了解如何使用用户命名空间提高集群安全性
Kubernetes v1.25 引入了对 Linux用户命名空间(userns) 的 alpha 支持。此功能被吹捧为一个额外的隔离层,可以提高宿主机安全性并防止许多已知的容器逃逸场景。
在此博客中,我们将深入探讨用户命名空间的一些潜在用途和复杂性,给志在增强集群安全性的集群操作者提供一组最佳实践。
背景
用户命名空间不是一个新概念, 它始于Linux内核 v3.8。从那以后,用户命名空间一直是无根容器的核心技术。鉴于当前的内核版本在 5.x 范围内,用户命名空间有足够的机会发展。然而,必须认识到它们的复杂性和潜在的安全隐患:它们的使用打开了以前未经测试的代码路径。尽管在内核中存在很久,但一些 Linux 发行版选择默认禁用 用户命名空间 以使该功能成熟。Kubernetes 开发人员采用了类似的方法。
需要注意的是,在
Kubernetes中,用户命名空间仍处于alpha阶段。他们还没有准备好用于生产环境。事实上,唯一可以在托管集群中测试用户命名空间的地方是Google Kubernetes Engine (GKE) alpha集群。这篇文章中描述的所有测试都在那里进行。
用户命名空间如何提高工作负载安全性
用户命名空间使集群操作者更容易减轻容器逃逸的潜在影响,并允许更安全地向某些 pod 授予额外权限。
减轻容器逃逸的影响
在容器使用用户命名空间背后的主要动机是遏制容器逃逸的潜在影响。当以 root 身份运行的容器绑定进程逃逸到宿主机时,它仍然被视为用户ID为0的特权进程。但是,用户命名空间引入了宿主机用户 ID 和容器用户 ID 之间的一致映射,确保容器上的 UID 0 对应于宿主机上的非零 UID 的用户 ID。为了消除 UID 与宿主机重叠的可能性,每个 pod 拥有 64K 个用户 ID 用于私有使用。
因此,即使一个进程在容器内是 root(即 UID 0),逃逸到宿主机也只会授权它访问与 UID X 关联的资源。例如,在上图中,Pod A 上的 UID 0 只会能够访问宿主机上UID 65536有权访问的资源。
此外,具有用户命名空间的逃逸进程将被阻止访问如下资源:
/etc配置文件设备在
/dev/root存放潜在密钥的 目录kubelet配置,常用于集群内的横向移动,只能被集群宿主机上的root进程读取
gke-test-default-pool-c15ade0e-yz47 / # ls -la /var/lib/kubelet/kubeconfig
-rw-r--r-- 1 root root 554 Dec 10 16:11 /var/lib/kubelet/kubeconfig`
具有
root所有权的Unixsocket具有
root所有权的tcp/udpsocket
UID 映射可防止许多著名漏洞的利用。以Azurescape为例,黑客可以逃逸到宿主机并使用 kubelet 配置文件调用 API。但是,如果使用用户命名空间,他们将无法读取文件,并且漏洞利用链将被破坏,从而避免跨账户容器接管。
UID 映射的第二个好处是在发生容器逃逸事件时更好地分离同一工作节点上的 pod。这假设各个 pod 在宿主机上具有不同的 UID/GID 映射方案,这些方案应始终由受管集群上的 kubelet 处理。
UID 映射提供的第三个经常被忽视的优势是资源限制的分离。在 Linux 中,cgroups 和命名空间负责在同一宿主机上“容器化”不同的工作负载,每个工作负载都有自己的 CPU、内存配额等。然而,一些限制(如文件系统通知的数量)仍然与 UID/GID 相关联。由于许多 pod 使用 UID 1000,因此它们共享此限制;用户命名空间功能映射不同UID解决了这个问题。
剥夺不必要的特权
在自己的用户命名空间中运行的特权容器是隔离的,因此它们的功能不会损害宿主机。例如,Kubernetes 不支持 FUSE 文件系统挂载。一种解决方法是添加一个规范文件,在初始命名空间的postStart事件中用CAP_SYS_ADMIN权限安装 GCP 存储桶。
spec:
...
containers:
- name: my-container
securityContext:
privileged: true
capabilities:
add:
- SYS_ADMIN
lifecycle:
postStart:
exec:
command: ["gcsfuse", "-o", "nonempty", "your-bucket-name", "/etc/letsencrypt"]
但是,SYS_ADMIN是一种强大的能力。在这种情况下,实施用户命名空间将避免指定privileged:true和授权所需的SYS_ADMIN,从而大大减少宿主机的攻击面。
另一个常见的场景是将 pod 连接到 VPN 网络。像 OpenVPN 这样的服务需要NET_ADMIN来配置 pod 的网络设置。当使用用户命名空间隔离后,pod 无法在容器逃逸的情况下劫持宿主机的网络配置。
限制
正如 alpha 特性所预期的那样,Kubernetes 中的用户命名空间受到一些限制。
非 root 仍然可以有效地成为 root
在 Linux 中,某些操作是为特权用户保留的。即使这些操作是在用户命名空间内执行的。未测试代码路径和新增的功能也会为黑客提供新的攻击向量,使其能够在被入侵的 pod 中执行命令。
考虑CVE-2022-0185。利用此漏洞使得用户命名空间自动授予本地化CAP_SYS_ADMIN权限,反映安全功能实际上在内核级别如何产生不安全性。但是,用户命名空间的创建不是特权操作。例如,虽然禁止创建 PID 命名空间,但在以下 GKE pod 中允许创建新的用户命名空间:
[email protected]:~ (shay-junk-cluster)$ kubectl exec -it test-userns -- sh
/ # unshare -p
unshare: unshare(0x20000000): Operation not permitted
/ # readlink /proc/$$/ns/user
user:[4026531837]
/ # unshare -U
test-userns:~$ readlink /proc/$$/ns/user
user:[4026532869]
鉴于unshare(CLONE_NEWUSER)系统调用会创建新的用户命名空间, 导致尽管存在风险的本地SYS_ADMIN功能,使用 seccomp 配置文件阻止系统调用至关重要。幸运的是,Kubernetes v1.25 将默认的 seccomp 配置文件功能升级到beta,减少了部署的初始攻击面。
工作负载类
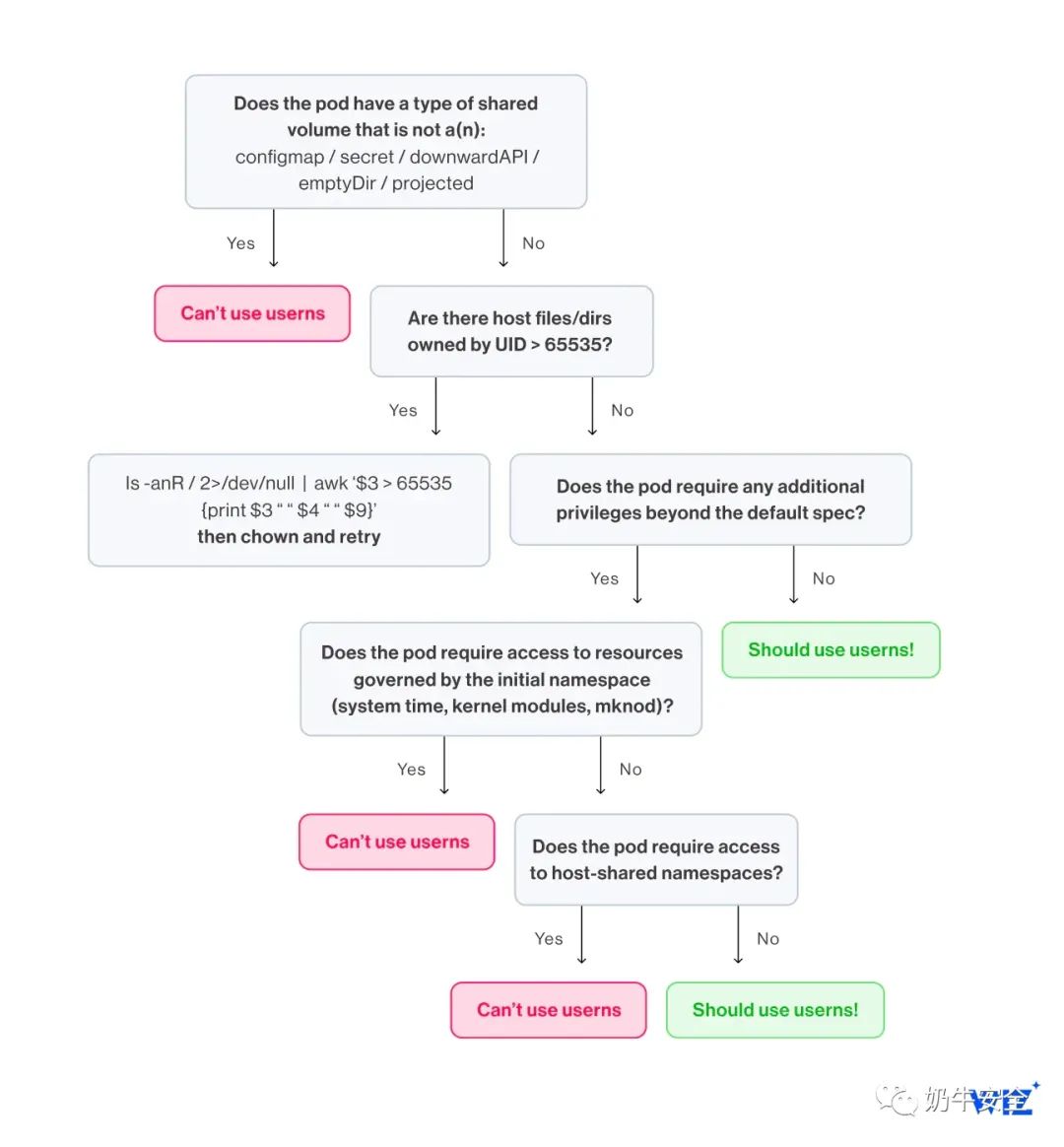
有多种因素会影响用户命名空间是否适合 Pod。以下决策树是为集群运维人员设计的,用于评估其工作负载在当前功能实现下的适合性:
与用户命名空间不兼容的三个最突出的工作负载类是具有共享卷的工作负载类、需要初始命名空间访问的工作负载类以及需要宿主机共享命名空间访问的工作负载类(请参阅附录 B)。
这些仅代表最常见的限制——还有许多其他可能的情况。Wiz 机构调查了数百个云环境以量化其中的一些限制,并发现在容器化环境中:
超过 30% 的
pod使用宿主机共享命名空间运行44% 的
pod在其规范文件中安装了有问题的卷24.4% 的
pod有特权1.8% 的
pod有allowPrivilegeEscalation: true
这些数字突出了用户命名空间如何不适用于生产环境中的大部分工作负载。未来的研究应该进一步调查提供给 pod 的特权类型以及用户命名空间对 pod 特权减少的影响。
概括
Kubernetes 中的用户命名空间提供了多种提高工作负载安全性的方法,即使它们在某些不常见的配置下会增加集群的攻击面。从重新映射 UID 到减少特权,用户命名空间改进了适用工作负载的隔离。为了帮助从业者衡量工作负载适应性,我们编制了一个决策树,描述了哪些工作负载与该功能兼容。鉴于用户命名空间的复杂性,时刻监控该特性的成熟过程并了解开发人员如何解决当前的限制。
附录
附录 A——Docker 中的用户命名空间
用户命名空间的 Kubernetes 级支持取决于容器运行时支持。Docker 是用户命名空间的最早采用者之一。在编辑/etc/docker/daemon.json后启用userns-remap来运行 Docker 守护程序时,请考虑以下用户映射。
[email protected]:/tmp$ sudo docker run -it --rm alpine sleep 1h
---
[email protected]:/usr/local/lib/systemd/system$ ps aux | grep sleep
root 2919 0.0 0.0 10752 5128 pts/1 S+ 10:19 0:00 sudo docker run -it --rm alpine sleep 1h
root 2920 0.8 0.8 1423596 53860 pts/1 Sl+ 10:19 0:00 docker run -it --rm alpine sleep 1h
296608 2969 0.4 0.0 1608 4 pts/0 Ss+ 10:19 0:00 sleep 1h
尽管sudo和 Docker 进程以 root 身份运行,但 Bash 进程的 UID 为 296608。这是因为在/etc/subuidas配置docker默认用户映射为dockremap:296608:65536。容器中的root用户对应宿主机上的UID 296608,UID 1对应UID 296609,依次类推。
此外,容器和宿主机之间的命名空间隔离级别不同,唯一共享的命名空间是时间命名空间:
[email protected]:/etc/docker$ sudo ls -la /proc/1/ns
lrwxrwxrwx 1 root root 0 Dec 16 14:04 cgroup -> 'cgroup:[4026531835]'
…
lrwxrwxrwx 1 root root 0 Dec 16 14:04 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Dec 16 14:04 uts -> 'uts:[4026531838]'
[email protected]:/etc/docker$ sudo docker run -it --rm alpine sh
/ # ls -la /proc/$$/ns
lrwxrwxrwx 1 root root 0 Dec 16 12:05 cgroup -> cgroup:[4026532866]
…
lrwxrwxrwx 1 root root 0 Dec 16 12:05 user -> user:[4026532672]
lrwxrwxrwx 1 root root 0 Dec 16 12:05 uts -> uts:[4026531838]
附录 B——决策树
Pod需要由初始用户命名空间管理的权限
命名空间的层次结构确保所有非用户命名空间管理的资源从属于用户命名空间所有者。然而,并非所有资源都与命名空间相关联。如内核用户手册中所述:
有许多特权操作会影响与任何命名空间类型无关的资源,例如,更改系统(即日历)时间(由
CAP_SYS_TIME控制)、加载内核模块(由CAP_SYS_MODULE控制)和创建设备(由CAP_MKNOD控制)。只有在初始用户命名空间中具有特权的进程才能执行此类操作。
如果在 Docker 守护进程中启用用户重映射后 尝试在用户命名空间中运行mknod会发生什么情况(请参阅附录 A)?
[email protected]:/tmp$ sudo docker run -it --rm alpine sh
/ # mknod /tmp/null c 1 3
mknod: /tmp/null: Operation not permitted
这意味着需要访问与初始命名空间关联的资源和/或系统调用的工作负载无法使用此功能。此外,不可能在pod的securityContext添加这些功能。
需要宿主机命名空间功能的 Pod
考虑一个需要CAP_SYS_ADMIN使用宿主机网络堆栈来接入宿主机网络的容器,或者一个需要CAP_SYS_PTRACE使用宿主机 PID 命名空间的调试容器。这些 pod 将不得不继续使用当前的共享接口。当前 pod 规范允许配置三种类型的可共享命名空间:
网络 (
hostNetwork: true)PID(hostPID: true)IPC(hostIPC: true)
Pod 规范中上述任何一项的存在与用户命名空间的潜在使用冲突。
有状态的工作负载
目前,仅具有以下卷类型集合的 Pod 允许使用用户命名空间:
configmapsecretdownwardAPIemptyDirprojected
这是因为一旦 Pod 由不同的用户命名空间管理,就无法在 Pod 之间共享资源。
其他限制
添加hostUser: true与设置hostNetwork、hostIPC或hostPID不兼容,因此会导致特权粒度丢失。这迫使采用二选一的方法:要么根本不使用用户命名空间,要么只使用用户命名空间。这种粒度损失也会影响功能——如果与用户命名空间结合使用,则securityContext不可能添加功能。
用户命名空间影响文件所有权映射。根据文档:“kubelet 将分配 pod属主UID/GID要高的 UID/GID给Pod里的文件。因此,为了保证尽可能多的隔离,宿主机文件和宿主机进程使用的 UID/GID 应在 0-65535 范围内。 “
以下命令在节点上查找UID > 65535 拥有的任何文件,因此需要进行 chown 编辑:
ls -anR / 2>/dev/null | awk '$3 > 65535 {print $3 " " $4 " " $9}'
如有侵权请联系:admin#unsafe.sh