
为什么没有完美的程序分析工具
日期:2023年04月21日 阅:114
笔者这些年走访了很多客户,在试用交流过程中,有些客户能够理解代码分析一定存在误漏报。但有些客户很难理解代码分析为什么在不断的改进下还存在误漏报,甚至抱怨我们研发测试不够专业认真,不能穷尽所有的可能性。这篇文章,笔者主要想简单讲一讲为什么程序分析一定具有局限性的,也就是一定会存在误漏报。
程序分析的局限性无处不在
在可计算理论中,所有的程序都需要遵循赖斯定理(Rice’s Theorem)即
- 程序的所有非平凡(non-trivial)语义属性都是不可判定的。(All non-trivial, semantic properties of programs are undecidable.)
这个定理意味着所有的程序分析工具(即用程序去判断程序的自身属性的范畴内),无论SAST、IAST还是DAST都无法做到针对程序的非平凡属性都能产生YES或NO的输出。理论上说,即使程序的基本属性,也是无法判定的,例如:给定的程序是否存在无限循环。更不要说我们去判断程序的缺陷属性。换个具体的说法:我们不可能编写一段程序正确且全部(soundness and completeness)检查给定程序是否存在XX类型的缺陷。
原因是什么呢?
莱斯定理在丘奇和图灵的基础上改进了哥德尔(Kurt Gödel) 在 1930 年的定理,证明了停机问题的不可解性和不完备性定理。在此之前哥德尔证明了形式化公理系统(例如集合论或数论)是存在局限性。篇幅有限只给结论,即:
- 我们无法构建一台机器来解决给定输入的程序最终是否停止的问题。(We can’t build a machine that solves the problem of whether a program with a given input eventually stops or not.)

Kurt Gödel
因此,当我们都无法确定在给定输入下程序是否停止时,我们怎样才能编写不存在误漏报的程序分析工具呢?至少现有的理论是无法做到既可靠又完备的。
上述结论的衍生:可达性验证的不确定性
我们首先用一个例子来说明我们要讨论的内容。假设我们有以下目标程序:
void foo(string name) {
string message= “Welcome”
if(name is not Empty) {
message.Append(“, ” + name)
myLabel.SetText(message)
}
}
foo获取用户提供的名称输入。如果名称不为空,代码会将其附加到硬编码消息中,并通过名为myLabel的标签将其返回给用户。这是一个由上述代码块构建的简单 CFG;

程序的CFG表达
检测跨站脚本 (XSS) 漏洞的基本思路是source点和sink点之间是否存在某条可达路径?在上面的示例中,source点函数的入口包含用户提供的输入,sink点setText包含可能导致 XSS 的方法。下面一节我们将证明,不可能创建一个算法可以回答在给定程序下的可达性问题。
反证法-无法创建一个程序可以进行可达性的判定
首先,我们假设可以编写这样一个程序来回答任何给定程序的任何两个节点的可达性问题。我们称之为 R:
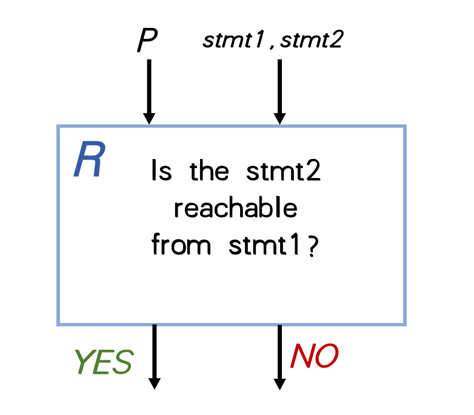
在程序R中,P 是输入程序, 输入的另两个参数是stmt1和stmt2。如果 stmt2 可从 stmt1 到达,则 R 输出 YES,否则输出 NO。
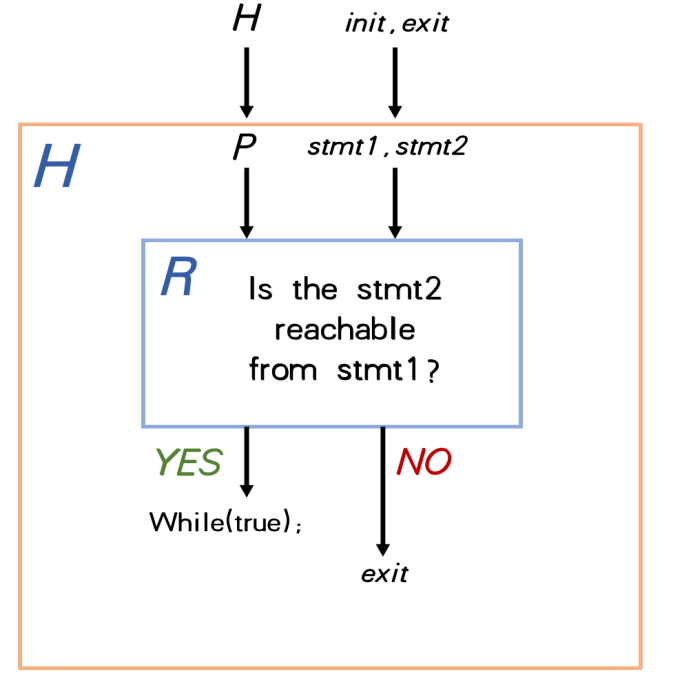
我们创造一个新的程序,即对R 的进行扩展,称为 H。该程序采用相同的输入参数并内部包含程序R。当它看到输出是YES时,我们在H中添加一个while(true)无限循环语句,这使 H 永远不会退出。相反,当我们看到R输出 NO 时,我们使用 exit 语句退出应用程序。现在,我们的 H 中有一个初始语句称之为init和一个名为exit的返回语句
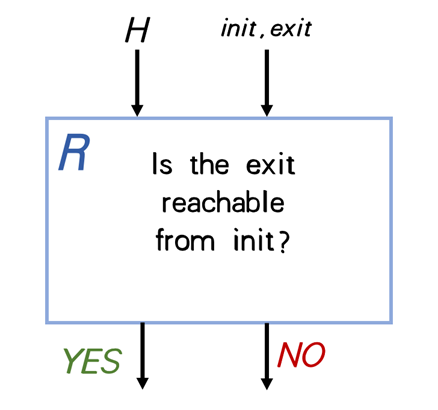
当我们将 H 作为目标程序提供给R 并将 (init,exit) 语句元组作为输入时,会发生什么?
- 假如 init能够到达exit,R 输出 YES,H 将永远循环。所以程序没法产生正确输出。
- 假如 init不能够到达exit, R 输出 NO,H 将退出。所以程序同样没法产生正确输出。
这意味着 R 是不可能存在的。即我们不能编写一个程序来回答任何程序及其任何两个语句的语句可达性问题,由此我们只是近似求解。正如哥德尔定理所述:
- 任何产生关于算术陈述的算法要么产生错误陈述,要么永远不会产生关于算术的真实陈述。(Any algorithm that produces statements about arithmetic either sometimes produces false statements, or else there are true statements about arithmetic that it never produces.)
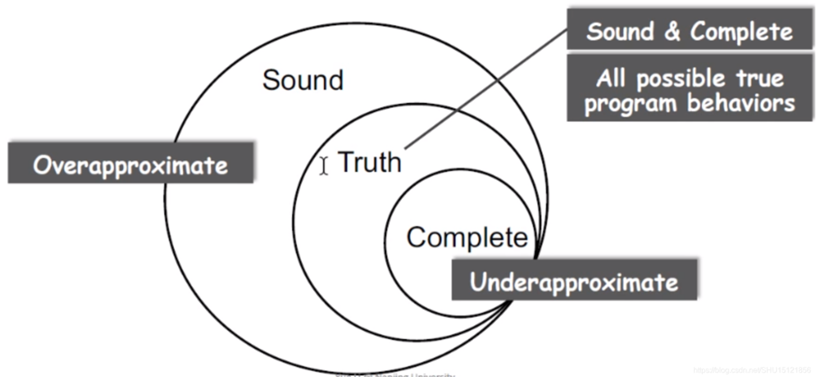
由于,现代计算机只不过是具有有限内存的高速图灵机。所以,任何程序分析工具一定会产生一些误报或漏报。我们最好的做法就是不断逼近。本质上就是是近似求解。工具对执行流程、攻击行为、系统设置、软件API、输入组合、时间等做出预设或剪枝。作为工具的用户,在接受以上假设的基础上,只要报出来的问题看起来不太傻或误报少即可。上篇文章中提到的敏感性就是程序逼近程度的衡量方式,有兴趣的同学可以复习一下。
结论
有时候,我们都会听到程序工具各种夸大宣传,例如“零误报”或报出“所有漏洞”,“结合了白盒和黑盒的技术优势是一种更完美的方法”云云。然而,任何算法理论上一定是不完备的。“逼近”算法的优劣取决于算法本身,这也是程序分析工具的技术门槛,对于研发人员的算法能力要求比较高。
此外,在选择程序分析工具时有许多标准需要考虑,最重要的事情就是尽可能减少误漏报。为此,最好的方法是利用基准测试集来测试工具的能力,以证明程序“逼近”能力。在前面的文章中,我们提到了评价静态分析工具重要的标准就是敏感度,也就是衡量“逼近”程度的指标。为了度量这个指标,最好的办法就是采用一组以敏感度作为基本维度的测试集来进行对比测试。在国际上比较流行的测试集包括NIST的Juliet或OWASPJava都是以安全漏洞模式的角度去分类,很难去评价工具本身的敏感度算法能力。鸿渐提供了一套测试集,以代码分析的敏感度为基本维度,以CWE重要缺陷为基准,并将公开到我们的网站中,欢迎大家下载使用。最后我们承诺会努力做到更专业的测试,尽量穷尽所有的可能,不让用户总挑出明显的误漏报。

鸿渐科技
鸿渐科技是一家专业代码安全产品提供商,专注于软件安全、供应链安全和漏洞自动挖掘,拥有数十项发明专利和数十篇国际顶级会议论文。 团队成员曾主持参与数十个代码安全类国家重点科研项目,产品应用于政府、军队,及航空航天、能源、轨道交通、互联网、金融等行业。已为工信部、国家电网、阿里等提供服务。 鸿渐科技秉持“与客户一起成长”的理念,致力于为世界创造先进、好用、真正解决用户痛点的产品。
如有侵权请联系:admin#unsafe.sh