原文作者:Xinda Wang, Kun Sun, Archer Batcheller, Sushil Jajodia原文连接:https://csis.gmu.edu/ksun/publicatio 2023-5-8 23:31:51 Author: 安全学术圈(查看原文) 阅读量:32 收藏
原文作者:Xinda Wang, Kun Sun, Archer Batcheller, Sushil Jajodia
原文连接:https://csis.gmu.edu/ksun/publications/secretpatch-dsn19.pdf
发表会议:2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)
笔记作者:童话(tonghuaroot) - https://www.tonghuaroot.com/about
笔记小编:黄诚@安全学术圈
本文为我在学习 Detecting “0-Day” Vulnerability: An Empirical Study of Secret Security Patch in OSS 时整理的笔记,主要包含如下 3 个部分内容。
读 paper 时整理的笔记产品化模式的思考其他潜在的 idea
秘密安全补丁:开源库的作者为某个安全漏洞打了补丁,但是未通过 CVE 披露该漏洞,未在 release log 中提示用户该更新为安全更新。(通俗的说就是厂商没发公告偷偷的把洞给修了。)
本文介绍了开源软件中的漏洞数量不断增加的问题,以及软件供应商可能会私下修补其漏洞的情况。为了防御这些 “N-day” 攻击,开发人员和用户需要一种方法来识别开源软件中秘密安全补丁的存在,以便及时更新其软件。作者开发了一种基于机器学习的方法,以帮助自动从发布的软件补丁和开源软件的两个版本之间的差异中识别秘密安全补丁。实验结果表明,该模型可以实现良好的性能。
一些有趣的数据和结论
2018 年有 3100 万开发者在 960 万个存储库中工作。 Snyk 的报告显示,从 2016 年到 2017 年发布的开源漏洞数量增长了 53.8%。其中一个原因是攻击者可以分析 OSS 的源代码以发现未知漏洞。 攻击者可以通过分析安全补丁实现漏洞利用代码。(基操勿6) 部分开源项目的作者会偷偷修漏洞不发安全公告。
作者团队创建了一个新的安全补丁数据集,其中包含 1999 年至 2018 年所有可用的 CVE 条目中的所有引用链接,共包含 4702 个安全补丁。专注于 C/C++ 语言,并挑选出 1636 个用 C/C++ 编写的安全补丁。为了识别安全补丁,其团队开发了一种基于机器学习的方法,使用 61 个特征集来区分安全补丁和非安全补丁。在训练集上进行了实验,实验结果表明,该模型表现良好,检出率为 79.6%,误报率为 41.3%。对三个知名开源 SSL 库进行了案例研究,即 OpenSSL,LibreSSL和BoringSSL,并发现了12个秘密安全补丁,其中最长的秘密补丁和公开发布之间的延迟超过两年。
该系统由三个主要步骤组成:构建安全补丁数据集,训练基于机器学习的安全模型,评估模型有效性。从至少 898 个开源项目中爬取了 4702 个安全补丁,并采用投票算法集成了五种分类算法来构建基于机器学习的模型。数据集包含 1636 个安全补丁和 1636 个非安全补丁。作者团队将每个补丁的特征转换为一个向量,并附带一个标签,标记该补丁是否为安全补丁或非安全补丁。使用 80% 的数据集作为训练数据集,剩余的 20% 作为测试数据集,以评估系统性能。
相关架构如下:
为了收集安全补丁数据集,作者通过查询CVE条目构建了一个数据库,收集了 1999 年至 2018 年的所有 CVE 条目中包含补丁的相关参考 URL。为了收集非安全补丁数据集,作者下载了出现在 CVE 列表中的开源代码库,并随机选择非安全提交作为非安全补丁数据集。
(简单理解:爬了下 CVE 列表,提取 CVE 列表中 Reference 里头的 GitHub Commit,作为漏洞数据集。针对相关的 GitHub Repo,随机选择一些非安全相关的 commit,作为非安全补丁数据集。)
安全补丁数据集
至 2018 年 4 月 11 日,CVE 列表共有 126,491 个 CVE 条目,每个条目包括 CVE ID、漏洞概述和相应的报告、建议和补丁参考 URL。补丁参考 URL 可分为两类:托管在 GitHub 上的项目和托管在其他网站上的项目。对于托管在 GitHub 上的项目,安全补丁参考URL(commit url)的形式为 https://github.com/owner/repo/commit/commit_hash,其中 commit_hash 是提交的唯一标识符。对于其他网站上的项目,作者使用特定的符号来识别安全补丁(diff、@@、+++ 和 --- 作为补丁存在的指标),仅收集了692个安全补丁。我们的模型针对C/C++项目的补丁,其中包含了1636个安全补丁。
非安全补丁数据集
为了训练相关模型,作者采集了一套非安全补丁数据集。从出现在 CVE 清单中并托管在 GitHub 上的项目中收集非安全补丁。为了避免混合多个补丁的大补丁,作者随机选择了 1636 个提交作为非安全补丁数据集。通过比较提交哈希值(排除安全补丁),获得了相同大小的安全补丁和非安全补丁数据集。(898 个 Github Repo 中收集了 1636 个非安全补丁相关 commit。)
通过机器学习模型区分安全补丁和非安全补丁。基于此前收集的特征,将数据集中每个补丁表示为包含安全补丁或非安全补丁标签的向量。采用有监督学习训练模型,给定新的未标记补丁时,该系统将其向量化,并识别它是否为安全补丁。
特征提取
补丁包含旧版文件和新版文件之间的差异,CVE-2014-3158 的补丁示例代码如下:
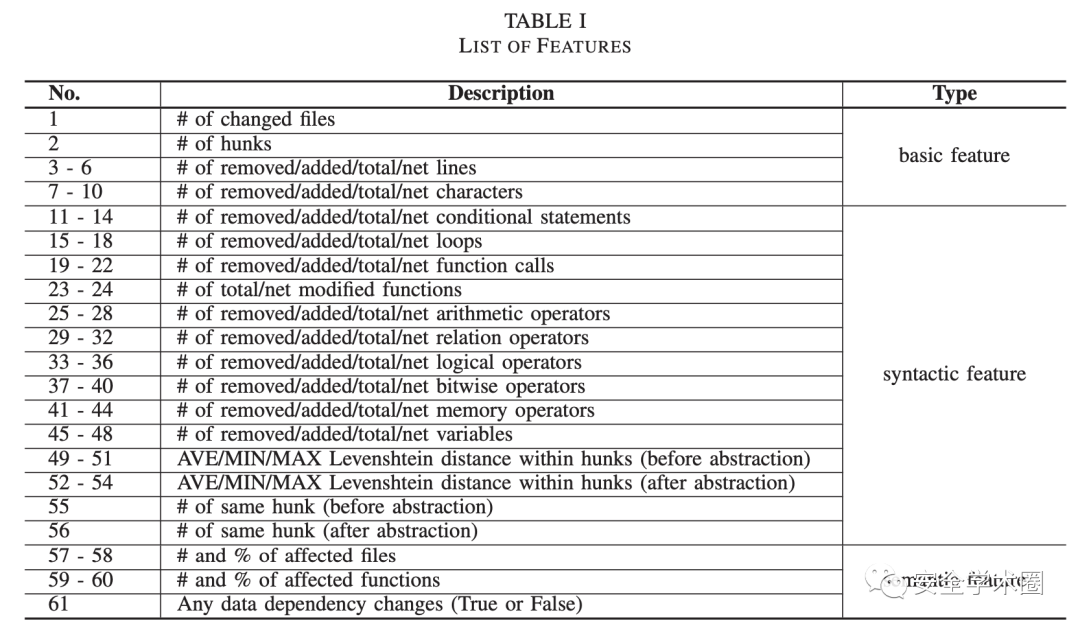
作者从 Tian 等人的工作中借用了 22 个特征,包括文件、代码块、条件语句、循环、行、字符和函数调用的变化。此外,作者提出了 34 个更多的句法特征和 5 个语义特征,如修改函数的总/净数、基本运算符的总/净/删除/添加数量、相同块的数量(抽象前/后)等。
通常情况下,安全补丁修改的代码更少,更有可能在运算符和操作数上引入修改,更有可能将一段代码移动到没有其他更改的另一个地方,相同或相似的更改块可能会在不同的函数或文件中多次出现。(Total 是这些基本程序功能的删除和添加数量之和,Net 是添加数量减去删除的数量。)
相关特征如下:
机器学习模型
为了提高机器学习模型的性能,作者使用了随机森林、贝叶斯网络、随机梯度下降、序列最小优化和装袋等分类算法,并采用投票算法将它们合并。作者将 80% 的数据集转换为超过 61 个特征的向量,并将标签 “1” (安全补丁) 或 “0” (非安全补丁)作为输入训练数据。在检测阶段,作者将剩余 20% 的补丁集向量化,应用模型进行检测,如果向量被分配“1”,则相应的补丁被检测为安全补丁,否则为非安全补丁。
通过三种方法评估了系统有效性:
将数据集分成训练集和测试集,评估模型的检测准确性。 将模型应用于 20 个 OpenSSL 1.0.1 的小版本补丁,并将其与 SPAIN 的研究结果进行比较。 将实验扩展到 3 个主流 SSL 库(OpenSSL、LibreSSL 和 BoringSSL),发现多个秘密安全补丁。
基于数据集评估模型的检测准确性
80% 的数据集作为训练集、20% 作为测试集,其中 334 个正样本和 320 个负样本。
测试结果如下:
与 SPAIN 的研究结果进行比较
SPAIN 专注于二进制级别的补丁分析,也可用于识别开源补丁,其在开源项目 OpenSSL 上进行了实验以评估其准确性。
以 OpenSSL 为例,与 SPAIN 之间的比较结果:
该系统识别安全补丁的百分比比 SPAIN 高 8%。 该系统的误报为 190,SPAIN 的误报更少为 47。 该系统覆盖函数间补丁、头文件补丁以及无控制流变更的补丁,而 SPAIN 不能。如图,
在 NVD 漏洞库上,该系统应对各种开源软件及漏洞类型表现出良好的性能和扩展性,由于 SPAIN 主要做二进制代码分析,因此其很难提供类似的性能结果。
在 3 个主流 SSL 库上的实验表现
该系统在三个开源 SSL 库(OpenSSL、LibreSSL和BoringSSL)的表现结果如下:
一些有趣现象:
只有一个漏洞被分配了CVE ID,其他漏洞都只是秘密修复。 CNA 机制为软件供应商提供了秘密修复漏洞的机会。 当一个项目修复相关漏洞后,其他同类项目可能需要很长时间才能意识到秘密修复的漏洞并采取行动。 软件版本控制过程应更清晰,准确地宣布安全修复。(如 CVE 漏洞正常披露,但是在 release log 中未强调安全更新,可能会误导作为用户的开发者暴露在潜在的安全风险中。)
从检测到可疑漏洞到漏洞被真实利用仍然有很长的路要走。存在漏洞和存在可以被直接利用的漏洞是两个事,并不是所有的 CVE 漏洞都能够被利用。也不是所有的安全漏洞都会被分配 CVE 编号。
该 paper 的数据源是 CVE 漏洞库,这可能导致仅覆盖到了较严重的漏洞。作者用了被 OpenSSL 拒绝分配 CVE ID 的一个低危漏洞本地边信道攻击证明了这一点。
由于手动审查可疑漏洞并评估其严重性需要大量的工作以及相关领域专家的支持,作者在此处表示将如何识别可利用的漏洞作为未来的工作。
同样的方法攻击者可能已经在利用了,因此作者团队的目标是促进软件供应商规范维护其产品,增加软件供应商之间的信息共享合作,并最终消除这种“0-day”攻击。(如:采用行业标准的漏洞披露流程。)
非安全补丁数据集仍可能包含安全补丁,由于未知秘密安全补丁的存在,会对实验结果产生影响。作者团队随机选择了 1636 个非安全补丁数据集中的 536 个进行手动检查,将其中 7% 标识为安全补丁。由于机器学习能够处理嘈杂的数据集,该比例的安全补丁可以被接受。在未来,可以从非安全补丁数据集中删除这些安全补丁来进一步清理数据集。
该系统将 GitHub Commit 作为最小补丁单元,由于并非所有开源项目均采用 GitHub,对于未托管在 GitHub 的项目,通过 diff 文件获取相关补丁更新,较大 diff 文件很难分离出多个补丁单元,这部分作者表示作为下一步工作。
目前该项目仅支持 C / C ++ 实现的开源项目,未来可以通过调整语法解析相关的特征覆盖到其他语言。
OSS 漏洞检测热门研究方向:
漏洞代码相似度检测 漏洞模式识别
漏洞代码相似度检测
传统的基于 token 的技术:通过移除空格和注释,将变量和函数名替换为特定字符,检测仅对标识符、注释和空格进行少量修改的 Type-1 和 Type-2 代码克隆。 基于树的技术:将程序代码转换为 AST,然后比较 LST。 基于图的技术:使用控制和数据依赖图来检测代码克隆作为同构子图。
漏洞模式识别
机器学习或深度学习:从漏洞代码中提取对应 pattern,检索具有对应 pattern 的代码。 VulPecker:采用多种特征集检测不同类型的软件漏洞。 VulDeepecker:训练了 1 个神经网络,用于检测通过库、API 调用导致的缓冲区溢出和资源管理漏洞。
安全补丁数据库
Seulbae 等人:在 8 个知名 Git 仓库中收集相关数据。 Zhen 等人:从 19 个产品中构建漏洞补丁数据库(VPD)。
上述两个数据集太小,不足以支撑机器学习相关研究。
Li 等人:基于 NVD 中 Git 记录构建了 1 个大规模的安全补丁数据库。(没开源)
秘密安全补丁
Zhen 等人:发现了一些秘密安全补丁(厂商偷偷的修复漏洞没发公告)。(这也是作者的 idea 来源。) Xen:CVE-2016-9104 Seamonkey 和 Firefox:CVE-2015-4517 Libav 和 FFmeng:CVE-2014-2263
补丁分析
Zame 等人:对 Mozilla Firefox 中安全补丁和性能补丁之间的差异进行了案例研究。 Perl 等人:展示了漏洞相关的 commit 和其他 commit 之间的多个统计差异。(无法区分漏洞修复和非漏洞修复。) Frank 等人:大规模实证研究,比较安全补丁和非安全补丁,提供安全补丁基本特征分析。 Xu 等人:通过执行跟踪的语义分析来识别安全补丁。(无法处理跨函数安全补丁,在识别和安全补丁相似度较高的非安全补丁时表现不佳。)
实现了基于机器学习的安全补丁识别系统,开发者可基于该系统识别秘密安全补丁,并确定是否更新新版本或者应用该补丁。
通过该系统识别出有效安全补丁,横向分析其他同类开源库是否存在该安全漏洞,并应用该补丁。
发现一组句法和语意代码特征用于标记潜在的安全补丁,特征提取的代码也开源了,相关地址:‣。
开源了一组数据集,包含安全补丁和非安全补丁,用于验证该模型的有效性,相关地址:https://github.com/XindaW/SecretPatch
在 3 个知名开源 SSL 库中发现了 12 个秘密安全补丁。
Detecting “0-Day” Vulnerability: An Empirical Study of Secret Security Patch in OSS:https://csis.gmu.edu/ksun/publications/secretpatch-dsn19.pdf
能落地的技术才是好技术,心里踏实,喜欢这种 practice 的 research。
SCA 产品提供某组件是否被引入、是否需要升级、如何升级的关键能力。此 paper 中提出的方法可以覆盖未遵循行业标准披露流程的漏洞修复,提高漏洞的覆盖度和能见度,可通过 API 调用暴露相关能力。 SAST 检测规则覆盖度:识别秘密安全补丁中的代码 pattern 补丁前后特征,提高 SAST 检测规则及修复建议中的 code example。 威胁情报:通过检测开源项目最新 Commit 记录,判断是否为安全补丁,为甲方提供漏洞情报侧的支持。
其他编程语言下面的效果:Java、Golang、Python 结合其他维度评估是否为安全补丁:威胁情报、bug track 管理系统(Apache Jira) 除了检测漏洞,还可以检测供应链攻击,代码投毒啥的。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh