0理解基础1
Ollvm是现在很多集成用于so文件的代码保护方案,ollvm有几个代码保护方案分别为控制流平坦化、虚假指令、指令替换、字符串加密。这几个保护方案啊是可以通过累加方式进行对so文件保护。
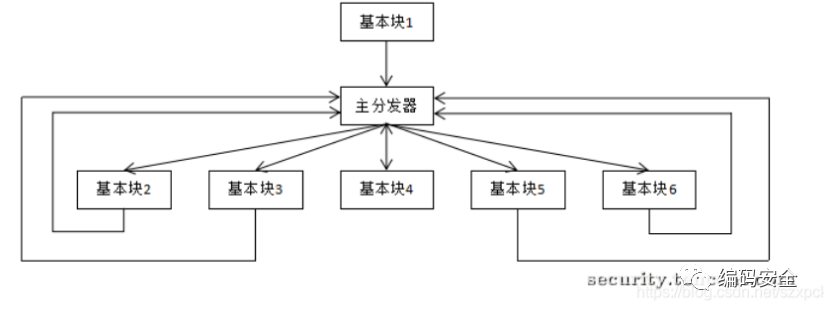
这篇主要分享下ollvm代码保护方案下的控制流平坦化的原理,控制流平坦化它是以基本块为单位,通过一个主分发器来控制程序的执行流程。
控制流平坦化在代码上是指将原程序的正常程序控制流中基本块之间的跳转关系链删除,用一个集中的主分发块来调度基本块的执行顺序。保护后展现出来可以简要地理解为是while+switch的结构,其中的switch可以理解为主分发器。这样通过模糊基本块之间的前后关系,增加静态逆向代码分析的难度。
原始的if--else结构

通过ollvm的平坦化保护后的结构

0平坦化基础1
我们的代码中每一块的基本块可能会有后继和前驱,总体上的思路就是:先将原始程序的基本块保存下来,找到开头的基本块,分配一个变量switchVar并赋值,在后面添加一个Switch指令,根据switchVar跳转向其他的基本块,然后更新switchVar,让基本块跳转到正确的后继基本块中。
代码平坦化主要由分发器、虚假块、真实块这三个个基本组成:

平坦化后的基本结构图
入口块:进入函数第一个执行的基本块
分发块:负责跳转到下一个要执行的原基本块
原基本块:混淆之前的基本块,实际完成程序工作的真实基本块
返回块:返回到主分发块。
平坦化的基本实现流程:1、保存原程序基本块;2、创建分发块和返回块;3、实现分发块的调度;4、实现调度变量的自动调整;5、修复指令和变量
平坦化化修改了代码正常的控制流,这样逆向分析人员就不容易直接的理清程序执行流程,增加静态分析难度。
0实例分析1
下面就从个简单的代码进行分析正常的程序流和ollvm的平坦化后的程序流

通过在函数定义后面添加__attribute((__annotate__((“fla”))))指令,就可以实现对指定函数对代码进行平坦化保护。

就简单的代码程序流,通过平坦化后,从上图中可以看出整个程序基本结构都发生了改变,这里面有虚虚实实的代码块,需要识别你去出哪个是虚假的代码块,哪个是真实的代码块。这无疑给程序的静态分析加大的门槛。
通过平坦化后的代码,实际上真正的代码块都是在最下面一排整齐的排列的代码块中的。前面的流程和结构都是虚假混淆分析的虚假代码块。

从上图伪代码中比较,正常的代码逻辑这种很清晰可以还原出逻辑结构,右边的平坦化后的伪代码可以看到,这个伪代码中增加了while、switch的语句,并且新增了个几个变量,这些的增加虚假代码,这大大的强化了静态分析难度。
对于分析这种平坦化保护后的代码,frida和unicorn去动态分析是个不错的选择。
0小结1
这个市面上很多产品都采用虚拟机或者基于ollmv的平坦化的混淆保护,有些明明可以将代码保护强度可以设置为很强,但产品所表现出来的是强度相对没那么强。因为这个代码保护混淆后会和执行效率内存开销捆绑的,产品不得不做出一些妥协降低代码保护强度。


本文作者:编码安全
本文为安全脉搏专栏作者发布,转载请注明:https://www.secpulse.com/archives/197964.html
如有侵权请联系:admin#unsafe.sh