0x00 前言
在众多企业级应用场景中,GPT 模型具有广泛的实用性。然而,由于 ChatGPT 仅提供在线版本,其应用受到一定限制。近期,笔者通过训练LLaMa,Alpaca、ChatGLM-6B 等众多 10B 以下的小模型,终于找到了一种高效的炼丹方法。
这种方法能够低成本地快速更新模型的知识库,并成功实现预期的对话表现。如下图所示,微调后的ChatGLM6B的模型重新认识了自己:
0x01 环境准备
处理器:推荐使用第 12 代 Intel Core i7 或更高配置 内存:建议 48GB 以上(尽管 16GB 也可以,但加载模型速度较慢) 显卡:推荐使用 NVIDIA GeForce RTX 3080 或更高配置,显存 24GB 以上(8GB 显存也可行,但训练速度慢)
使用nvidia-docker部署最新的pytorch,切记不要使用真实环境,一旦出现包存在问题,导致回滚会非常浪费时间。
检验:依次输入以下命令,查看环境是否部署好:
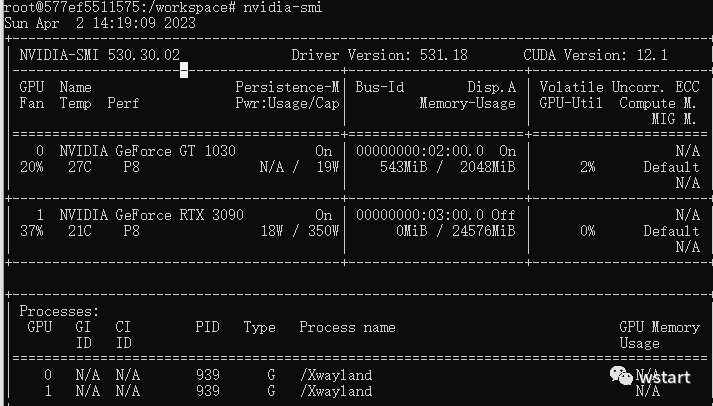
nvidia-smi 查看显卡是否能够正常识别
pytorch 查看显卡是否能够正常识别
0x02 模型准备
创建文件夹 ChatGLM-6B ,把训练脚本中的所有文件放置该目录下。
在ChatGLM-6B 中,创建 thuglm 文件夹,把模型中所有文件下载后放置在ChatGLM-6B/thuglm 中。切记不要下漏文件。
整理后的文件如图所示:
使用 pip 安装依赖:pip install -r requirements.txt,其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。
我们主要采用 cli_demo.py 作为测试训练的交互工具。请编辑修改第 6、7 行代码,将模型路径指向我们刚刚下载的 thuglm。
0x03 训练数据准备
{"summary": "提示词", "content": "期望生成的结果"}
官方提供 train.json 文件的条数是10W条左右
官方提供 dev.json 文件的条数是1000 条左右
备注:
我们的这次训练目的是让模型说出他是微调后的结果,所以json内容基本以这个为主:
{"summary": "你是谁?", "content": "我是wstart通过ChatGLM -6B微调后的模型,训练编号是:0.08376971294904079"}
准备好后如下图,
注:thuglm是ChatGLM-6B/thuglm的原模型文件,为了方便我这里又复制了一遍。
3. 修改训练文件
4. 启动训练
bash train.sh 如果看到下图,即开始训练启动成功:
程序会按照加载模型->加载训练数据->训练->保存到output_dir 4个步骤进行。可以查看自己在哪一个步骤出错,进行修改。
每个人的环境不一样,训练的时间不一样,我这个配置训练的时间是大概7-8个小时走完3000轮的epoch,如果看到loss变化不大后,可以自行调整。
当前的配置是1000轮导出一次模型,可以自行修改。
8个小时后,在ptuning/out/adgen-chatglm-6b-pt-8-1e-2/ 看到训练好的模型,checkpoint-x000 ,一般取最新的。
继续使用 cli_demo.py 作为测试训练的交互工具。编辑修改第 6、7 行代码,将模型路径指向我们刚刚训练好的模型
运行命令 python cli_demo.py,输入你是谁,如下对话出现,说明模型已成功更新知识库。
0x05 局限性
如有侵权请联系:admin#unsafe.sh