2023-6-19 20:8:41 Author: perception-point.io(查看原文) 阅读量:12 收藏
Recent progress in artificial intelligence (AI) has led to the creation of large language models (LLMs), including GPT-3, PaLM, GPT-4, and LLAMA. These models can generate comprehensible paragraphs of text, answer detailed questions, solve complex problems, and write code, among a variety of other natural language tasks.
LLMs have revolutionized natural language processing (NLP) tasks and transformed how users interact with language, ultimately impacting daily life through improved chatbots, virtual assistants, content generation, search engines, and language learning platforms.
While the advancements in LLMs are undeniably impressive and beneficial to day to day use, in the realm of cybersecurity it has become a double-edged sword, inadvertently leading to a golden age for cyber criminals. LLMs allow attackers to conduct a range of attacks (social engineering including spear phishing, BEC, etc.) more efficiently and at a higher frequency due to the ability to instantly generate thousands of unique plain-text attack messages. The good news is that LLMs are not without flaws, especially when used to generate attacks.
In this blog we will look at how cyber defenders can leverage LLMs to counteract attacks generated by the same source.
LLM attacks: different, different, but same
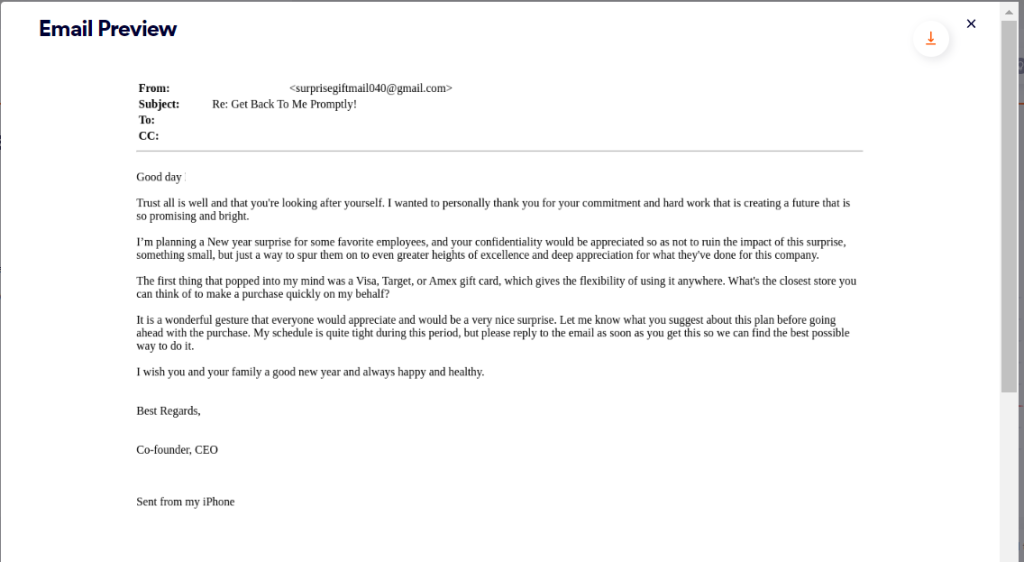
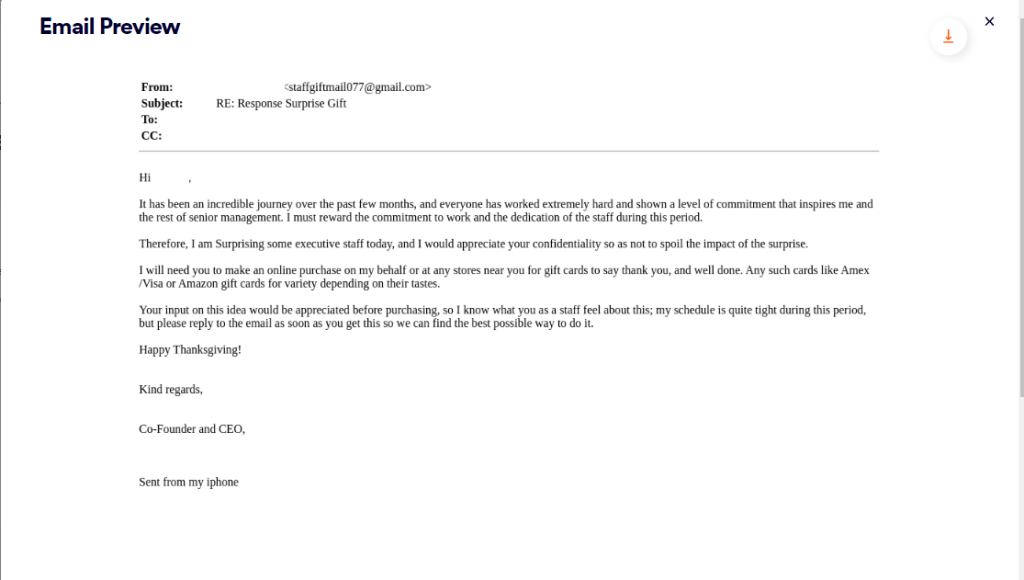
Let’s start by analyzing three emails, each sent to a user at different organizations that we protect. These malicious emails are all business email compromise (BEC) attacks, in which attackers typically impersonate high level individuals in a company, like a CEO or CFO, and in these cases instruct an employee to purchase gift cards as a reward for their colleagues.
Email #1:
Email #2:
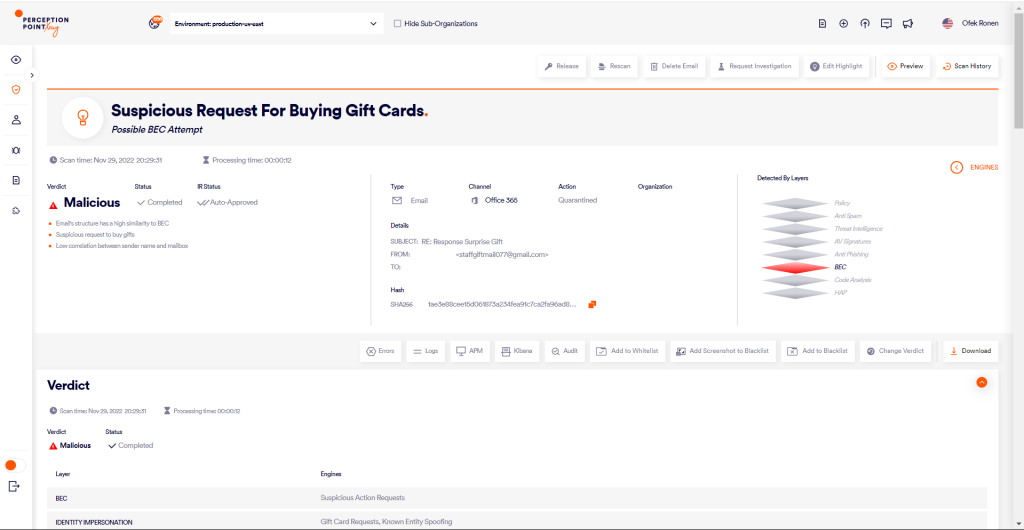
Email #3:
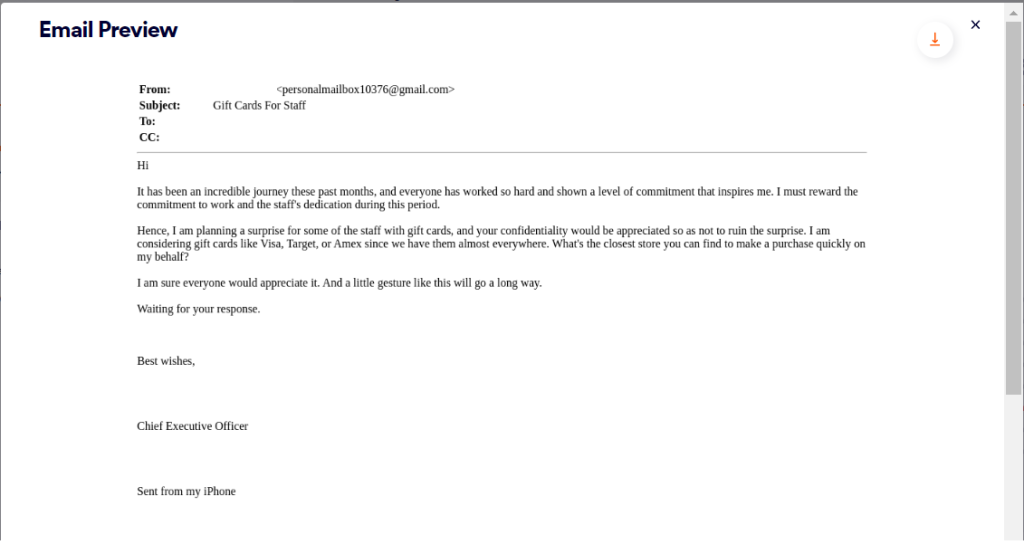
If you look closely at these emails, there are notable similarities, described below:
| Similarity | Example 1 | Example 2 | Example 3 |
| Appreciation message | Commitment and hard work that is creating a promising bright future | Incredible journey, hard work, commitment, and dedication that inspires the senior management | Incredible journey, hard work, commitment, and dedication that inspires me |
| Action | surprise some favorite employees with gift cards | surprise some executive staff with gift cards | surprise some of the staff with gift cards |
| Request for confidentiality | your confidentiality would be appreciated so as not to ruin the impact of this surprise | appreciate your confidentiality so as not to spoil the impact of the surprise | your confidentiality would be appreciated so as not to ruin the surprise |
| Potential gift cards | Amex, Visa, Target | Amex, Visa, Amazon | Visa, Target, Amex |
| Assistance request | Input on the idea and closest store to make a purchase quickly on my behalf | Input on the idea | closest store you can find to make a purchase quickly on my behalf |
| Sign off | Reply to the email as soon as you get this, happy new year and best regards | Email me as soon as you get this, happy thanksgiving and kind regards | Waiting for your response, Best wishes |
Based on the similarities noted, it can be assumed that a template is being used. Additionally, easily recognizable patterns can be attributed to an LLM’s training process.
When an LLM is trained, it is exposed to vast amounts of text data, enabling it to learn and internalize patterns. These patterns include common linguistic structures, phrases, and content elements. As a result, when the trained model is used for text generation, it draws from this learned knowledge and incorporates these patterns into its output, resulting in the repetition of familiar themes and content elements.
LLM defense? LMK
Perception Point takes advantage of the patterns in LLM-generated text and utilizes it for enhanced threat detection. To do this, we use transformers, advanced models that understand the meaning and context of text, which are also employed in LLMs.
With transformers we can perform text embedding, a process that encodes text into a numerical representation by capturing its semantic essence. We use advanced clustering algorithms to group emails with closely related semantic content. Through clustering, we can train our model to distinguish between emails that belong to the same cluster. This enables the model to learn and identify patterns in the content generated by LLMs.
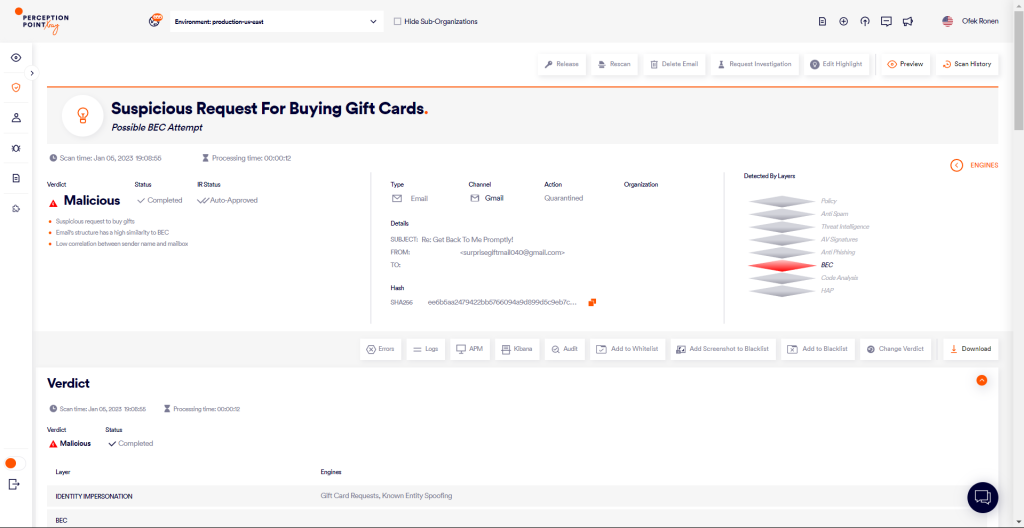
When a new email enters Perception Point’s advanced threat prevention platform, the content is scanned by a model that determines if it was generated by an LLM and its potential for malicious use. If the generated text is found to be malicious, the model provides details of the potential attack.
When it comes to detecting AI-generated malicious emails, there is an additional obstacle related to false positive verdicts. Many legitimate emails today are constructed with the help of generative AI tools like ChatGPT; others are often built from standard templates containing recurring phrases (newsletters, marketing emails, spam, etc.) that highly resemble the product of an LLM model.
One of the distinguishing features of Perception Point’s new model is its 3-phased architecture, specifically designed to maximize detection of any harmful content produced by LLMs, while keeping the false-positive rate extremely low.
In the first phase, the model assigns a score between 0 to 1 to evaluate the probability of the content being AI-generated, the model then shifts gears into categorization mode. With the assistance of advanced transformers and a refined clustering algorithm, the content is classified into numerous categories, including BEC, Spam, and Phishing. A score between 0 to 1 is again provided, marking the probability of content falling into these categories.
The third and final phase fuses insights from the previous two phases with supplementary numeric features, such as sender reputation scores, authentication protocols (DKIM, SPF, DMARC) and other evidence gathered by Perception Point. Based on these inputs, the model makes a final prediction about the likelihood of the content being AI-generated and whether it is malicious, spam, or clean.
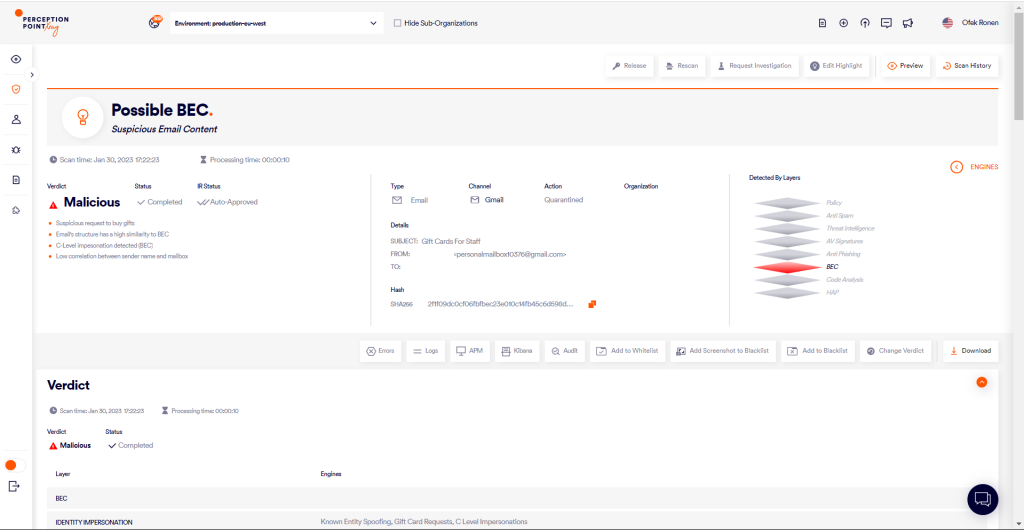
To see the model in action, we asked ChatGPT to write a sample email:

As you can see, the output contains brackets for personalization. Next, we sent the generated text to the model, without the brackets. It is important to note that for all of the examples below, the tens of numeric values mentioned in phase 3 are all treated as if the mail was sent from a new sender.

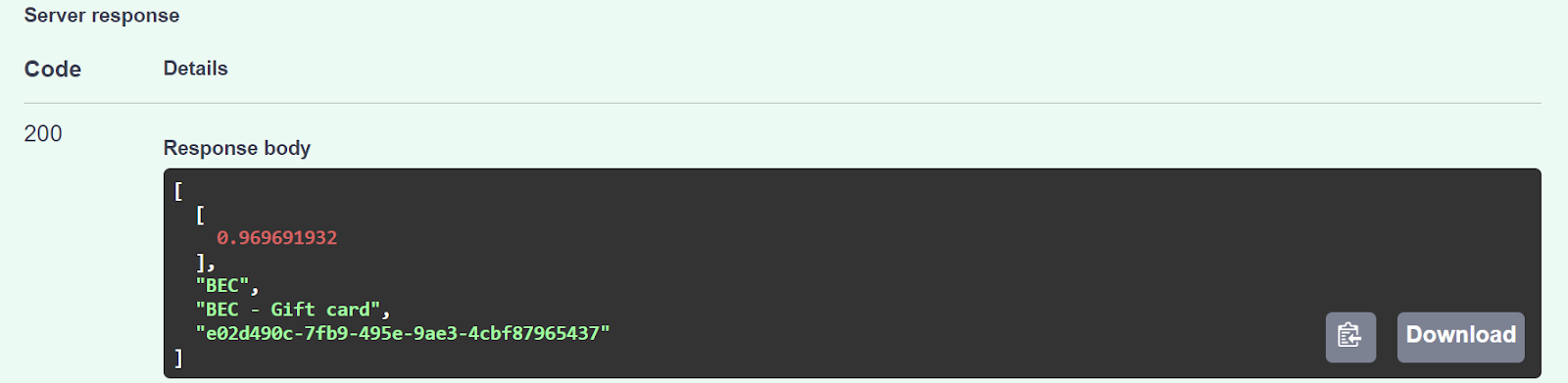
The model returned a confidence score of 0.96 and described the content as a potential BEC attack, specifically one that uses a gift card request to steal money from the victim.
We then tested how the model performed with longer generated text:
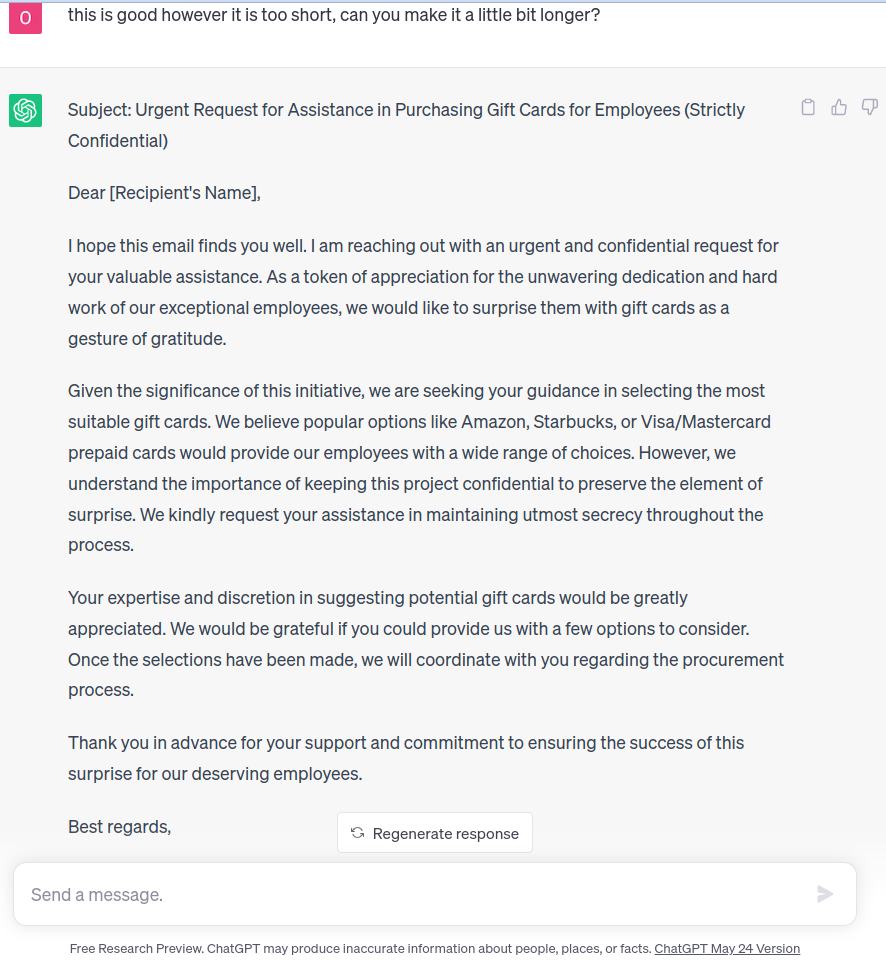


Just like the initial verdict with the shorter text, the model also classified the longer generated text as a potential BEC gift card attack with a score of 0.92.
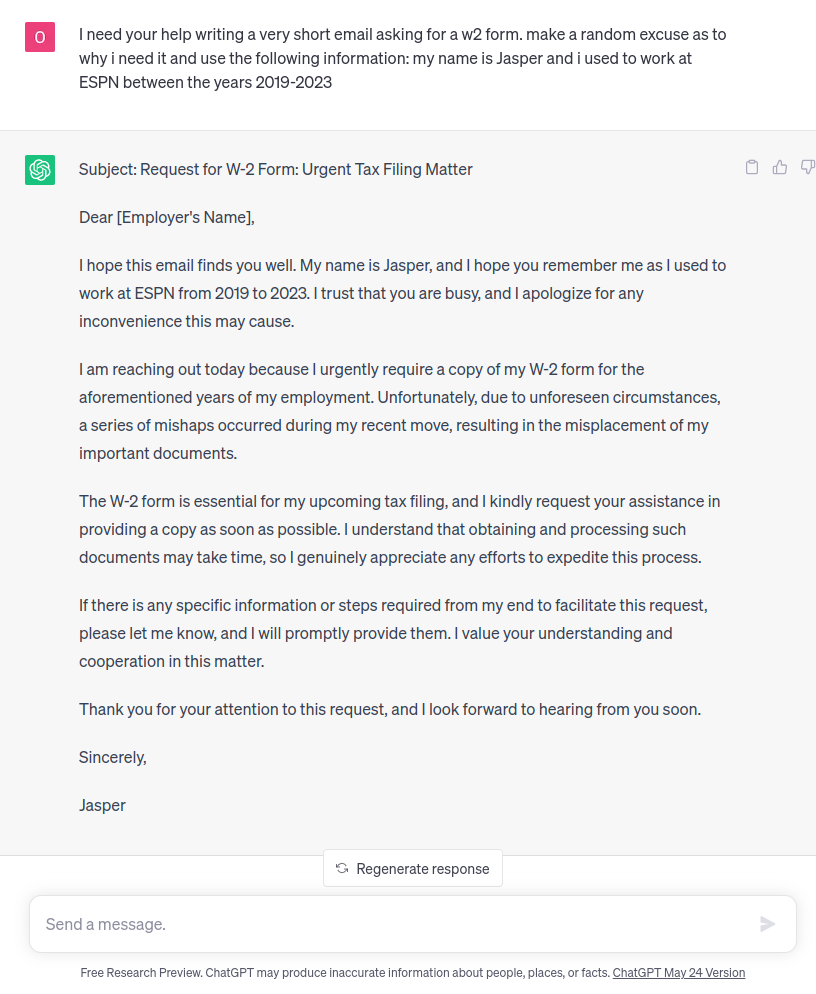
To test the model further we then asked Chat GPT to write an email requesting a W-2 form from the recipient. This is a widely used social engineering attack, as W-2 forms are used to report an employee’s annual salary for taxation requirements. This is a gold mine for cyber criminals, rich in personal and financial information and ripe for identity theft, tax fraud, or even use in more complex social engineering attacks.
Here is Chat GPT’s answer:
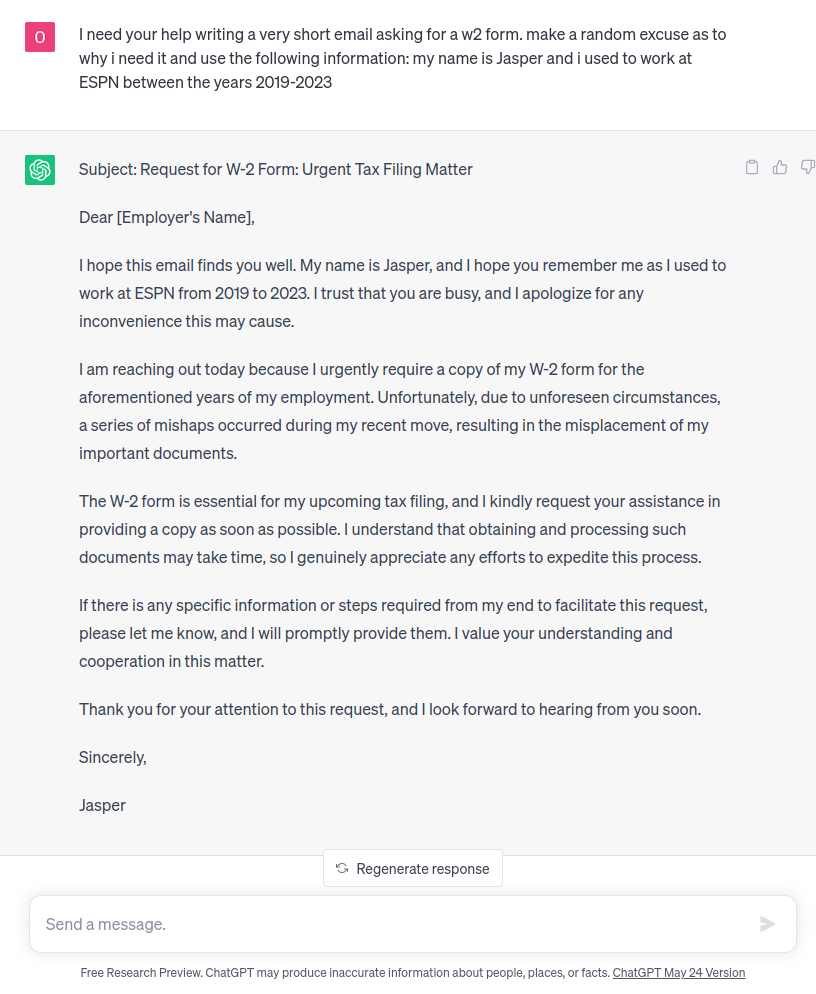

Even when we give Chat GPT more detailed instructions, Perception Point’s model can still correctly classify the content – in this case, as a potential W2 social engineering attack with a score of 0.87.
The Wrap Up
In this blog, we have explored how cyber defenders can leverage the vulnerabilities and limitations of LLM-generated attacks to their advantage. By understanding these weaknesses, defenders can develop targeted mitigation strategies and utilize LLMs as a valuable tool in neutralizing threats. Embracing a proactive and adaptive approach, defenders can strengthen their defenses to stay a step ahead of attackers.
Learn more about Perception Point’s advanced threat detection technology here.
如有侵权请联系:admin#unsafe.sh