1. 问题背景和思考
1.1 问题背景
在一次排查线上告警的过程中,突然发现一个链路信息有点不同寻常(这里仅展示测试复现的内容):

在机器中可以清楚的发现“2022-08-02 19:26:34.952 DXMsgRemoteService ”这一行日志信息并没有携带TraceId,导致调用链路信息戛然而止,无法追踪当时的调用情况。
1.2 问题复现和思考
在处理完线上告警后,我们开始分析“丢失”的TraceId到底去了哪里?首先在代码中定位TraceId没有追踪到的部分,发现问题出现在一个@Async注解下的方法,删除无关的业务信息代码,并增加MTrace埋点方法后的复现代码如下:
@SpringBootTest
@RunWith(SpringRunner.class)
@EnableAsync
public class DemoServiceTest extends TestCase {
@Resource
private DemoService demoService;
@Test
public void testTestAsy() {
Tracer.serverRecv("test");
String mainThreadName = Thread.currentThread().getName();
long mainThreadId = Thread.currentThread().getId();
System.out.println("------We got main thread: "+ mainThreadName + " - " + mainThreadId + " Trace Id: " + Tracer.id() + "----------");
demoService.testAsy();
}
}
@Component
public class DemoService {
@Async
public void testAsy(){
String asyThreadName = Thread.currentThread().getName();
long asyThreadId = Thread.currentThread().getId();
System.out.println("======Async====");
System.out.println("------We got asy thread: "+ asyThreadName + " - " + asyThreadId + " Trace Id: " + Tracer.id() + "----------");
}
}
运行这段代码后,我们看看控制台实际的输出结果:
------We got main thread: main - 1 Trace Id: -5292097998940230785----------
======Async====
------We got asy thread: SimpleAsyncTaskExecutor-1 - 630 Trace Id: null----------
至此我们可以发现TraceId是在@Async异步传递的过程中发生丢失现象,明白了造成这一现象的原因后,我们开始思考:
- MTrace(美团内部自研的分布式链路追踪系统)这类分布式链路追踪系统是如何设计的?
- @Async异步方法是如何实现的?
- InheritableThreadLocal、TransmittableThreadLocal和TransmissibleThreadLocal有什么区别?
- 为什么MTrace的跨线程传递方案“失效”了?
- 如何解决@Async场景下“弄丢”TraceId的问题?
- 目前有哪些分布式链路追踪系统?它们又是如何解决跨线程传递问题的?
2. 深度分析
2.1 MTrace与Google Dapper
MTrace是美团参考Google Dapper对服务间调用链信息收集和整理的分布式链路追踪系统,目的是帮助开发人员分析系统各项性能和快速排查告警问题。要想了解MTrace是如何设计分布式链路追踪系统的,首先看看Google Dapper是如何在大型分布式环境下实现分布式链路追踪。我们先来看看下图一个完整的分布式请求:

用户发送一个请求到前端A,然后请求分发到两个不同的中间层服务B和C,服务B在处理完请求后将结果返回,同时服务C需要继续调用后端服务D和E再将处理后的请求结果进行返回,最后由前端A汇总来响应用户的这次请求。
回顾这次完整的请求我们不难发现,要想直观可靠的追踪多项服务的分布式请求,我们最关注的是每组客户端和服务端之间的请求响应以及响应耗时,因此,Google Dapper采取对每一个请求和响应设置标识符和时间戳的方式实现链路追踪,基于这一设计思想的基本追踪树模型如下图所示:

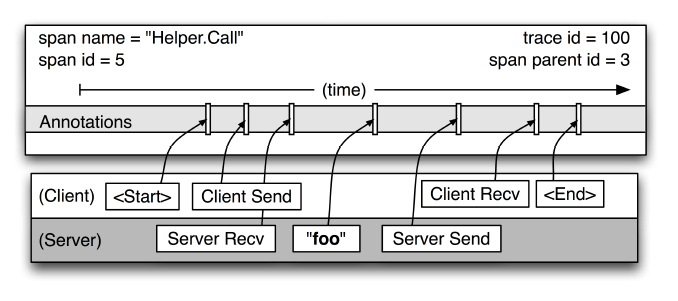
追踪树模型由span组成,其中每个span包含span name、span id、parent id和trace id,进一步分析跟踪树模型中各个span之间的调用关系可以发现,其中没有parent id且span id为1代表根服务调用,span id越小代表服务在调用链的过程中离根服务就越近,将模型中各个相对独立的span联系在一起就构成了一次完整的链路调用记录,我们再继续深入看看span内部的细节信息:

除了最基本的span name、span id和parent id之外,Annotations扮演着重要的角色,Annotations包括<Strat>、Client Send、Server Recv、Server Send、Client Recv和<End>这些注解,记录了RPC请求中Client发送请求到Server的处理响应时间戳信息,其中foo注解代表可以自定义的业务数据,这些也会一并记录到span中,提供给开发人员记录业务信息;在这当中有64位整数构成的trace id作为全局的唯一标识存储在span中。
至此我们已经了解到,Google Dapper主要是在每个请求中配置span信息来实现对分布式系统的追踪,那么又是用什么方式在分布式请求中植入这些追踪信息呢?
为满足低损耗、应用透明和大范围部署的设计目标,Google Dapper支持应用开发者依赖于少量通用组件库,实现几乎零投入的成本对分布式链路进行追踪,当一个服务线程在链路中调用其他服务之前,会在ThreadLocal中保存本次跟踪的上下文信息,主要包括一些轻量级且易复制的信息(类似spand id和trace id),当服务线程收到响应之后,应用开发者可以通过回调函数进行服务信息日志打印。
MTrace是美团参考Google Dapper的设计思路并结合自身业务进行了改进和完善后的自研产品,具体的实现流程这里就不再赘述了,我们重点看看MTrace做了哪些改进:
- 在美团的各个中间件中埋点,来采集发生调用的调用时长和调用结果等信息,埋点的上下文主要包括传递信息、调用信息、机器相关信息和自定义信息,各个调用链路之间有一个全局且唯一的变量TraceId来记录一次完整的调用情况和追踪数据。
- 在网络间的数据传递中,MTrace主要传递使用UUID异或生成的TraceId和表示层级和前后关系的SpanId,支持批量压缩上报、TraceId做聚合和SpanId构建形态。
- 目前,产品已经覆盖到RPC服务、HTTP服务、MySQL、Cache缓存和MQ,基本实现了全覆盖。
- MTrace支持跨线程传递和代理来优化埋点方式,减轻开发人员的使用成本。
2.2 @Async的异步过程追溯
从Spring3开始提供了@Async注解,该注解的使用需要注意以下几点:
- 需要在配置类上增加@EnableAsync注解;
- @Async注解可以标记一个异步执行的方法,也可以用来标记一个类表明该类的所有方法都是异步执行;
- 可以在@Async中自定义执行器。
我们以@EnableAsync为入口开始分析异步过程,除了基本的配置方法外,我们重点关注下配置类AsyncConfigurationSelector的内部逻辑,由于默认条件下我们使用JDK接口代理,这里重点看看ProxyAsyncConfiguration类的代码逻辑:
@Configuration
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public class ProxyAsyncConfiguration extends AbstractAsyncConfiguration {
@Bean(name = TaskManagementConfigUtils.ASYNC_ANNOTATION_PROCESSOR_BEAN_NAME)
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public AsyncAnnotationBeanPostProcessor asyncAdvisor() {
Assert.notNull(this.enableAsync, "@EnableAsync annotation metadata was not injected");
//新建一个异步注解bean后置处理器
AsyncAnnotationBeanPostProcessor bpp = new AsyncAnnotationBeanPostProcessor();
//如果@EnableAsync注解中有自定义annotation配置则进行设置
Class<? extends Annotation> customAsyncAnnotation = this.enableAsync.getClass("annotation");
if (customAsyncAnnotation != AnnotationUtils.getDefaultValue(EnableAsync.class, "annotation")) {
bpp.setAsyncAnnotationType(customAsyncAnnotation);
}
if (this.executor != null) {
//设置线程处理器
bpp.setExecutor(this.executor);
}
if (this.exceptionHandler != null) {
//设置异常处理器
bpp.setExceptionHandler(this.exceptionHandler);
}
//设置是否需要创建CGLIB子类代理,默认为false
bpp.setProxyTargetClass(this.enableAsync.getBoolean("proxyTargetClass"));
//设置异步注解bean处理器应该遵循的执行顺序,默认最低的优先级
bpp.setOrder(this.enableAsync.<Integer>getNumber("order"));
return bpp;
}
}
ProxyAsyncConfiguration继承了父类AbstractAsyncConfiguration的方法,重点定义了一个AsyncAnnotationBeanPostProcessor的异步注解bean后置处理器。看到这里我们可以知道,@Async主要是通过后置处理器生成一个代理对象来实现异步的执行逻辑,接下来我们重点关注AsyncAnnotationBeanPostProcessor是如何实现异步的:

从类图中我们可以直观地看到AsyncAnnotationBeanPostProcessor同时实现了BeanFactoryAware的接口,因此我们进入setBeanFactory()方法,可以看到对AsyncAnnotationAdvisor异步注解切面进行了构造,再接着进入AsyncAnnotationAdvisor的buildAdvice()方法中可以看AsyncExecutionInterceptor类,再看类图发现AsyncExecutionInterceptor实现了MethodInterceptor接口,而MethodInterceptor是AOP中切入点的处理器,对于interceptor类型的对象,处理器中最终被调用的是invoke方法,所以我们重点看看invoke的代码逻辑:
public Object invoke(final MethodInvocation invocation) throws Throwable {
Class<?> targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null);
Method specificMethod = ClassUtils.getMostSpecificMethod(invocation.getMethod(), targetClass);
final Method userDeclaredMethod = BridgeMethodResolver.findBridgedMethod(specificMethod);
//首先获取到一个线程池
AsyncTaskExecutor executor = determineAsyncExecutor(userDeclaredMethod);
if (executor == null) {
throw new IllegalStateException("No executor specified and no default executor set on AsyncExecutionInterceptor either");
}
//封装Callable对象到线程池执行
Callable<Object> task = () -> {
try {
Object result = invocation.proceed();
if (result instanceof Future) {
return ((Future<?>) result).get();
}
}
catch (ExecutionException ex) {
handleError(ex.getCause(), userDeclaredMethod, invocation.getArguments());
}
catch (Throwable ex) {
handleError(ex, userDeclaredMethod, invocation.getArguments());
}
return null;
};
//任务提交到线程池
return doSubmit(task, executor, invocation.getMethod().getReturnType());
}
我们再接着看看@Async用了什么线程池,重点关注determineAsyncExecutor方法中getExecutorQualifier指定获取的默认线程池是哪一个:
@Override
@Nullable
protected Executor getDefaultExecutor(@Nullable BeanFactory beanFactory) {
Executor defaultExecutor = super.getDefaultExecutor(beanFactory);
return (defaultExecutor != null ? defaultExecutor : new SimpleAsyncTaskExecutor()); //其中默认线程池是SimpleAsyncTaskExecutor
}
至此,我们了解到在未指定线程池的情况下调用被标记为@Async的方法时,Spring会自动创建SimpleAsyncTaskExecutor线程池来执行该方法,从而完成异步执行过程。
2.3. “丢失”TraceId的原因
回顾我们之前对MTrace的学习和了解,TraceId等信息是在ThreadLocal中进行传递和保存,那么当异步方法切换线程的时候,就会出现下图中上下文信息传递丢失的问题:

下面我们探究一下ThreadLocal有哪些跨线程传递方案?MTrace又提供哪些跨线程传递方案?SimpleAsyncTaskExecutor又有什么不一样?逐步找到“丢失”TraceId的原因。
2.3.1 InheritableThreadLocal、TransmittableThreadLocal和TransmissibleThreadLocal
在前面的分析中,我们发现跨线程场景下上下文信息是保存在ThreadLocal中发生丢失,那么我们接下来看看ThreadLocal的特点及其延伸出来的类,是否可以解决这一问题:
- ThreadLocal主要是为每个ThreadLocal对象创建一个ThreadLocalMap来保存对象和线程中的值的映射关系。当创建一个ThreadLocal对象时会调用get()或set()方法,在当前线程的中查找这个ThreadLocal对象对应的Entry对象,如果存在,就获取或设置Entry中的值;否则,在ThreadLocalMap中创建一个新的Entry对象。ThreadLocal类的实例被多个线程共享,每个线程都拥有自己的ThreadLocalMap对象,存储着自己线程中的所有ThreadLocal对象的键值对。ThreadLocal的实现比较简单,但需要注意的是,如果使用不当,可能会出现内存泄漏问题,因为ThreadLocalMap中的Entry对象并不会自动删除。
- InheritableThreadLocal的实现方式和ThreadLocal类似,但不同之处在于,当一个线程创建子线程时会调用init()方法:
private void init(ThreadGroup g, Runnable target, String name,long stackSize, AccessControlContext acc,Boolean inheritThreadLocals) {
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
//拷贝父线程的变量
this.inheritableThreadLocals =ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
this.stackSize = stackSize;
tid = nextThreadID();
}
这意味着子线程可以访问父线程中的InheritableThreadLocal实例,而且在子线程中调用set()方法时,会在子线程自己的inheritableThreadLocals字段中创建一个新的Entry对象,而不会影响父线程中的Entry对象。同时,根据源码我们也可以看到Thread的init()方法是在线程构造方法中拷贝的,在线程复用的线程池中是没有办法使用的。
- TransmittableThreadLocal是阿里巴巴提供的解决跨线程传递上下文的InheritableThreadLocal子类,引入了holder来保存需要在线程间进行传递的变量,大致流程我们可以参考下面给出的时序图分析:

步骤可以总结为:① 装饰Runnable,将主线程的TTL传入到TtlRunnable的构造方法中;② 将子线程的TTL的值进行备份,将主线程的TTL设置到子线程中(value是对象引用,可能存在线程安全问题);③ 执行子线程逻辑;④ 删除子线程新增的TTL,将备份还原重新设置到子线程的TTL中,从而保证了ThreadLocal的值在多线程环境下的传递性。
TransmittableThreadLocal虽然解决了InheritableThreadLocal的继承问题,但是由于需要在序列化和反序列化时对ThreadLocalMap进行处理,会增加对象创建和序列化的成本,并且需要支持的序列化框架较少,不够灵活。
- TransmissibleThreadLocal是继承了InheritableThreadLocal类并重写了get()、set()和remove()方法,TransmissibleThreadLocal的实现方式和TransmittableThreadLocal类似,主要的执行逻辑在Transmitter的capture()方法复制holder中的变量,replay()方法过滤非父线程的holder的变量,restore()来恢复经过replay()过滤后holder的变量:
public class TransmissibleThreadLocal<T> extends InheritableThreadLocal<T> {
public static class Transmitter {
public static Object capture() {
Map<TransmissibleThreadLocal<?>, Object> captured = new HashMap<TransmissibleThreadLocal<?>, Object>();
//获取所有存储在holder中的变量
for (TransmissibleThreadLocal<?> threadLocal : holder.get().keySet()) {
captured.put(threadLocal, threadLocal.copyValue());
}
return captured;
}
public static Object replay(Object captured) {
@SuppressWarnings("unchecked")
Map<TransmissibleThreadLocal<?>, Object> capturedMap = (Map<TransmissibleThreadLocal<?>, Object>) captured;
Map<TransmissibleThreadLocal<?>, Object> backup = new HashMap<TransmissibleThreadLocal<?>, Object>();
for (Iterator<? extends Map.Entry<TransmissibleThreadLocal<?>, ?>> iterator = holder.get().entrySet().iterator();iterator.hasNext(); ) {
Map.Entry<TransmissibleThreadLocal<?>, ?> next = iterator.next();
TransmissibleThreadLocal<?> threadLocal = next.getKey();
// backup
backup.put(threadLocal, threadLocal.get());
// clear the TTL value only in captured
// avoid extra TTL value in captured, when run task.
//过滤非传递的变量
if (!capturedMap.containsKey(threadLocal)) {
iterator.remove();
threadLocal.superRemove();
}
}
// set value to captured TTL
for (Map.Entry<TransmissibleThreadLocal<?>, Object> entry : capturedMap.entrySet()) {
@SuppressWarnings("unchecked")
TransmissibleThreadLocal<Object> threadLocal = (TransmissibleThreadLocal<Object>) entry.getKey();
threadLocal.set(entry.getValue());
}
// call beforeExecute callback
doExecuteCallback(true);
return backup;
}
public static void restore(Object backup) {
@SuppressWarnings("unchecked")
Map<TransmissibleThreadLocal<?>, Object> backupMap = (Map<TransmissibleThreadLocal<?>, Object>) backup;
// call afterExecute callback
doExecuteCallback(false);
for (Iterator<? extends Map.Entry<TransmissibleThreadLocal<?>, ?>> iterator = holder.get().entrySet().iterator();
iterator.hasNext(); ) {
Map.Entry<TransmissibleThreadLocal<?>, ?> next = iterator.next();
TransmissibleThreadLocal<?> threadLocal = next.getKey();
// clear the TTL value only in backup
// avoid the extra value of backup after restore
if (!backupMap.containsKey(threadLocal)) {
iterator.remove();
threadLocal.superRemove();
}
}
// restore TTL value
for (Map.Entry<TransmissibleThreadLocal<?>, Object> entry : backupMap.entrySet()) {
@SuppressWarnings("unchecked")
TransmissibleThreadLocal<Object> threadLocal = (TransmissibleThreadLocal<Object>) entry.getKey();
threadLocal.set(entry.getValue());
}
}
}
}
TransmissibleThreadLocal不但可以解决跨线程的传递问题,还能保证子线程和主线程之间的隔离,但是目前跨线程拷贝span数据时,采用浅拷贝有丢失数据的风险。最后,我们可以根据下表综合对比:

考虑到TransmittableThreadLocal并非标准的Java API,而是第三方库提供的,存在与其它库的兼容性问题,无形中增加了代码的复杂性和使用难度。因此,MTrace选择自定义实现的TransmissibleThreadLocal类可以方便地在跨线程和跨服务的情况下传递追踪信息,透明自动完成所有异步执行上下文的可定制、规范化的捕捉传递,使得整个跟踪信息更加完整和准确。
2.3.2 Mtrace的跨线程传递方案
这一问题MTrace其实已经提供解决方案,主要的设计思路是在子线程初始化Runnable对象的时候首先会去父线程的ThreadLocal中拿到保存的trace信息,然后作为参数传递给子线程,子线程在初始化的时候设置trace信息来避免丢失。下面我们看看具体实现。
父线程新建任务时捕捉所有TransmissibleThreadLocal中的变量信息,如下图所示:

子线程执行任务时复制父线程捕捉的TransmissibleThreadLocal变量信息,并返回备份的TransmissibleThreadLocal变量信息,如下图所示:

在子线程执行完业务流程后会恢复之前备份的TransmissibleThreadLocal变量信息,如下图所示:

这种方案可以解决跨线程传递上下文丢失的问题,但是需要代码层面的开发会增加开发人员的工作量,对于一个分布式追踪系统而言并不是最优解:
TraceRunnable command = new TraceRunnable(runnable);
newThread(command).start();
executorService.execute(command);
因此,MTrace同时提供无侵入方式的javaagent&instrument技术,可以简单理解成一个类加载时的AOP功能,只要在JVM参数添加javaagent的配置,不需要修饰Runnable或是线程池的代码,就可以在启动时增强完成跨线程传递问题。
回归到本次的问题中来,目前使用的MDP本身就已经集成了MTrace-agent的模式,但是为什么还是会“弄丢”TraceId呢?查看MTrace的ThreadPoolTransformer类和ForkJoinPoolTransformer类我们可以知道,MTrace修改了ThreadPoolExecutor类、ScheduledThreadPoolExecutor类和ForkJoinTask类的字节码,顺着这个思路我们再看看@Async用到的SimpleAsyncTaskExecutor线程池是怎么一回事。
2.3.3 SimpleAsyncTaskExecutor是怎么一回事
我们先深入SimpleAsyncTaskExecutor的代码中,看看执行逻辑:
public class SimpleAsyncTaskExecutor extends CustomizableThreadCreator implements AsyncListenableTaskExecutor, Serializable {
private ThreadFactory threadFactory;
public void execute(Runnable task, long startTimeout) {
Assert.notNull(task, "Runnable must not be null");
//isThrottleActive是否开启限流(默认concurrencyLimit=-1,不开启限流)
if(this.isThrottleActive() && startTimeout > 0L) {
this.concurrencyThrottle.beforeAccess();
this.doExecute(new SimpleAsyncTaskExecutor.ConcurrencyThrottlingRunnable(task));
this.concurrencyThrottle.beforeAccess();
this.doExecute(new SimpleAsyncTaskExecutor.ConcurrencyThrottlingRunnable(task));
this.concurrencyThrottle.beforeAccess();
this.doExecute(new SimpleAsyncTaskExecutor.ConcurrencyThrottlingRunnable(task));
} else {
this.doExecute(task);
}
}
protected void doExecute(Runnable task) {
//没有线程工厂的话默认创建线程
Thread thread = this.threadFactory != null?this.threadFactory.newThread(task):this.createThread(task);
thread.start();
}
public Thread createThread(Runnable runnable) {
//和线程池不同,每次都是创建新的线程
Thread thread = new Thread(getThreadGroup(), runnable, nextThreadName());
thread.setPriority(getThreadPriority());
thread.setDaemon(isDaemon());
return thread;
}
}
看到这里我们可以得出以下几个特性:
- SimpleAsyncTaskExecutor每次执行提交给它的任务时,会启动新的线程,并不是严格意义上的线程池,达不到线程复用的功能。
- 允许开发者控制并发线程的上限(concurrencyLimit)起到一定的资源节流作用,但默认concurrencyLimit取值为-1,即不启用资源节流,有引发内存泄漏的风险。
- 阿里技术编码规约要求用ThreadPoolExecutor的方式来创建线程池,规避资源耗尽的风险。
结合之前说过的MTrace线程池代理模型,我们继续再来看看SimpleAsyncTaskExecutor的类图:

可以发现,其继承了spring的TaskExecutor接口,其实质是java.util.concurrent.Executor,结合我们这次“丢失”的TraceId问题来看,我们已经找到了Mtrace的跨线程传递方案“失效”的原因:虽然MTrace已经通过javaagent&instrument技术可以完成Trace信息跨线程传递,但是目前只覆盖到ThreadPoolExecutor类、ScheduledThreadPoolExecutor类和ForkJoinTask类的字节码,而@Async在未指定线程池的情况下默认会启用SimpleAsyncTaskExecutor,其本质是java.util.concurrent.Executor没有被覆盖到,就会造成ThreadLocal中的get方法获取信息为空,导致最终TraceId传递丢失。
3. 解决方案
实际上@Async支持我们使用自定义的线程池,可以手动自定义Configuration来配置ThreadPoolExecutor线程池,然后在注解里面指定bean的名称,就可以切换到对应的线程池去,可以看看下面的代码:
@Configuration
public class ThreadPoolConfig {
@Bean("taskExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
//设置线程池参数信息
taskExecutor.setCorePoolSize(10);
taskExecutor.setMaxPoolSize(50);
taskExecutor.setQueueCapacity(200);
taskExecutor.setKeepAliveSeconds(60);
taskExecutor.setThreadNamePrefix("myExecutor--");
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
taskExecutor.initialize();
return taskExecutor;
}
}
然后在注解中标注这个线程池:
@SpringBootTest
@RunWith(SpringRunner.class)
@EnableAsync
public class DemoServiceTest extends TestCase {
@Resource
private DemoService demoService;
@Test
public void testTestAsy() {
Tracer.serverRecv("test");
String mainThreadName = Thread.currentThread().getName();
long mainThreadId = Thread.currentThread().getId();
System.out.println("------We got main thread: "+ mainThreadName + " - " + mainThreadId + " Trace Id: " + Tracer.id() + "----------");
demoService.testAsy();
}
}
@Component
public class DemoService {
@Async("taskExecutor")
public void testAsy(){
String asyThreadName = Thread.currentThread().getName();
long asyThreadId = Thread.currentThread().getId();
System.out.println("======Async====");
System.out.println("------We got asy thread: "+ asyThreadName + " - " + asyThreadId + " Trace Id: " + Tracer.id() + "----------");
}
}
看看输出台的打印:
------We got main thread: main - 1 Trace Id: -3495543588231940494----------
======Async====
------We got asy thread: SimpleAsyncTaskExecutor-1 - 658 Trace Id: 3495543588231940494----------
最终,我们可以通过这一方式“找回”在@Async注解下跨线程传递而“丢失”的TraceId。
4. 其他方案对比
分布式追踪系统从诞生之际到有实质性的突破,很大程度受到Google Dapper的影响,目前常见的分布式追踪系统有Twitter的Zipkin、SkyWalking、阿里的EagleEye、PinPoint和美团的MTrace等,这些大多都是基于Google Dapper的设计思想,考虑到设计思路和架构特点,我们重点介绍Zipkin、SkyWalking和EagleEye的基本框架和跨线程解决方案(以下内容主要来源官网及作者总结,仅供参考,不构成技术建议)。
4.1 Zipkin
Zipkin是由Twitter公司贡献开发的一款开源的分布式追踪系统,官方提供有基于Finagle框架(Scala语言)的接口,而其他框架的接口由社区贡献,目前可以支持Java、Python、Ruby和C#等主流开发语言和框架,其主要功能是聚集来自各个异构系统的实时监控数据。主要由4个核心组件构成,如下图所示:

- Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin内部处理的Span格式,以支持后续的存储、分析、展示等功能。
- Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储起来,同时支持修改存储策略。
- API:API组件,它主要用来提供外部访问接口,比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
- UI:UI组件,基于API组件实现的上层应用,通过UI组件用户可以方便而有直观地查询和分析跟踪信息。
当用户发起一次调用的时候,Zipkin的客户端会在入口处先记录这次请求相关的trace信息,然后在调用链路上传递trace信息并执行实际的业务流程,为防止追踪系统发送延迟与发送失败导致用户系统的延迟与中断,采用异步的方式发送trace信息给Zipkin Collector,Zipkin Server在收到trace信息后,将其存储起来。随后Zipkin的Web UI会通过 API访问的方式从存储中将trace信息提取出来分析并展示。

最后,我们看看Zipkin的跨线程传递方案的优缺点:在单个线程的调用中Zipkin通过定义一个ThreadLocal<TraceContext> local来完成在整个线程执行过程中获取相同的Trace值,但是当新起一个线程的时候ThreadLocal就会失效,对于这种场景,Zipkin对于不提交线程池的场景提供InheritableThreadLocal<TraceContext>来解决父子线程trace信息传递丢失的问题。
而对于@Async的使用场景,Zipkin提供CurrentTraceContext类首先获取父线程的trace信息,然后将trace信息复制到子线程来,其基本思路和上文MTrace的一致,但是需要代码开发,具有较强的侵入性。
4.2 SkyWalking
SkyWalking是Apache基金会下面的一个开源的应用程序性能监控系统,提供了一种简便的方式来清晰地观测云原生和基于容器的分布式系统。具有支持多种语言探针;微内核+插件的架构;存储、集群管理和使用插件集合都可以自由选择;支持告警;优秀的可视化效果的特点。其主要由4个核心组件构成,如下图所示:

- 探针:基于不同的来源可能是不一样的,但作用都是收集数据,将数据格式化为 SkyWalking适用的格式。
- 平台后端:支持数据聚合,数据分析以及驱动数据流从探针到用户界面的流程。分析包括Skywalking原生追踪和性能指标以及第三方来源,包括Istio、Envoy telemetry、Zipkin追踪格式化等。
- 存储:通过开放的插件化的接口存放SkyWalking数据。用户可以选择一个既有的存储系统,如ElasticSearch、H2或MySQL集群(Sharding-Sphere管理),也可以指定选择实现一个存储系统。
- UI :一个基于接口高度定制化的Web系统,用户可以可视化查看和管理SkyWalking数据。
SkyWalking的工作原理和Zipkin类似,但是相比较于Zipkin接入系统的方式,SkyWalking使用了插件化+javaagent 的形式来实现:通过虚拟机提供的用于修改代码的接口来动态加入打点的代码,如通过javaagent premain来修改Java 类,在系统运行时操作代码,让用户可以在不需要修改代码的情况下进行链路追踪,对业务的代码无侵入性,同时使用字节码操作技术(Byte-Buddy)和AOP概念来实现拦截追踪上下文的trace信息,这样一来每个用户只需要根据自己的需用定义拦截点,就可以实现对一些模块实施分布式追踪。

最后,我们总结一下SkyWalking的跨线程传递方案的优缺点:和主流的分布式追踪系统类似,SkyWalking也是借助ThreadLocal来存储上下文信息,当遇到跨线程传输时也面临传递丢失的场景,针对这一问题SkyWalking会在父线程调用ContextManager.capture()将trace信息保存到一个ContextSnapshot的实例中并返回,ContextSnapshott则被附加到任务对象的特定属性中,那么当子线程处理任务对象的时会先取出ContextSnapshott对象,将其作为入参调用ContextManager.continued(contextSnapshot)来保存到子线程中。
整体思路其实和主流的分布式追踪系统的相似,SkyWalking目前只针对带有@TraceCrossThread注解的Callable、Runnable和Supplier这三种接口的实现类进行增强拦截,通过使用xxxWrapper.of的包装方式,避免开发者需要大的代码改动。
4.3 EagleEye
EagleEye阿里巴巴开源的应用性能监控工具,提供了多维度、实时、自动化的应用性能监控和分析能力。它可以帮助开发人员实时监控应用程序的性能指标、日志、异常信息等,并提供相应的性能分析和报告,帮助开发人员快速定位和解决问题。主要由以下5部分组成:

- 代理:代理是鹰眼的数据采集组件,通过代理可以采集应用程序的性能指标、日志、异常信息等数据,并将其传输到鹰眼的存储和分析组件中。代理支持多种协议,如HTTP、Dubbo、RocketMQ、Kafka等,能够满足不同场景下的数据采集需求。
- 存储:存储是鹰眼的数据存储组件,负责存储代理采集的数据,并提供高可用、高性能、高可靠的数据存储服务。存储支持多种存储引擎,如HBase、Elasticsearch、TiDB等,可以根据实际情况进行选择和配置。
- 分析:分析是鹰眼的数据分析组件,负责对代理采集的数据进行实时分析和处理,并生成相应的监控指标和性能报告。分析支持多种分析引擎,如Apache Flink、Apache Spark等,可以根据实际情况进行选择和配置。
- 可视化:可视化是鹰眼的数据展示组件,负责将分析产生的监控指标和性能报告以图形化的方式展示出来,以便用户能够直观地了解系统的运行状态和性能指标。
- 告警:告警是鹰眼的告警组件,负责根据用户的配置进行异常检测和告警,及时发现和处理系统的异常情况,防止系统出现故障。
不同于SkyWalking的开源社区,EagleEye重点面向阿里内部环境开发,针对海量实时监控的痛点,对底层的流计算、多维时序指标与交互体系等进行了大量优化,同时引入了时序检测、根因分析、业务链路特征等技术,将问题发现与定位由被动转为主动。
EagleEye采用了StreamLib实时流式处理技术提升流计算性能,对采集的数据进行实时分析和处理,当监控一个电商网站时,可以实时地分析用户访问的日志数据,并根据分析结果来优化网站的性能和用户体验;参考Apache Flink的Snapshot优化齐全度算法来保证监控系统确定性;为了满足不同的个性化需求,把一些可复用的逻辑变成了“积木块”,让用户按照自己的需求,拼装流计算的pipeline。

最后总结一下EagleEye的跨线程传递方案优缺点:EagleEye的解决思路和大多数分布式追踪系统一致,都是通过javaagent的方式修改线程池的实现,进而子线程可以获取到父线程到trace信息,不同于SkyWalking这种开源系统采用的字节码增强,EagleEye大多数场景是内部使用,所以采用直接编码的方式,维护和性能消耗方面也是非常有优势的,但扩展性和开放性并不是非常友好。
5. 总结
本文意在从日常工作中一个很细微的问题出发,探究分析背后的设计思想和底层原因,主要涉及以下方面:
- 抓住问题本质:在业务系统报警中抓住问题的核心代码并尝试再次复现问题,找到真正出问题的模块。
- 深入理解设计思想:在查阅公司中间件的产品文档的基础上再继续追根溯源,学习业内领先者最开始的分布式链路追踪系统的设计思想和实现途径。
- 结合实际问题提出疑问:结合了解到的分布式链路追踪系统的实现流程和设计思想,回归到一开始我们要解决的TraceId丢失情况分析是在什么环节出现问题。
- 阅读源码找到底层逻辑:从@Async注解、SimpleAsyncTaskExecutor和ThreadLocal类源码进行层层追踪,分析底层真正的实现逻辑和特点。
- 对比分析找到解决方案:分析为什么Mtrace的跨线程传递方案“失效”了,找到原因提供解决方案并总结其他分布式追踪系统。
从本文可以看出,中间件的出现不仅为我们维护系统的稳定提供有力的支持,还已经为使用中可能发生的问题提供了更高效的解决方案,作为开发人员在享受这一极大便利的同时,还是要沉下心来认真思考其中的实现逻辑和使用场景,如果只是一味的低头使用不求甚解,那么在一些特定问题上往往会显得十分被动,无法发挥中间件真正的价值,甚至在没有中间件支撑时无法高效的解决问题。
本文作者
李祯,美团到店事业群/充电宝业务部工程师。
参考资料
如有侵权请联系:admin#unsafe.sh