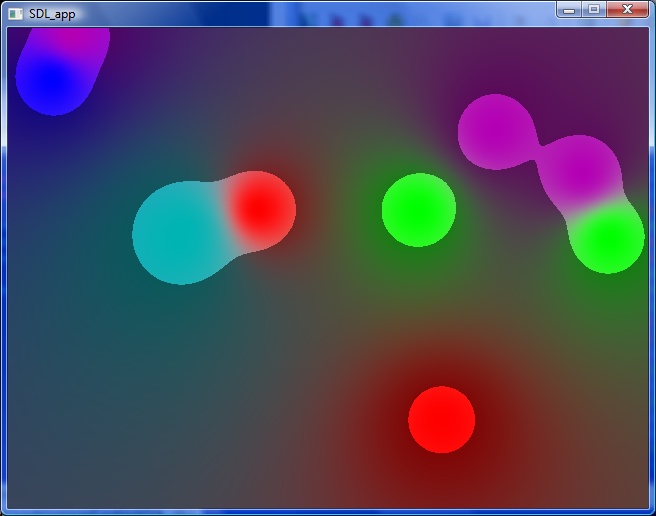
Source code is available here: /download.php?f=metaballs.py. It's terrible, sorry.
The prompts used this time were:
Generate a verbose detailed description of what this Python code does.
Do not quote variable names, function names, class names, etc - if needed, make up a new name for a given function/etc. Only describe what the code does.
Do not quote the code itself.
---
[code here]
Without quoting the code, describe the used metaball math.
The description generated by ChatGPT (GPT-4) was:
The code creates a window displaying a simulation of metaballs, which are 2D representations of moving, colorful blobs that blend into each other when they come close. The program is built using the Pygame library.
The program starts by importing necessary libraries and initializing some constants. It then defines several functions that handle the following tasks:
1. Handling the exit event - this function checks if the user closes the window, and terminates the program accordingly.
2. Adding a metaball - this function appends a metaball to a list, taking in the x and y coordinates, the x and y velocities, and the red, green, and blue color components.
3. Drawing the scene - this function calculates the color and intensity of each pixel on the canvas based on the metaballs' influence and then updates the display.
4. Updating metaball positions - this function moves each metaball based on its velocity and bounces it off the window boundaries.
After defining these functions, the program initializes Pygame and creates a window. It also retrieves the surface of the window and initializes a list of metaballs with two initial metaballs.
The main loop of the program repeatedly performs the following tasks:
1. Check for user events and handle them accordingly.
2. Draw the scene with the metaballs.
3. Update the positions of the metaballs.
4. Calculate and print the time taken for each iteration.
The simulation continues until the user closes the window.
The metaball math used in this code is based on the principle of calculating the influence of each metaball on the pixels of the canvas. The influence is calculated using an inverse square distance formula.
For each pixel on the canvas, the code computes its distance to every metaball, and calculates an inverse square distance value. The inverse square distance is the reciprocal of the square of the distance between the pixel and the metaball. If the pixel is exactly at the position of the metaball, the inverse distance is set to 1.
The code then calculates the red, green, and blue components of the pixel color by summing the product of each metaball's respective color component and its inverse square distance. The total influence or power at the pixel is the sum of the inverse square distances of all metaballs.
Next, the code normalizes the red, green, and blue components of the pixel color by dividing them by the square root of the sum of the squares of the components. This ensures that the color components have a maximum value of 1.
To determine the final color of the pixel, the code checks if the total influence or power at the pixel is greater than or equal to a predefined threshold. If it is, the intensity of the color is set to the maximum (255), otherwise, it is set to a lower value (128). The red, green, and blue components are then multiplied by this intensity value and cast to integers.
Finally, the resulting color is assigned to the pixel on the canvas, and the process is repeated for all pixels in the window.
As previously, I've fed this back to ChatGPT (GPT-4) in a new session using the following prompt:
Generate Python code based on this description:
---
[description here]
The generated code can be found here: https://gist.github.com/gynvael/754b1a7a3f5f8d797e6c9398d6317cec. Note that because this code is somehow even slower than mine, I moved the metaballs to be a bit closer to each other.
And here's a screenshot:
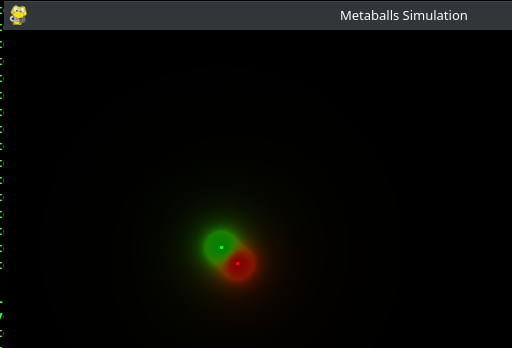
Time it took: Around 7 minutes. Though likely around 15 more minutes would have to be added to tweak parameters to arrive at a similarly looking result.
Total cost: Another 3 messages from my GPT-4 quota.
如有侵权请联系:admin#unsafe.sh