随着推荐算法技术的不断发展,跨场景学习已经受到了越来越多的研究人员的关注。美团到餐算法团队受到业界相关技术的启发,不断探索到店餐饮多场景推荐的优化问题,在多场景多任务学习的推荐领域中积累了较多的应用经验。团队使用到店餐饮全域推荐场景数据训练统一的多场景多任务学习模型,减少了重复性开发,并在多个到店餐饮推荐场景进行落地,取得了较为显著的效果。
本文详细阐述了美团到店餐饮业务中多场景多任务学习的解决方案,基于该方案形成的学术论文《HiNet: Novel Multi-Scenario & Multi-Task Learning with Hierarchical Information Extraction》已经被国际数据工程会议ICDE 2023收录。
1. 背景
随着网络信息和服务的爆炸式增长,推荐系统已经成为为用户提供高质量个性化决策建议和体验的关键组件。传统的推荐系统,模型服务通常需要为特定场景单独进行定制化的开发,以适配不同场景下数据分布和特征空间的差异。然而在美团等工业互联网平台中通常存在多种多样的推荐场景(例如首页信息流、垂类子频道等)作用于用户访问的决策链路,同时基于每个场景的个性化推荐模型再对展示项目进行排序最终呈现给用户。
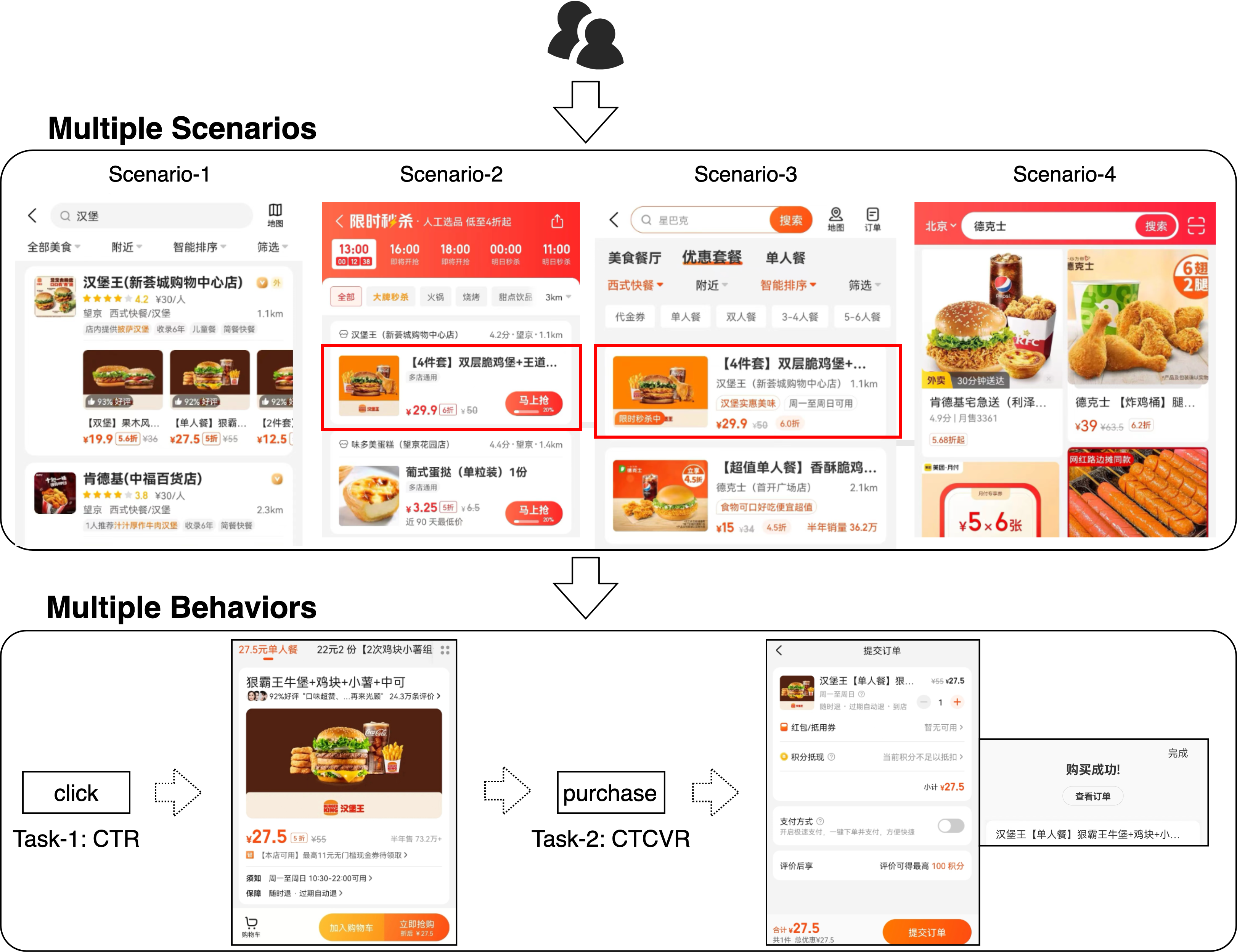
在美团到店餐饮(以下简称到餐)平台中,伴随业务精细化的发展趋势,越来越多的场景需要对推荐系统进行定制化的建设,以满足用户到店就餐的个性化需求。如下图1所示,现实中用户往往会在多个不同场景之间进行浏览、点击,并最终成交。

但随着推荐场景数量的增加,传统地针对单个场景独立开发推荐模型,往往会导致如下问题:
- 仅根据单场景自身的数据进行建模,无法利用到用户在跨场景中丰富的行为信息,忽视了场景共性信息,特别是考虑到多种场景中可能会存在重复展示的商品(在上图1中,红色矩形框圈中的其实是相同的商品)。
- 一些长尾的业务场景由于流量较小且用户行为较为稀疏,数据量不足以让模型有效地进行建模。
- 由于每个场景的特征挖掘、模型训练和上线部署是独立开发且相互隔离的,这会大大增加计算成本和维护负担。
总的来讲,推荐算法对各场景单独建模存在诸多的局限性。然而,简单地将多个场景数据集进行合并训练一个排序模型来提供服务,并不能有效地捕获到每个场景的特有信息。
此外,除了多场景推荐问题,每个场景中的用户满意度和参与度等通常都存在不同的衡量指标需要共同优化,例如点击率(CTR)和点击转化率(CTCVR)。因此需要开发一个有效和统一的框架,来解决这种在多个场景中优化各种指标复杂性的问题(即多场景多任务优化问题)。
在最近的一些研究中,相关方法往往是将多场景推荐做为一个多任务学习(Multi-Task Learning,MTL)问题进行建模,并且此类方法大多使用多门控混合专家(Multi-gate Mixture-of-Experts,MMoE)网络框架作为模型改进的基础来学习场景之间的共性和特性。然而,这种基于MTL的方法往往将多个场景的数据信息投影到同一个特征空间进行优化,这很难充分捕捉到具有多个任务的众多场景之间的复杂关系,因此也无法进一步提升多场景多任务学习模型的性能。
从直觉来看,多场景和多任务的信息建模应属于不同层次的优化,应该进行分层处理。因此,在本文中,我们提出了一种层次化信息抽取网络(Hierarchical information extraction Network,HiNet)。具体来说,我们设计了一个端到端的两层信息抽取框架,来共同建模场景间和任务间的信息共享和协作。
首先,在场景抽取层(Scenario Extraction Layer),HiNet能够通过单独的专家模块提取场景共享信息和场景特有信息。为了进一步加强对当前场景的表示学习,我们设计了场景感知注意力网络(Scenario-aware Attentive Network,SAN),显式学习其他场景对当前场景的信息表征贡献程度。
然后,在任务抽取层(Task Extraction Layer),利用自定义的由任务共享和任务特有专家网络组成的门控网络,有效地缓解了多任务学习中共享信息和任务特有信息之间的参数干扰。
通过在模型结构上分离场景层和任务层的信息提取,可以将不同场景下的多个任务明确划分到不同的特征空间中进行优化,从而有利于提升模型性能。
整个论文的主要创新点如下:
- 我们提出了一种新颖的多场景多任务学习模型HiNet,用于优化多场景下的多种任务指标,其中创新性地应用了分层信息抽取架构。
- 在场景信息抽取层中,我们提出了场景感知注意力网络SAN模块,进一步增强了场景信息建模的能力。
- 离线评估和在线A/B测试的实验证明了HiNet优于当前主要方法。目前,HiNet已在美团到餐中的两个场景中进行了全面部署。
2. 层次化信息抽取网络
2.1 问题定义
如上所述,我们主要关注的是多场景多任务推荐的优化问题。我们将该问题定义为:$\hat{y}_i^j=f_i^j\left(x, s_i\right)$,其中$s_i$表示第$i$个场景指示,$\hat{y}_i^j$是第$i$个场景下任务$j$的预估值,$x$表示输入的稠密特征。
原始的特征输入中主要包括了用户画像特征、用户行为特征、当前场景特有特征和商品特征,其中的数值特征首先被转化为分类特征,然后将所有分类特征映射到低维向量空间来获得$x$。考虑到美团到餐平台中具体的优化目标,我们分别为每个场景设置了CTR和CTCVR两个任务。
2.2 方法介绍
本小节将展开介绍层次化信息抽取网络模型HiNet。如下图2-(A)所示,HiNet模型中主要包括场景抽取层和任务抽取层两个核心模块。其中在场景抽取层主要包括了场景共享专家(Scenario-shared expert)模块、当前场景特有专家(Scenario-specific expert)模块以及场景感知注意力网络,通过这三部分的信息抽取,最终形成了场景层次的信息表征;而在任务抽取层中,我们使用自定义门控网络模块CGC(Customized Gate Control)来对当前场景的多任务学习进行建模。下文将详细介绍上述提到的HiNet模型的关键部分。

场景抽取层的作用是提取场景特有的信息表征和场景间共享的有价值信息表征,这是提高任务层次信息表征能力的基础。在场景抽取层,主要包括场景共享专家网络、场景特有专家网络和场景感知注意力网络三部分,下文将依次进行介绍。
- 场景共享/特有专家网络
考虑到用户跨场景的穿插式行为以及多个场景间商品重叠的现象,到餐业务中多个场景的数据之间存在着有价值的共享信息。因此在策略上,我们设计了场景共享专家网络。这里受到混合专家网络架构MoE(Mixture of Expert)的影响,场景共享专家网络是通过使用子专家集成模块SEI(Sub-Expert Integration module,如图2-©)生成的。
具体来说,场景共享专家网络的最终输出为$G$,其公式为:


- 场景感知注意力网络
如上文所述,不同场景之间存在一定程度的相关性,因此来自其他场景的信息也可以对当前场景的信息表征做出贡献,从而增强当前场景的信息表达能力。考虑到不同场景间对彼此的表征能力贡献不同,我们设计了场景感知注意力网络(Scenario-aware Attentive Network,SAN)来衡量其他场景信息对当前场景信息表征贡献的重要性。具体来说,SAN包含两部分输入:

为了解决多任务学习中的负迁移问题,在任务抽取层,我们受到PLE(Progressive Layered Extraction)模型的启发,采用了自定义门控网络CGC模块。
自定义门控网络
自定义门控网络主要由两部分组成:任务共享专家网络和任务特有专家网络。前者主要负责学习当前场景中所有任务中的共享信息,后者用于提取当前场景中各个任务的特有信息。

2.3 训练目标
我们提出的HiNet的最终损失函数是:

3. 实验
3.1 实验设置
- 数据收集:我们收集了美团到餐平台中的六个场景(场景编号为a到f)的用户日志数据作为我们的多场景多任务训练和评估数据集,其中场景a和b是大场景数据集。相比之下,c到f被作为小场景数据集。

- 评估指标:我们分别考虑每个场景的CTR和CTCVR任务的性能评估,并采用AUC(Area Under ROC Curve)作为多场景多任务数据集的评估指标。
- 模型对比:为了公平地对比我们提出的HiNet模型与业界的SOTA(State-Of-The-Art)模型,我们使用相同条件的实验环境和模型参数量,并对每个模型进行了充分调优和多次实验。具体对比的模型如下:
多任务学习模型:
- Shared Bottom:该模型是一个具有硬参数共享的神经网络模型。
- MMoE:该方法使用灵活的门控网络调整专家网络表示信息,并最终使用塔单元融合每个任务的所有专家网络表示信息。
- PLE:该模型基于MMoE,将专家网络显式划分为任务共享专家和任务特有专家,有效缓解了“跷跷板”现象带来的负迁移问题。
多场景学习模型:
- HMoE:该方法由MMoE改进而来,对多个场景的预测值进行建模,并针对当前场景优化任务预测结果。
- STAR:该方法通过星型拓扑结构构造一个共享的和场景特有的网络,用于学习当前场景的信息表征。
需要指出的是,上述用于对比的模型最初只是为了单纯解决多任务学习或多场景学习的问题而提出的。为了实现公平的实验比较,我们在实验中对相关对比模型做了自适应扩展,以满足多场景多任务建模的需求。
3.2 性能比较

表2展示的是我们在美团到餐平台中六个场景下的各个模型的性能对比。从结果可以看出,我们提出的HiNet模型在所有场景的CTR和CTCVR任务指标上都优于其他对比模型,这证明了HiNet在多场景多任务建模的优势。
3.3 消融研究
为了研究HiNet模型中每个关键组件的效果,我们设计了两个HiNet模型的变体用于消融分析。具体如下:
- HiNet(w/o hierarchy):表示去掉了信息抽取的层级架构,直接采用CGC网络进行多场景多任务学习建模。
- HiNet(w/o SAN):表示的是在场景抽取层中删除SAN模块后的HiNet模型。

从表3的实验结果,我们可以观察到,变体模型HiNet(w/o hierarchy)在所有指标上都有严重的性能下降,这表明分层信息抽取架构可以有效地捕获跨场景的共性和差异,从而提高模型的性能。类似地,在场景抽取层去掉SAN模块后,变体模型HiNet(w/o SAN)在多个场景下性能也有明显的下降,这表明SAN模块学习到的权重信息可以有效地增强场景抽取层的信息表征能力。
3.4 在线A/B测试
为了进一步验证我们提出的HiNet模型的在线性能,我们在美团到餐平台中的场景a和b中部署了HiNet模型,并与基线模型进行了为期一个月的在线A/B测试。

从表4可以看出,HiNet模型在多个场景的CTR和CTCVR指标中均超过了基线模型,并且在订单增益上有显著的提升,这进一步说明了我们提出的HiNet模型的有效性。目前,HiNet模型已经全面部署在上述两个业务中,并为业务的增长做出了一定的贡献。
4. 总结与展望
多场景多任务建模是目前推荐系统中最关键和最具挑战性的问题之一。以往的模型主要通过将所有信息投影到同一个特征空间来优化不同场景下的多个任务,这导致模型性能存在不足。
在本文中,我们提出了层次化信息抽取网络HiNet模型,它利用分层优化架构对多场景多任务问题进行建模。在此基础上,我们在场景抽取层设计了场景感知注意力网络模块SAN来增强场景的表示学习能力。离线和在线A/B测试实验都验证了HiNet模型的优越性。
值得一提的是,目前业界已经出现了大量的图神经网络在推荐模型上的应用。受此启发,在未来的工作中,美团到餐算法团队将图神经网络的信息传递能力结合到多场景多任务学习建模的方案中,继续实践我们的方法,并进一步设计更加完善的模型,来解决在美团到餐平台中存在的复杂的多场景多任务建模问题。
作者简介
周杰、先帅、文豪、薄琳、张琨等,均来自美团到店/平台技术部。
参考文献
- [1] P. Li, R. Li, Q. Da, A.-X. Zeng, and L. Zhang, “Improving multi-scenario learning to rank in e-commerce by exploiting task relationships in the label space,” in Proceedings of the 29th ACM International Conference on * Information & Knowledge Management (CIKM), 2020, pp. 2605–2612.
- [2] X.-R. Sheng, L. Zhao, G. Zhou, X. Ding, B. Dai, Q. Luo, S. Yang, J. Lv, C. Zhang, H. Deng et al., “One model to serve all: Star topology adaptive recommender for multi-domain ctr prediction,” in Proceedings of the 30th * ACM International Conference on Information & Knowledge Management (CIKM), 2021, pp. 4104–4113.
- [3] J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi, “Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,” in Proceedings of the 24th ACM SIGKDD international conference on * knowledge discovery & data mining (SIGKDD), 2018, pp. 1930–1939.
- [4] H. Tang, J. Liu, M. Zhao, and X. Gong, “Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations,” in Proceedings of the 14th ACM Conference on Recommender Systems (RecSys), 2020, pp. 269–278.
- [5] L. Torrey and J. Shavlik, “Transfer learning,” in Handbook of research on machine learning applications and trends: algorithms, methods, and techniques. IGI global, 2010, pp. 242–264.
- [6] S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 10, pp. 1345–1359, 2010.
- [7] F. Zhu, Y. Wang, C. Chen, J. Zhou, L. Li, and G. Liu, “Cross-domain recommendation: challenges, progress, and prospects,” in 30th International Joint Conference on Artificial Intelligence (IJCAI). International Joint * Conferences on Artificial Intelligence, 2021, pp. 4721–4728.
- [8] Y. Zhang and Q. Yang, “A survey on multi-task learning,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- [9] S. Ruder, “An overview of multi-task learning in deep neural networks,” arXiv preprint arXiv:1706.05098, 2017.
- [10] O. Sener and V. Koltun, “Multi-task learning as multi-objective optimization,” in Thirty-second Conference on Neural Information Processing Systems (NeurIPS), 2018.
- [11] C. Rosenbaum, T. Klinger, and M. Riemer, “Routing networks: Adaptive selection of non-linear functions for multi-task learning,” in International Conference on Learning Representations (ICLR), 2018.
- [12] J. Wang, S. C. Hoi, P. Zhao, and Z.-Y. Liu, “Online multi-task collaborative filtering for on-the-fly recommender systems,” in Proceedings of the 7th ACM conference on Recommender systems (RecSys), 2013, pp. 237–244.
- [13] R. Caruana, “Multitask learning,” Machine learning, vol. 28, no. 1, pp. 41–75, 1997.
- [14] K. Weiss, T. M. Khoshgoftaar, and D. Wang, “A survey of transfer learning,” Journal of Big data, vol. 3, no. 1, pp. 1–40, 2016.
- [15] N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” arXiv preprint arXiv:1701.06538, 2017.
- [16] D. Eigen, M. Ranzato, and I. Sutskever, “Learning factored representations in a deep mixture of experts,” Computer Science, 2013.
- [17] M. I. Jordan and R. A. Jacobs, “Hierarchical mixtures of experts and the em algorithm,” Neural computation, vol. 6, no. 2, pp. 181–214, 1994.
- [18] R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,” Neural computation, vol. 3, no. 1, pp. 79–87, 1991.
- [19] S. E. Yuksel, J. N. Wilson, and P. D. Gader, “Twenty years of mixture of experts,” IEEE transactions on neural networks and learning systems, vol. 23, no. 8, pp. 1177–1193, 2012.
- [20] Y. Zhang, C. Li, I. W. Tsang, H. Xu, L. Duan, H. Yin, W. Li, and J. Shao, “Diverse preference augmentation with multiple domains for cold-start recommendations,” in IEEE International Conference on Data Engineering (ICDE), 2022.
如有侵权请联系:admin#unsafe.sh