
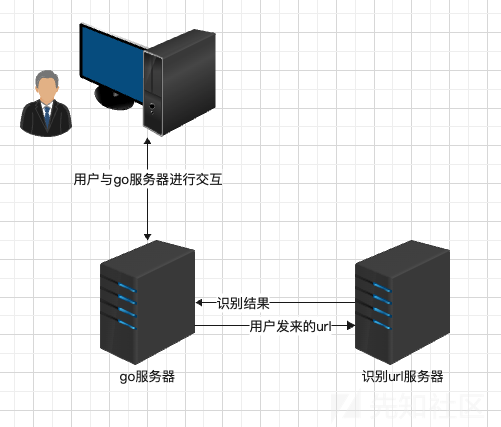
整体效果和架构图
0.1版本
最近想写一个基于 AI 的一个安全攻防项目,想了几个备选的想法,把重点放在了写一个 waf 上,0.1 版本算是完成了,效果图:
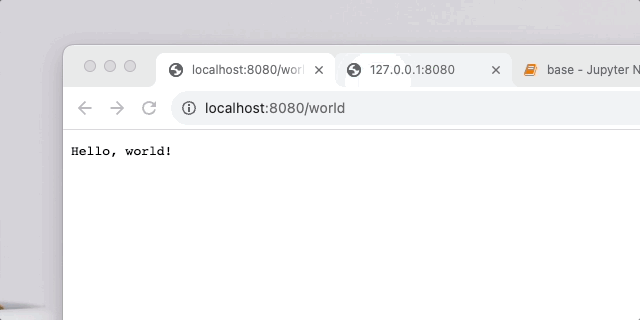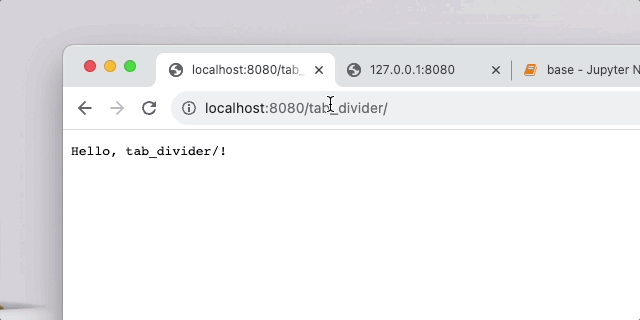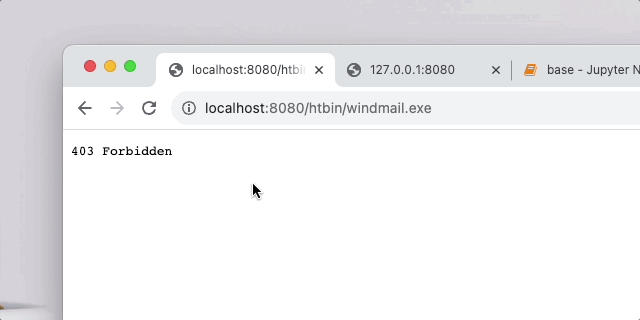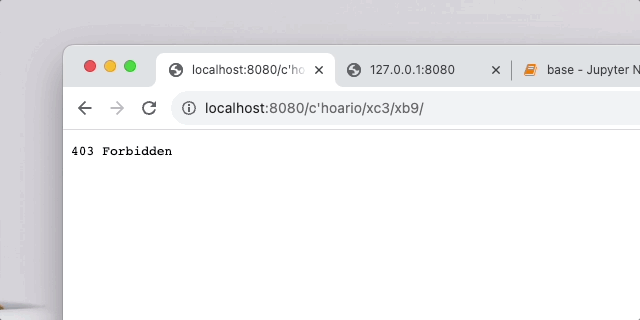
url 不对劲直接就forbidden,否则hello,{your_url}!
整体架构就是可以起一个 go 服务,go 服务器收到用户发来的 url 后就去找识别 url 的服务器,识别 url 服务器的能够根据训练出来的模型来把 url 自动识别是否为恶意请求,go 服务器得到回应之后可以进行一系列操作,没问题的话就放行,否则就向攻击者发送警告,封禁 ip 或者直接把 session 等销毁掉。这就根据具体业务来定了,这个 demo 实现的很简单,就是个hello world,把重点放在了 waf 上。
本文从三个方面来介绍:
- 数据集生成并处理
- 神经网络训练过程
- 两个服务器的交互
数据集生成并处理
数据集可以从网上找,找到适合自己网络结构的。
还有一种就是自己定制化生成,对于企业来说,就是比如自己企业的测试部门在网页上线之前对网页进行的渗透行为可以把这块流量全部记录下来,或者红蓝对抗、HW的时候要及时复盘流量,自己复现下,按需打一打标签,更新自己的数据集。比如任何对网站不构成实质性威胁的行为统一打成0,即良性url上。而恶意的url就可以酌情定义了,比如url打过去出现信息泄漏,或者rce这种很严重的都可以打上1,sql注入尝试什么都统统打上1,<script>alert(1)</script>这种也是,但凡是正则能识别出来的通通打1!
badrequest数据集生成
用的xray。靶机用了docker起了个pikachu(因为自己这个helloworld小demo实在没什么可打的,233)。之后把本机的lo0网卡信息全部捕捉下来了,通通标成1就行了。
package main import ( "bufio" "bytes" "fmt" "log" "net/http" "os" "github.com/google/gopacket" "github.com/google/gopacket/pcap" ) func main() { //网卡信息lo0,可以按需修改 handle, err := pcap.OpenLive("lo0", 65536, true, pcap.BlockForever) if err != nil { log.Fatal(err) } defer handle.Close() // tcp协议,端口是8000,而且只抓get请求(按需修改按需修改 filter := "tcp and port 8000 and tcp[((tcp[12:1] & 0xf0) >> 2):4] = 0x47455420" if err := handle.SetBPFFilter(filter); err != nil { log.Fatal(err) } // 创建一个文件用于存储URL信息 file, err := os.Create("url_info.txt") if err != nil { log.Fatal(err) } defer file.Close() // 开始捕获数据包 packetSource := gopacket.NewPacketSource(handle, handle.LinkType()) for packet := range packetSource.Packets() { // 解析数据包 if applicationLayer := packet.ApplicationLayer(); applicationLayer != nil { // 提取HTTP请求中的URL信息 if request, err := http.ReadRequest(bufio.NewReader(bytes.NewBuffer(applicationLayer.Payload()))); err == nil { url := request.URL.String() // 将URL信息写入文件 if _, err := file.WriteString(url + "\n"); err != nil { log.Println(err) } fmt.Println(url) } } } }
之后把抓包程序跑起来,把pikachu也开开
docker run --name piakchu -d -p 8000:80 area39/pikachu
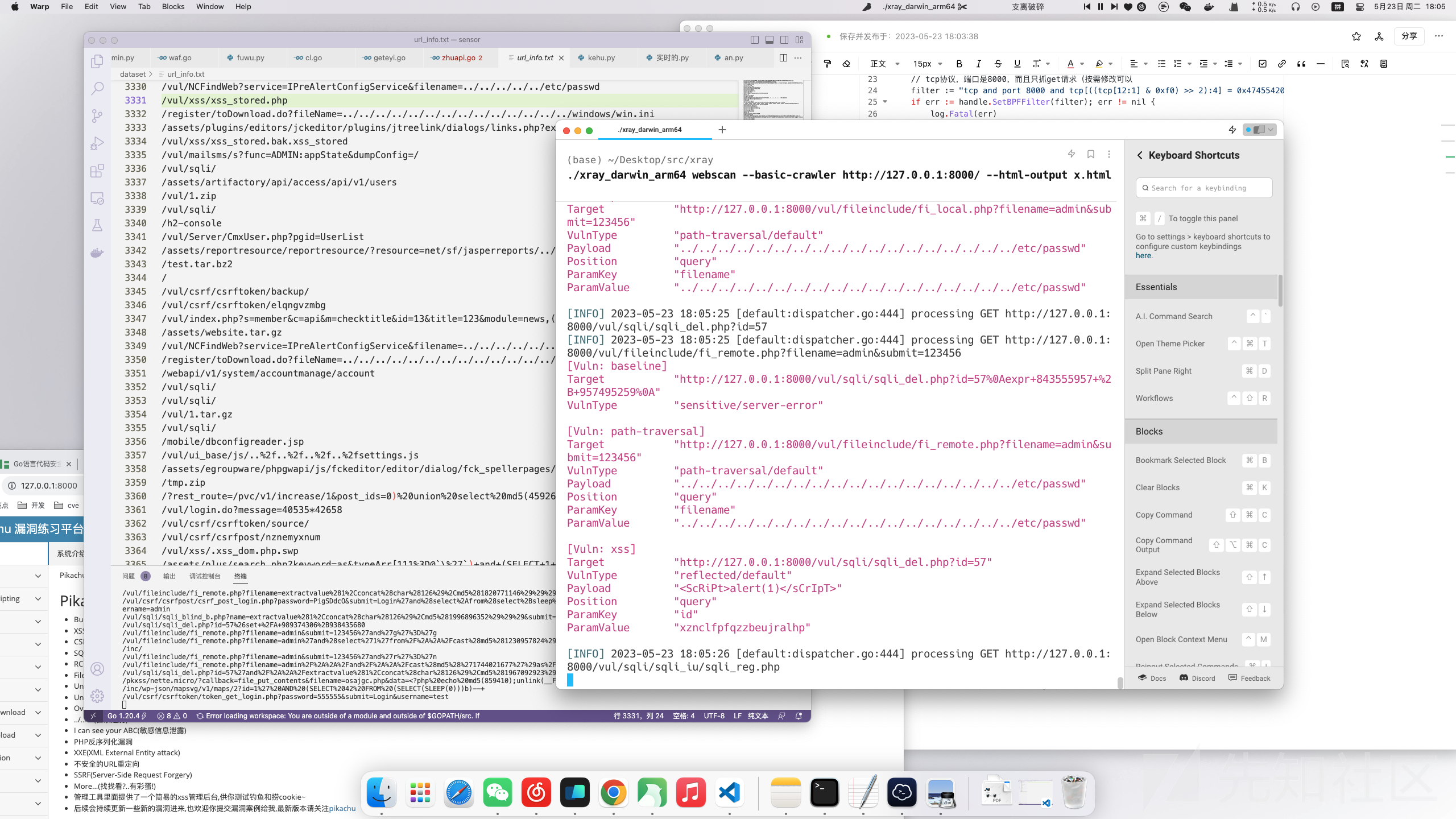
之后用xray的爬虫功能就行了
./xray_darwin_arm64 webscan --basic-crawler http://127.0.0.1:8000/ --html-output xx.html
可以看到能够得到不错的数据,左侧是恶意url数据集
良好数据集生成
这块用了两种生成方式,一种就是模拟点击的方式,将所有url按照迭代的方式一代一代的点击一遍,对于本项目,pikachu而言能够点击的url着实不多
from requests_html import HTMLSession import time def save_links_to_file(links): # 追加链接到文件 with open('urls.txt', 'a') as f: for link in links: f.write(link + '\n') def crawl(url, end_time): # 创建HTMLSession对象,获取网页内容 session = HTMLSession() r = session.get(url) # 获取所有链接 links = r.html.absolute_links urls = [] for link in links: # 如果链接是以http或https开头,则保存链接 if link.startswith('http'): urls.append(link) # 保存链接到文件 save_links_to_file(urls) # 递归访问所有链接 for url in urls: # 如果当前时间已经超过了指定时间,则停止递归 if time.time() > end_time: return crawl(url, end_time) # 设置爬取的起始URL和结束时间 start_url = 'http://127.0.0.1:8000/' end_time = time.time() + 3 # 调用函数,从指定URL开始递归访问所有链接,并追加到文件 crawl(start_url, end_time)
最后得到了使用sort -u urls.txt看下有多少。发现只有62行有效数据,这和我们使用xray得到的恶意数据集完全不是一个量级(恶意数据集有1万条url
我想了个别的方式(关于如何获取好的url,以构建自己的良性数据集),实现方式是写了个油猴插件,每次生成数据的人打开一个url的时候插件把url发送给服务器上,服务器端保存所有用户的数据(当然这是访问别的网站时候的数据,但只要数据具有多样性,重点是网络能不能学到恶意url而不是局限于具体的网站架构)。具体插件架构如图:
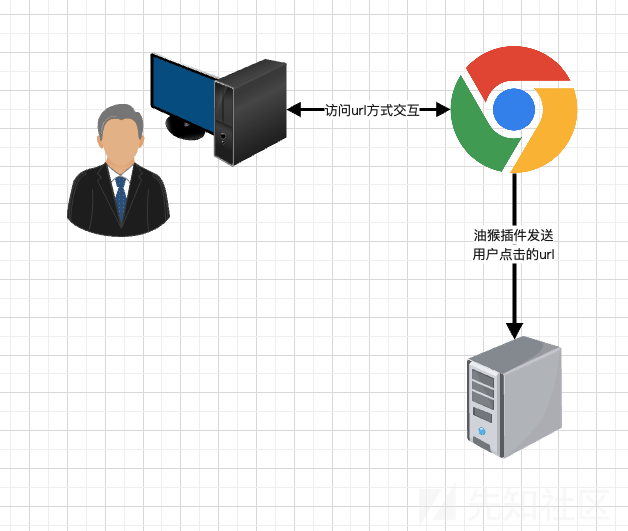
油猴和服务器端代码如下:
// ==UserScript== // @name Append URL to Local File // @namespace http://tampermonkey // @version 1.0 // @description Append current URL to local file on page load // @match *://*/* // @grant GM_xmlhttpRequest // ==/UserScript== (function() { 'use strict'; // 获取当前页面的URL const currentUrl = window.location.href; // 发送 HTTP 请求将 URL 发送到服务器 GM_xmlhttpRequest({ method: 'POST', url: 'http://***:7000',//改成自己的,我用的阿里云,好用,上云就上阿里云! data: currentUrl, headers: { 'Content-Type': 'text/plain' }, onload: function(response) { console.log('URL sent to server'); }, onerror: function(error) { console.error('Error sending URL to server:', error); } }); })();
服务器端,用的 nodejs 接收
const http = require('http'); const fs = require('fs'); const server = http.createServer((req, res) => { if (req.method === 'POST') { let body = ''; req.on('data', chunk => { body += chunk.toString(); }); req.on('end', () => { fs.appendFile('urls.txt', body + '\n', err => { if (err) { console.error('Error appending URL to file:', err); res.statusCode = 500; res.end('Error appending URL to file'); } else { console.log('URL appended to file:', body); res.statusCode = 200; res.end('URL appended to file'); } }); }); } else { res.statusCode = 404; res.end('Not found'); } }); server.listen(7000, () => { console.log('Server running on port 7000');
我这块监听了一下午自己访问的网站,其实数据量也是相当小的

处理的话简单,去重和审核一遍就行了,只要你没对浏览过的网站进行渗透啥的基本都没问题。最后用的数据是自己爬了点别的网站(尽管sklearn可以处理样本不均衡这个问题,但数据起码得足够多样),才凑够了量级
神经网络训练过程
训练选择了sklearn里的TfidfVectorizer,通过其将url数据转化为向量形式方便计算,之后一个简单的逻辑回归
因为重点是 ai 的使用而不是 ai 的原理,所以就一笔带过了,大家注释看不太懂或者任何想法直接留言就行
import os from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import urllib.parse def load(name): filepath = os.path.join(str(os.getcwd()), name) with open(filepath,'r') as f: alldata = f.readlines() ans = [] for i in alldata: i = str(urllib.parse.unquote(i)) ans.append(i) return ans badqueries = load('badqueries.txt')#导入数据集 goodqueries = load('goodqueries.txt')#导入两类url Y = [1 for i in range(0, len(badQueries))]+[0 for i in range(0, len(validQueries))]#给标签 vectorizer = TfidfVectorizer()#用来将url向量化 X = vectorizer.fit_transform(badqueries+goodqueries)#直接输进去 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)#分割训练数据和测试数据 lgs = LogisticRegression(class_weight='balanced') #简单的逻辑回归二分类 lgs.fit(X_train, y_train)#begin! print(lgs.score(X_test, y_test)) #0.9941273293313274
这块其实挺纠结,感觉有劲使不上,看的论文思路有把代码转化成图像的,然后输入到CNN网络里边的,有模仿NLP实现一个多分类的,最后发现这个效果最好,hhhh
咋说呢,还是适合数据集的网络是最好的网络。
两种服务器的交互
这块实现就简单了,go程序和python程序实现了简单的通信。
python是用了个flask实现,python代码如下:
import re from flask import Flask, request import os from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import urllib.parse def load(name): filepath = os.path.join(str(os.getcwd()), name) with open(filepath,'r') as f: alldata = f.readlines() ans = [] for i in alldata: i = str(urllib.parse.unquote(i)) ans.append(i) return ans badqueries = load('badqueries.txt') goodqueries = load('goodqueries.txt')#导入两类url Y = [1 for i in range(0, len(badqueries))]+[0 for i in range(0, len(goodqueries))]#给标签 vectorizer = TfidfVectorizer()#用来将url向量化 X = vectorizer.fit_transform(badqueries+goodqueries)#直接输进去 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)#分割训练数据和测试数据 lgs = LogisticRegression(class_weight='balanced') #简单的逻辑回归二分类 lgs.fit(X_train, Y_train)#begin! print(lgs.score(X_test, Y_test)) app = Flask(__name__) @app.route('/check_url', methods=['POST']) def check_url(): url = request.form['url'] X_predict = vectorizer.transform([url]) res = lgs.predict(X_predict) if res==1:return '1\n' return '0\n' if __name__ == '__main__': app.run(host='0.0.0.0', port=8889)
这块因为精简就放到一个文件中来,完全可以把模型保存起来,因为每次起一次这个服务,都会进行一遍模型的训练,对于这个简单的当然无所谓,但是以后数据量大训个一两天就gg了
go语言如下:
package main import ( "fmt" "io/ioutil" "net/http" "strings" ) func main() { // 启动HTTP服务器,监听8000端口 http.HandleFunc("/", handleRequest) http.ListenAndServe(":8080", nil) println(1) } func handleRequest(w http.ResponseWriter, r *http.Request) { // 从请求中获取URL url := r.URL.Path[1:] // 发送HTTP请求到Python服务器 result, err := checkURL(url) if err != nil { // 如果调用失败,返回500 Internal Server Error错误 // 这块也可以优化,python服务器挂了等于go服务器也挂了,hhhh http.Error(w, "500 Internal Server Error", http.StatusInternalServerError) return } // 如果返回值为1,禁止访问该URL,否则允许访问 if result == 1 { http.Error(w, "403 Forbidden", http.StatusForbidden) } else { fmt.Fprintf(w, "Hello, %s!", url) } } func checkURL(url string) (int, error) { // 构造HTTP请求 data := fmt.Sprintf("url=%s", url) req, err := http.NewRequest("POST", "http://localhost:8889/check_url", strings.NewReader(data)) if err != nil { return 0, err } req.Header.Set("Content-Type", "application/x-www-form-urlencoded") // 发送HTTP请求 client := &http.Client{} resp, err := client.Do(req) if err != nil { return 0, err } defer resp.Body.Close() // 解析HTTP响应 body, err := ioutil.ReadAll(resp.Body) if err != nil { return 0, err } result := string(body) if result == "1\n" { return 1, nil } else { return 0, nil } }
事实上这块服务可能会被逆向攻击,就是用户不断尝试url来把python服务器猜个大概,可能有点类似ssrf?把这个模型逆向出来。所以给个forbidden是绝对不够的,之后要加封 ip 等操作
todo
- 虽然python处理起来挺快的,但是python一旦掉了就影响业务了,所以想了个方法,就是把用户访问的url和用户ip(登陆后用户信息也行)做一个绑定。没收到消息也没关系,把上边的绑定关系记住,当python返回来后直接该封就封,该警告就警告
- 完善业务,改成个动态网站,这个太low了
- 不能只根据url,还有body,head的恶意数据也要识别出来,所以找数据或者自己做
如有侵权请联系:admin#unsafe.sh