之前在看xss的时候老是不知道为什么不同编码,有的会被解析有的不会被解析,所以就想静下来,找个时间把这些基础点理清楚了。毕竟基础是很重要!!!
中途我参考过 http://bobao.360.cn/learning/detail/292.html 讲的很详细了。下面是我自己的总结。
html实体
我是由浅入深的方式来思考的,平时我遇到的比较频繁的就是实体编码,也是最基础的。可以看看下面的这个例子
<div><img src=x onerror=alert(4)></div>
这里对img标签的<>符号进行了"字符值引用"。什么是字符值引用呢?这里简单做个介绍:
字符实体(character entities):
字符实体是一个转义序列,它定义了一般无法在文本内容中输入的单个字符或符号。一个字符实体以一个&符号开始,后面跟着一个预定义的实体的名称,或是一个#符号以及字符的十进制数字。
HTML字符实体(HTML character entities):
因为有些字符浏览器会把他们误以为功能符号,所以对这类字符专门“预留”了。也就是说如果希望这些字符被显示在页面上那么就需要在HTML中使用对应的字符实体。比如:<小于号的实体名称是<实体编号为<
但是有些字符是没有实体名称但是有实体编号的。这里字符值引用就是引用实体编号,对应的字符实体引用为‘<’。字符实体引用也被叫做“实体引用”或“实体”。
那么上面这个代码能正常执行吗?我们放图:

这里可以看到并没有执行成功。那么为什么html不会去执行这个编码呢?
html解析过程中,当遇到第一个'<'或者'>'这类符号后会进入"标签开始状态",然后转变为"标签名状态",接着是"前属性状态",最后到"数据状态"。当解析器解析到"数据状态"时,会继续解析,直到最后结束符号出现。
要说明的一点是,只要当html遇到标签开始状态时,才会去解析下面的内容。这里的标签开始状态是<div>,所以遇到后面的&#符号只是会对其解码但是并不会回到"标签名开始"阶段,所以并不会创立新标签。
那是不是这里如果把<div>标签去掉后,让实体编号作为开始,是不是解码后就到了"标签名开始"阶段呢?
<img src=x onerror=alert(4)>

看来还是没法,我认为是当html解析器将实体解码后,不会返回去判断该字符是否是<>这类"标签名开始"符,所以就依然不能执行成功。
那么如果将特殊字符进行实体编码后就不能绕过让他执行了吗?这个后面讲到javascript解析的时候会说到。
URL解析
开始之前先说明一个点:浏览器在解析HTML文档时无论按照什么顺序,主要有三个过程:HTML解析、JS解析和URL解析,每个解析器负责HTML文档中各自对应部分的解析工作。之前说到的实体编码是html解析范畴。
这里我先贴出一个代码,看看会不会执行:
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29">1</a>//javascript:alert(4)
这里的href是经过url编码的,那么会不会被url解析器解析成javascript:alert(4)呢?

这里可以看到连接并没有解析成javascript:alert(4),仍然是原来的字符串。是不是可能会想URL解码之后Javascript解析器完成解码操作,脚本应该会正常执行啊,这里就有一个URL解析过程中的一个细节了,不能对协议类型进行任何的编码操作,否则URL解析器会认为它无类型,所以不会对它进行url解码。
那么如果我们不把协议编码呢?
<a href="javascript%3aalert(3)">3</a>

依然没有url解析。可以认为该原则对协议后面的“:”(冒号)同样适用。
那如果用下面的例子呢?
<a href="javascript:%61%6c%65%72%74%28%32%29">
这里我先进行实体编码了javascript,然后用url编码了alert(2)。

这里对javascript编码了为什么还能执行呢?
因为"javascript"是做的HTML实体编码,HTML解析器工作时,href里的HTML实体会被解码,"javascript"协议在第一步被HTML解码了,URL解析器开始识别,在这时,“javascript”协议已经被解码,后面的字符串能够被URL解析器正确识别。然后URL解析器继续解析链接剩下的部分。最后由js解析器解析进行弹窗。
那这里为什么html解析器会对href里面进行解码呢?
这里有三种情况html解析器可以容纳字符实体,“数据状态中的字符引用”,“RCDATA状态中的字符引用”和“属性值状态中的字符引用”。在这些状态中HTML字符实体将会从“&#...”形式解码,对应的解码字符会被放入数据缓冲区中。而这里当html解析器碰到<符号后会进入标签开始状态,然后就会遇到herf中的“属性值状态中的字符引用”的情况,对该字符串进行解析。
其次,URL编码过程使用UTF-8编码类型来编码每一个字符。如果你尝试着将URL链接做了其他编码类型的编码,URL解析器就可能不会正确识别。
JavaScript 解析
这里得先说一下,JavaScript语言是一门内容无关语言。所以与html解析会有一些不一样。
先看看这个代码可以执行吗?
<script>alert(9);</script>

{kind=link}
可以看到这里并不会执行,不应该是html解析成alert(9)后然后js执行吗?
这就是js和html解析不一样的地方,所有的“script”块都属于“原始文本”元素。“script”块有个有趣的属性:在块中的字符引用并不会被解析和解码。所以如果攻击者尝试着将输入数据编码成字符实体并将其放在script块中,它将不会被执行。
那么不用实体编码用unicode呢?
Unicode转义序列只有在标识符名称里不被当作字符串,也只有在标识符名称里的编码字符能够被正常的解析。
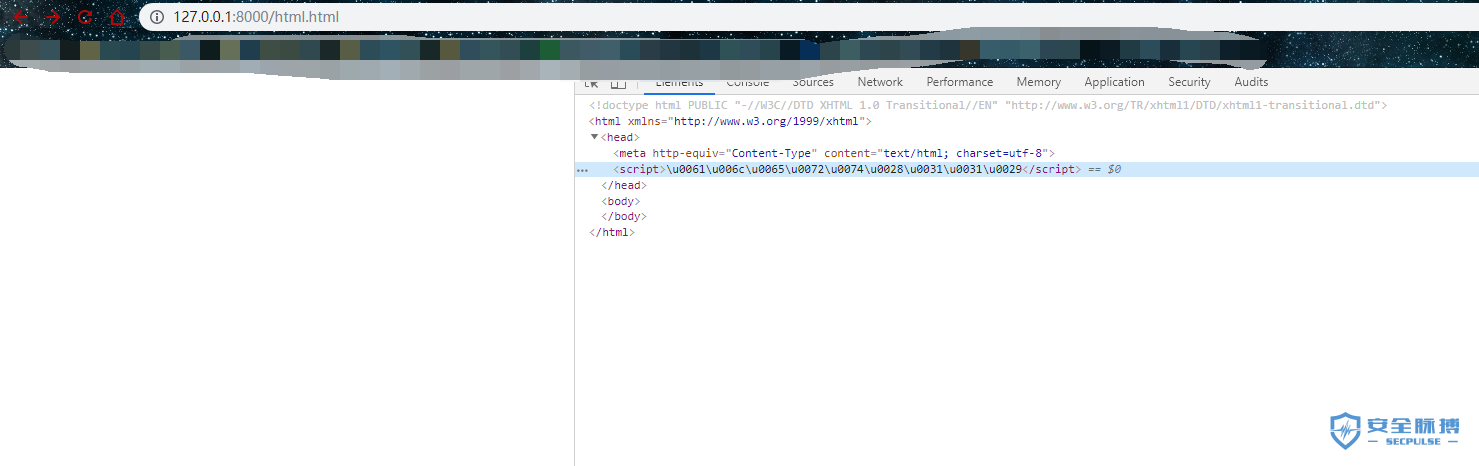
<script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>

这里并没有执行是有两个原因
-
里面对控制字符()进行了编码。但是当js解析控制字符时,例如单引号、双引号、圆括号等等,它们将不会被解释成控制字符,而仅仅被解码并解析为标识符名称或者字符串常量。
-
这里就算被js解析成功也是alert(1)并不是标识符。
所以这里并不会被解析成功。
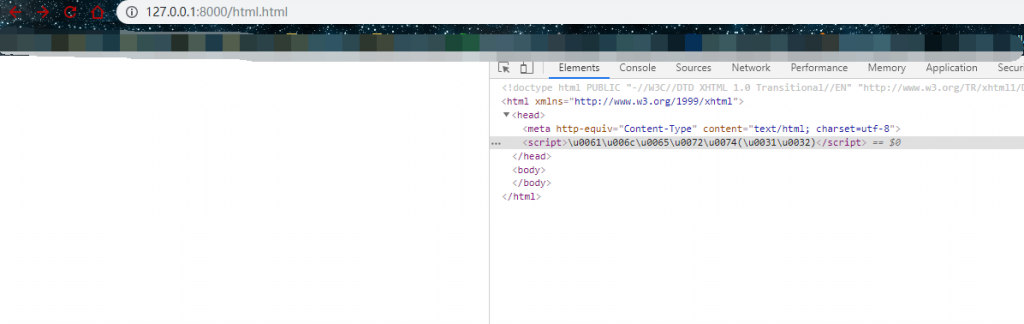
<script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>

这里可以看到虽然()符号没有编码,但是就是因为解码后是非标识符所以也不会被弹窗。
<script>alert('13\u0027)</script>

这里就是因为对控制符进行编码,但是js解析只会把他当做字符常量来处理。所以也不会执行
<script>alert('14\u000a')</script>

这里的\u000a是换行符,但是这里可以看到并没有执行换行的功能,进行了弹窗。
写到这里可能对html基本的html解析,url解析,javascript解析有了一定的初步了解。但是xss攻击千变万化,以上只是作者的个人理解,只有通过不断实战,刷题才能更加熟练,理解的更加深刻。
本文作者:星盟安全团队
本文为安全脉搏专栏作者发布,转载请注明:https://www.secpulse.com/archives/118040.html
如有侵权请联系:admin#unsafe.sh