从事移动安全行业以来,一直在做Android方面的安全及逆向,也曾想过了解下iOS的机制,奈何总是对自己下不了决心,一方面觉得精力有限,Android上好多东西自己也并没有完全熟练掌握。另一方面可能自己太懒,不太想花费太多时间成本,何况如果没有实操,所学的一切很快就会忘记,所以之前也仅仅是在心里埋下了这个种子而已。不过大概几周前,笔者实属有幸,因机缘巧合,向iOS逆向大佬猫大人好好请教了一番,至此也算是入了个iOS的小门。
在Android上通常用于逆向的手机是pixel/nexus系列,Android系统6~13都可,然后自己刷入magisk进行root。而iOS呢肯定是iPhone了,但是如何选系统如何自己越狱呢?因此在了解相关版本后,为了方便,在某宝买了一台二手的iphone8(800左右),ios14左右的系统,商家已经帮你越狱好了(unc0ver,14系统上每次手机重启还需点击软件进行越狱,不麻烦)。
当然其他手机也可以,按照大佬的建议,iOS系统最好不要最新,像13,14左右就可以,手机的话像年头久一点的iPhone 6(大概3,4百左右),iphone8/X/SE,也都可以做逆向。切记!买手机时要问有无id锁,是否可以刷机。如果手机来源不正规,自然就会被锁住,也不方便逆向用了。
手机选好后,自然就要安装一些相关软件,就像android逆向root之后要按各种插件,比如抓包用AlwaysTrustUserCerts信任证书之类的。iOS也是一样,iOS越狱后有个Cydia的商店,里边可以下载安装各种越狱插件,包括自己写的越狱开发插件也会在这里进行管理。
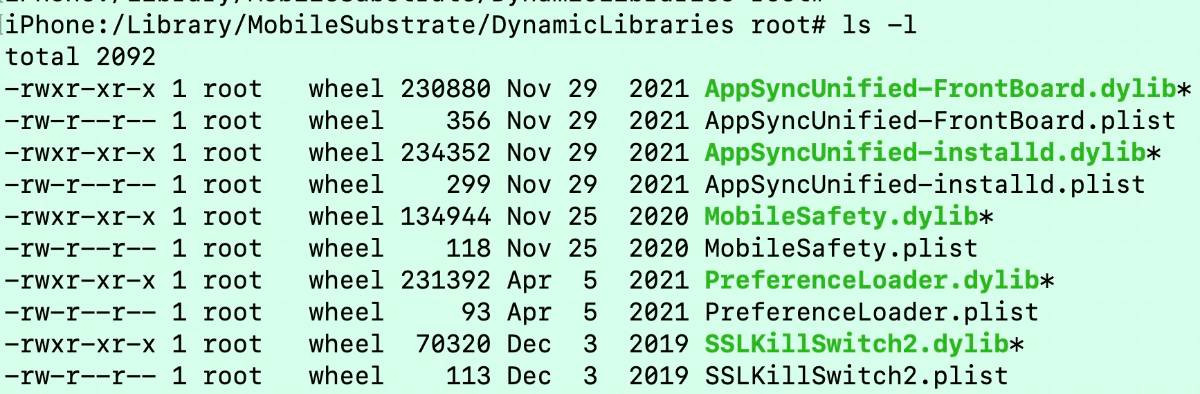
这里记录一下遇到过的问题,及一些杂项。比如手机越狱后,发现开不开机无法进入主界面,有可能是注入的插件有问题。可以通过ssh进入手机目录:$ ssh [email protected] -p 2222 ,默认密码是alpine。然后可以进入插件列表 cd /Library/MobileSubstrate/DynamicLibraries,这里是所有安装过的插件列表,比如我这里是这样的,也可以看到我这个二手手机可能也是用了好几年淘汰下来的

所以如果你怀疑哪个插件有问题,可以重命名这个插件,然后在上述目录重启系统进程:killall -9 SpringBoard; killall -9 backboard。
1
2
3
4
5
6
7
8
./dump.py com.xxx
Dumping xxx to /var/folders/rl/6nvyvpmj3z352q0m8xvm0db40000gn/T
[frida-ios-dump]: ZmFFmpeg.framework has been loaded.
[frida-ios-dump]: libswift_Concurrency.dylib has been dlopen.
...
libswift_Concurrency.dylib.fid: 100%|█████████████████████████████| 408k/408k [00:00<00:00, 5.97MB/s]
Validated.plist: 251MB [00:14, 18.2MB/s]
0.00B [00:00, ?B/s]Generating "xxx.ipa"
这里也使用class-dump将头文件导出class-dump -H ./osee2unifiedRelease.app/osee2unifiedRelease -o ./osee2unifiedReleaseH,导出头文件的作用是,方便我们查看OC中类的所有方法/属性
发现很多,随便找几个先看看,都是调用了同一个函数sub_1063DF0A8(),但是奇怪的是这个函数的第二个参数/api/account/prod/sign_in,在F5里并没有看到
但是在汇编里是能看到的,我不知道这样做的目的是什么,看了很多iOS逆向的帖子也没有看到这样的情况,或者说这是ida反混淆的问题?总之,这不重要。(如果有大佬知道,烦请解答)
然后通过回溯堆栈(console.log(Thread.backtrace(this.context, Backtracer.ACCURATE) .map(DebugSymbol.fromAddress).join('\n'));),看能否定位到关键信息。
1
2
3
4
5
6
7
8
9
0x106913598 osee2unifiedRelease!0x63d7598 (0x1063d7598)
0x1069131fc osee2unifiedRelease!0x63d71fc (0x1063d71fc)
0x1068e27d0 osee2unifiedRelease!0x63a67d0 (0x1063a67d0)
0x10690767c osee2unifiedRelease!0x63cb67c (0x1063cb67c)
0x1020724bc osee2unifiedRelease!0x1b364bc (0x101b364bc)
0x10207256c osee2unifiedRelease!0x1b3656c (0x101b3656c)
0x102061e10 osee2unifiedRelease!0x1b25e10 (0x101b25e10)
0x100608f90 osee2unifiedRelease!0xccf90 (0x1000ccf90)
0x1a0ec1298 libdispatch.dylib!_dispatch_call_block_and_release
1
2
var base = Module.getBaseAddress("osee2unifiedRelease");
console.log("base: ",base);
回溯出来堆栈之后,可以对整个堆栈链路的函数进行分析及hook,不过遗憾的是,或许是对iOS网络框架不熟,我并没有办法仅凭查找url,就能定位到加密算法。不过逆向有意思的地方也在这里,当一条路走不通了,放松下自己换一条。
经查资料,可以hook OC中NSData的base64EncodedStringWithOptions方法,在OC的语法中函数调用的方式可以用[类名 方法名:参数],hook的方式发现网上大多采用frida-trace。在我印象里好像没什么印象,即便有,也是听了个名词,因为在Android中我基本没用到过。于是使用这个命令进行hook,减号代表实例方法,相反加号代表类方法,只是个格式而已,也可以用*匹配
1
frida-trace -UF -m "-[NSData base64EncodedStringWithOptions:]"
这个脚本会在当前目录生成./__handlers__/文件夹,并生成对应函数的js代码,发现其实这就是Interceptor.attach的那个回调函数,只不过frida-trace帮你自动生成好了,方便你改脚本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
onEnter(log, args, state) {
this.self = args[0];
},
onLeave(log, retval, state) {
var before = ObjC.classes.NSString.alloc().initWithData_encoding_(this.self, 4);
var after = new ObjC.Object(retval);
log(`-[NSData base64EncodedStringWithOptions:]before=${before}=`);
log(`-[NSData base64EncodedStringWithOptions:]after=${after}=`);
if(after.toString().indexOf("sEn8t")>=0){
console.log(Thread.backtrace(this.context, Backtracer.ACCURATE) .map(DebugSymbol.fromAddress).join('\n'));
}
}
}
1
2
3
4
5
6
0x102e0a7d8 osee2unifiedRelease!+[ZHWhiteBoxEncryptTool encryptDataBase64String:]
0x102e0a6b8 osee2unifiedRelease!+[ZHWhiteBoxEncryptTool encryptData:]
0x10444b098 osee2unifiedRelease!+[NSURLRequest zh_whiteBoxEncryptRegisterLoginURLHTTPBody:]
0x10447c3f0 osee2unifiedRelease!+[ZHURLProtocol canonicalRequestForRequest:]
0x1a1863ffc CFNetwork!0x3ffc (0x180a47ffc)
...
进入[ encryptDataBase64String:]函数看看,发现密钥(93020...)是写死的360位的hex字符串(hex转换为bytes后长度是180)
1
2
3
4
void *__fastcall sub_106B3E2A0(void *a1, void *a2, void *a3, void *a4, void *a5)
{
return _objc_msgSend(a1, "preDataIn160:secureKey:iv:", a3, a4, a5);
}
1
2
3
4
void *__fastcall sub_106B1CA20(void *a1, void *a2, void *a3, void *a4, void *a5)
{
return _objc_msgSend(a1, "laesEncryptData:secureKey:iv:", a3, a4, a5);
}
1
2
3
4
void *__fastcall sub_106B3E2E0(void *a1, void *a2, void *a3, void *a4, void *a15)
{
return _objc_msgSend(a1, "preDataOut160:secureKey:iv:", a3, a4, a15);
}
这里的_objc_msgSend是OC底层通过发送消息,来进行函数调用的,其中a1是类,第二个参数是方法名,其余是参数。我们也可以到之前class-dump出来的头文件里看看,还是很清晰的
然后我们hook这个三个函数的入参和出参,就可以得到整个从明文到密文的加密链路。当然,这里需要注意的,虽然我们还是可以使用Android frida hook的方式(基址+偏移),但是我们打印参数时,却不能脱离OC的方式。
比如我们hook 这个函数laesEncryptData,即便我们知道真正的参数从a3开始(类似OC的调用约定吧,从第三个参数开始传参),但是我们像在Android那样,仅通过hexdump是无法打印出预期的值的。打印OC有点类似打印JNI,需要使用对应的方法,比如在输出a3时,可以先使用new ObjC.Object(this.arg2) 打印下对象,如果输出的类似这种{length = 32, bytes = 0x36666161 39316535 38616339 63346661 ... 37363438 38323730 } (如是字符串类型直接能输出)就可以使用Memory.readByteArray(data.bytes(),data.length()) 来进行hexdump了,其余的没什么区别。
1
id __cdecl +[BangcleCryptoTool laesEncryptData:secureKey:iv:](BangcleCryptoTool_meta *self, SEL a2, id a3, id a4, id a5)
在我们定位好关键算法之后,通常为了测试方便,往往是需要主动调用函数的,和Android无异。比如这个app,他总是有线程在做加密,即便把网关掉了也不行,这对于我们分析输出日志是很不方便的。我们可以通过Interceptor.replace函数替换掉某个方法,而我们自己主动调用时,调其内部的方法即可。
比如,我们这里分析到laesEncryptData函数内部会调用sub_1000902A8方法,这个sub_1000902A8方法内部会调用sub_100090420这个方法,因此我们可以主动调用sub_100090420,替换掉sub_1000902A8,就可以去除干扰(另两个函数preDataIn160,preDataOut160不是核心算法,也不复杂,这里不做过多阐述)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
__int64 __fastcall sub_1000902A8(__int64 a1, unsigned int a2, __int64 a3, __int64 a4, __int64 a5, unsigned int a6, __int64 a7, unsigned int a8, int a9)
{
v24 = a1;
v23 = a2;
v22 = a3;
v21 = a4;
v20 = a5;
v19 = a6;
a7a = a7;
a8a = a8;
v16 = a9;
LODWORD(v10) = 1;
HIDWORD(v10) = 4;
v14 = 1;
v15 = a9;
v12 = 1;
v13 = 0;
v11 = 0;
return sub_100090420(a1, a2, a3, (int *)a4, a5, a6, a7, a8, &v10);
}
1
2
3
4
5
6
function replace(){
var base = Module.getBaseAddress("osee2unifiedRelease");
Interceptor.replace(base.add(0x902A8),new NativeCallback(function(a,b,c,d,e,f,g,h,i){
return 0;
},'int',['pointer','int','pointer','int','pointer','int','pointer','int','pointer']));
}
当然,在这里我遇到了一点小坑,其实如上的反汇编代码是不准确的,该函数共有9个参数,根据arm64的调用约定,超过8个参数,会通过栈传递,也就是最后一个参数v10,并不是如伪代码那样直接传递的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
__text:00000001000902A8 sub_1000902A8
__text:00000001000902A8 STP X29, X30, [SP,
__text:00000001000902AC MOV X29, SP
__text:00000001000902B0 SUB SP, SP,
__text:00000001000902B4 LDR W8, [X29,
__text:00000001000902B8 ADD X9, SP,
__text:00000001000902BC MOV W10,
__text:00000001000902C0 MOV W11,
__text:00000001000902C4 STUR X0, [X29,
__text:00000001000902C8 STUR W1, [X29,
__text:00000001000902CC STUR X2, [X29,
__text:00000001000902D0 STUR X3, [X29,
__text:00000001000902D4 STUR X4, [X29,
__text:00000001000902D8 STUR W5, [X29,
__text:00000001000902DC STR X6, [SP,
__text:00000001000902E0 STR W7, [SP,
__text:00000001000902E4 STR W8, [SP,
__text:00000001000902E8 STR W10, [SP,
__text:00000001000902EC STR W11, [SP,
__text:00000001000902F0 STR W10, [SP,
__text:00000001000902F4 LDR W8, [SP,
__text:00000001000902F8 STR W8, [SP,
__text:00000001000902FC STR W10, [SP,
__text:0000000100090300 STR WZR, [SP,
__text:0000000100090304 STR WZR, [SP,
__text:0000000100090308 LDUR X0, [X29,
__text:000000010009030C LDUR W1, [X29,
__text:0000000100090310 LDUR X2, [X29,
__text:0000000100090314 LDUR X3, [X29,
__text:0000000100090318 LDUR X4, [X29,
__text:000000010009031C LDUR W5, [X29,
__text:0000000100090320 LDR X6, [SP,
__text:0000000100090324 LDR W7, [SP,
__text:0000000100090328 STR X9, [SP] ; a9 a9参数通过sp传递
__text:000000010009032C BL sub_100090420
__text:0000000100090330 MOV SP, X29
__text:0000000100090334 LDP X29, X30, [SP+var_s0],
__text:0000000100090338 RET
1
2
3
4
5
6
7
8
9
var dword = Memory.alloc(32);
Memory.writeUInt(dword,1);
Memory.writeUInt(dword.add(4),4);
Memory.writeUInt(dword.add(4*2),0);
Memory.writeUInt(dword.add(4*3),1);
Memory.writeUInt(dword.add(4*4),1);
Memory.writeUInt(dword.add(4*5),0);
Memory.writeUInt(dword.add(4*6),1);
Memory.writeUInt(dword.add(4*7),1);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
function call_aes(){
var base = Module.getBaseAddress("osee2unifiedRelease");
console.log("base: ",base);
var aes = new NativeFunction(base.add(0x90420),'int',['pointer','int','pointer','pointer','pointer','int','pointer','int','pointer']);
//输入
var data_len = 0x20;
const data = Memory.alloc(data_len);
Memory.writeByteArray(data,[0xca,0xcc,0x6e,0x68,0x64,0x63,0xc6,0x6e,0x60,0xc2,0x66,0xc4,0xc8,0x6c,0xc4,0xc6,0xca,0xc2,0x60,0xc4,0x6c,0x64,0x61,0x61,0x61,0xc4,0xc6,0xc4,0xc2,0xc8,0x6c,0x62]);
//输出:空的byte数组,函数返回后,有值
var result_len = 16 * (data_len / 16 + 1);
var result = Memory.alloc(result_len);
var result_len_ptr = Memory.alloc(Process.pointerSize);
result_len_ptr.writeUInt(result_len);
//iv
var iv_len = 0x10;
const iv = Memory.alloc(iv_len);
Memory.writeByteArray(iv,[0x4c,0x41,0xb2,0xc9,0xb4,0xba,0xff,0x8a,0x6a,0x69,0xa5,0x99,0x02,0x5f,0x03,0x15]);
//key
var key_len = 0xb4; //长度180
const key = Memory.alloc(key_len);
Memory.writeByteArray(key,[0x93,0x02,0x01,0x9f,0xbf,0xa1,0xbb,0x6b,0xdb,0x9f,0xca,0x46,0x84,0xb3,0xe7,0xf6,0x38,0x30,0x44,0x18,0x14,0x06,0x35,0x60,0x29,0x7e,0x4f,0x00,0xde,0x63,0x69,0x41,0x66,0x4f,0x7e,0xa3,0x94,0x29,0xb2,0x60,0x4e,0x4f,0x93,0xa7,0x84,0x0e,0xcf,0x12,0x54,0xcb,0xa8,0xd9,0xea,0x29,0xcd,0xf4,0xf7,0xe4,0x01,0x97,0xb5,0x0d,0xf7,0x7e,0x19,0xfb,0x07,0xf2,0xf9,0x74,0xe7,0x87,0xcf,0x87,0x32,0xa6,0x2a,0x1e,0x2e,0x0f,0xcb,0xfa,0x2a,0xcb,0xac,0x63,0x76,0xc8,0x32,0xc0,0x82,0x39,0xa0,0xb5,0xd9,0xe0,0xe7,0x06,0xeb,0x27,0xb8,0x31,0xe5,0xef,0xfc,0xdb,0x3d,0x00,0x08,0x7e,0x62,0xa6,0x02,0x92,0x31,0xf6,0x4a,0x2b,0x30,0x99,0x72,0x07,0x59,0xe3,0x1f,0x9d,0xfa,0x12,0x8b,0xc7,0xe9,0x6a,0x83,0xd7,0x1a,0xf7,0x9a,0xa4,0x89,0xb9,0xe5,0x6f,0xfd,0xd5,0xe2,0xf1,0x42,0xa3,0xf9,0xac,0x11,0xe4,0xab,0xce,0x01,0xc6,0xf2,0xfb,0xca,0x01,0xb7,0x59,0xac,0x84,0x2f,0x14,0x91,0xa1,0xa5,0x8d,0x74,0xea,0xdd,0x2b,0x38,0x09,0x1e,0xb8,0x21,0x16])
//最后一个参数
var dword = Memory.alloc(32);
Memory.writeUInt(dword,1);
Memory.writeUInt(dword.add(4),4);
Memory.writeUInt(dword.add(4*2),0);
Memory.writeUInt(dword.add(4*3),1);
Memory.writeUInt(dword.add(4*4),1);
Memory.writeUInt(dword.add(4*5),0);
Memory.writeUInt(dword.add(4*6),1);
Memory.writeUInt(dword.add(4*7),1);
//主动调用
var aes_r = aes(data,data_len,result,result_len_ptr,iv,iv_len,key,key_len,dword);
console.log("aes_r",aes_r,hexdump(result,{length:result_len}));
}
在我们正式分析魔改的aes算法之前,我想应该是要介绍下aes标准算法的原理,就当是回顾下知识点,所以这一节可能会比较枯燥,不过这里还是只介绍下相关的概念,不会太深入细节。因此这一节可以粗略的过下,甚至跳过,后面的内容如果迷惑了,可以返回来看看。下面我们大概概述下标准AES算法的加密流程。
其中初始变换只执行AddRoundKey,算法循环第1~9轮依次执行SubBytes,ShiftRows,MixColumns,AddRoundKey。最终轮(第10轮)不包含MixColumns。算法完毕
分别对sub_100090420进行函数/指令trace,首先看下function trace,发现调用的函数并不多,这里先将关键函数的作用写出,后续将详细分析该算法是如何魔改aes的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
function trace:
[函数地址]([调用地址]) -- 调用层级
[0x100091054]( [0x10009047c] ) -- 0 //1. 密钥编排后的处理
[0x106a9b340]( [0x100091074] ) -- 1 //malloc
[0x100091b3c]( [0x100090520] ) -- 0
[0x100091bcc]( [0x100090548] ) -- 0
[0x106a9a530]( [0x100090614] ) -- 0 //calloc
[0x106a9a1e8]( [0x10009062c] ) -- 0 //memcpy
[0x100091c7c]( [0x100090664] ) -- 0 //类似pkcs填充
[0x106a9a1f4]( [0x100091cf8] ) -- 1 //使用memset进行填充
[0x106a9a1f4]( [0x100091d6c] ) -- 1 //使用memset进行填充
[0x100094360]( [0x100090b18] ) -- 0 //2.关键函数,CBC模式,明文异或
[0x100091fac]( [0x10009440c] ) -- 1 //3.真正魔改aes的加密,测试时输出明文为32个字节,通过填充后,输出为48个字节,且aes128每轮循环加密16字节,故48/16=3,0x100091fac函数循环3轮
[0x100091fac]( [0x10009440c] ) -- 1
[0x100091fac]( [0x10009440c] ) -- 1
[0x106a9aaa0]( [0x100091038] ) -- 0 //free
[0x100091ef4]( [0x100091040] ) -- 0
[0x106a9aaa0]( [0x100091f18] ) -- 1 //free
通过function trace打印了函数执行流程后,可以查看密文result的交叉引用,并hook相关函数(从function trace来看并不多),打印输入输出,最终定位到了这里
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
__int64 __fastcall sub_100094360(__int64 a1, __int64 a2, int a3, __int64 a4, __int64 a5, void (__fastcall *a6)(__int64, __int64, __int64, unsigned int *))
{
__int64 iv_1; // [xsp+0h] [xbp-40h]
signed int i; // [xsp+8h] [xbp-38h]
unsigned int v9; // [xsp+Ch] [xbp-34h]
void (__fastcall *v10)(__int64, __int64, __int64); // [xsp+10h] [xbp-30h]
__int64 keyptr; // [xsp+18h] [xbp-28h]
__int64 iv; // [xsp+20h] [xbp-20h]
int result_len; // [xsp+2Ch] [xbp-14h]
__int64 result; // [xsp+30h] [xbp-10h]
__int64 data; // [xsp+38h] [xbp-8h]
data = a1;
result = a2;
result_len = a3;
iv = a4;
keyptr = a5;
v10 = a6;
v9 = 0;
iv_1 = a4;
while ( result_len >= 16 )
{
for ( i = 0; i < 16; ++i )
*(result + i) = *(data + i) ^ *(iv_1 + i);
(v10)(result, result, keyptr, &v9); // aes加密算法
iv_1 = result;
result_len -= 16;
data += 16LL;
result += 16LL;
}
return v9;
}
发现这个函数将result分割16个字节,每次循环首先将明文与iv异或并作为sub_100091FAC(v10)的参数,调用完后,将结果重新赋值给iv,并进行下一轮循环。
这里其实就是分组密码常见的CBC模式,因为aes也是分组密码,在进行加密之前,先将明文分组,如果不够分了,就进行相应规则填充数据。过程就是将明文分组与前一个密文分组进行XOR异或运算,首轮的话就与iv异或,上述代码ida反编译的很好了,对照下图,应该就可以理解了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
__int64 __fastcall sub_100091FAC(__int64 result, __int64 a2, __int64 *key2)
{
int v3; // w9
signed int i; // [xsp+14h] [xbp-6Ch]
signed int k; // [xsp+14h] [xbp-6Ch]
signed int l; // [xsp+14h] [xbp-6Ch]
signed int m; // [xsp+14h] [xbp-6Ch]
signed int n; // [xsp+14h] [xbp-6Ch]
signed int ii; // [xsp+14h] [xbp-6Ch]
int j; // [xsp+18h] [xbp-68h]
__int64 key2_1; // [xsp+20h] [xbp-60h]
char v12; // [xsp+48h] [xbp-38h]
char v13; // [xsp+49h] [xbp-37h]
char v14; // [xsp+4Ah] [xbp-36h]
char v15; // [xsp+4Bh] [xbp-35h]
char v16; // [xsp+4Ch] [xbp-34h]
char v17; // [xsp+4Dh] [xbp-33h]
char v18; // [xsp+4Eh] [xbp-32h]
char v19; // [xsp+4Fh] [xbp-31h]
char v20; // [xsp+50h] [xbp-30h]
char v21; // [xsp+51h] [xbp-2Fh]
char v22; // [xsp+52h] [xbp-2Eh]
char v23; // [xsp+53h] [xbp-2Dh]
char v24; // [xsp+54h] [xbp-2Ch]
char v25; // [xsp+55h] [xbp-2Bh]
char v26; // [xsp+56h] [xbp-2Ah]
char v27; // [xsp+57h] [xbp-29h]
char v28; // [xsp+58h] [xbp-28h]
char v29; // [xsp+59h] [xbp-27h]
char v30; // [xsp+5Ah] [xbp-26h]
char v31; // [xsp+5Bh] [xbp-25h]
char v32; // [xsp+5Ch] [xbp-24h]
char v33; // [xsp+5Dh] [xbp-23h]
char v34; // [xsp+5Eh] [xbp-22h]
char v35; // [xsp+5Fh] [xbp-21h]
char v36; // [xsp+60h] [xbp-20h]
char v37; // [xsp+61h] [xbp-1Fh]
char v38; // [xsp+62h] [xbp-1Eh]
char v39; // [xsp+63h] [xbp-1Dh]
char v40; // [xsp+64h] [xbp-1Ch]
char v41; // [xsp+65h] [xbp-1Bh]
char v42; // [xsp+66h] [xbp-1Ah]
char v43; // [xsp+67h] [xbp-19h]
unsigned __int8 v44; // [xsp+68h] [xbp-18h]
unsigned __int8 v45; // [xsp+69h] [xbp-17h]
unsigned __int8 v46; // [xsp+6Ah] [xbp-16h]
unsigned __int8 v47; // [xsp+6Bh] [xbp-15h]
unsigned __int8 v48; // [xsp+6Ch] [xbp-14h]
unsigned __int8 v49; // [xsp+6Dh] [xbp-13h]
unsigned __int8 v50; // [xsp+6Eh] [xbp-12h]
unsigned __int8 v51; // [xsp+6Fh] [xbp-11h]
unsigned __int8 v52; // [xsp+70h] [xbp-10h]
unsigned __int8 v53; // [xsp+71h] [xbp-Fh]
unsigned __int8 v54; // [xsp+72h] [xbp-Eh]
unsigned __int8 v55; // [xsp+73h] [xbp-Dh]
unsigned __int8 v56; // [xsp+74h] [xbp-Ch]
unsigned __int8 v57; // [xsp+75h] [xbp-Bh]
unsigned __int8 v58; // [xsp+76h] [xbp-Ah]
unsigned __int8 v59; // [xsp+77h] [xbp-9h]
key2_1 = *key2;
v3 = *(key2 + 4) + (*(key2 + 4) < 0 ? 0x1F : 0);
for ( i = 0; i < 16; ++i )
*(&v44 + i) = (byte_106EF9068[*(key2_1 + i) & 0xF ^ 16 * (*(result + i) & 0xF)] >> 4) & 0xF ^ 16
* ((byte_106EF9068[(*(key2_1 + i) >> 4) & 0xF ^ 16 * ((*(result + i) >> 4) & 0xF)] >> 4) & 0xF);
for ( j = 1; j < (v3 >> 5) + 6; ++j )
{
v28 = dword_106EF9168[v44] >> 24;
v29 = dword_106EF9168[v44] >> 16;
v30 = LOWORD(dword_106EF9168[v44]) >> 8;
v31 = dword_106EF9168[v44];
v32 = dword_106EF9168[v48] >> 24;
v33 = dword_106EF9168[v48] >> 16;
v34 = LOWORD(dword_106EF9168[v48]) >> 8;
v35 = dword_106EF9168[v48];
v36 = dword_106EF9168[v52] >> 24;
v37 = dword_106EF9168[v52] >> 16;
v38 = LOWORD(dword_106EF9168[v52]) >> 8;
v39 = dword_106EF9168[v52];
v40 = dword_106EF9168[v56] >> 24;
v41 = dword_106EF9168[v56] >> 16;
v42 = LOWORD(dword_106EF9168[v56]) >> 8;
v43 = dword_106EF9168[v56];
v12 = dword_106EF9568[v49] >> 24;
v13 = dword_106EF9568[v49] >> 16;
v14 = LOWORD(dword_106EF9568[v49]) >> 8;
v15 = dword_106EF9568[v49];
v16 = dword_106EF9568[v53] >> 24;
v17 = dword_106EF9568[v53] >> 16;
v18 = LOWORD(dword_106EF9568[v53]) >> 8;
v19 = dword_106EF9568[v53];
v20 = dword_106EF9568[v57] >> 24;
v21 = dword_106EF9568[v57] >> 16;
v22 = LOWORD(dword_106EF9568[v57]) >> 8;
v23 = dword_106EF9568[v57];
v24 = dword_106EF9568[v45] >> 24;
v25 = dword_106EF9568[v45] >> 16;
v26 = LOWORD(dword_106EF9568[v45]) >> 8;
v27 = dword_106EF9568[v45];
for ( k = 0; k < 16; ++k )
*(&v28 + k) = (byte_106EF9968[*(&v12 + k) & 0xF ^ 16 * (*(&v28 + k) & 0xF)] >> 4) & 0xF ^ 16
* ((byte_106EF9968[(*(&v12 + k) >> 4) & 0xF ^ 16 * ((*(&v28 + k) >> 4) & 0xF)] >> 4) & 0xF);
v12 = dword_106EF9A68[v54] >> 24;
v13 = dword_106EF9A68[v54] >> 16;
v14 = LOWORD(dword_106EF9A68[v54]) >> 8;
v15 = dword_106EF9A68[v54];
v16 = dword_106EF9A68[v58] >> 24;
v17 = dword_106EF9A68[v58] >> 16;
v18 = LOWORD(dword_106EF9A68[v58]) >> 8;
v19 = dword_106EF9A68[v58];
v20 = dword_106EF9A68[v46] >> 24;
v21 = dword_106EF9A68[v46] >> 16;
v22 = LOWORD(dword_106EF9A68[v46]) >> 8;
v23 = dword_106EF9A68[v46];
v24 = dword_106EF9A68[v50] >> 24;
v25 = dword_106EF9A68[v50] >> 16;
v26 = LOWORD(dword_106EF9A68[v50]) >> 8;
v27 = dword_106EF9A68[v50];
for ( l = 0; l < 16; ++l )
*(&v28 + l) = (byte_106EF9968[*(&v12 + l) & 0xF ^ 16 * (*(&v28 + l) & 0xF)] >> 4) & 0xF ^ 16
* ((byte_106EF9968[(*(&v12 + l) >> 4) & 0xF ^ 16 * ((*(&v28 + l) >> 4) & 0xF)] >> 4) & 0xF);
v12 = dword_106EF9E68[v59] >> 24;
v13 = dword_106EF9E68[v59] >> 16;
v14 = LOWORD(dword_106EF9E68[v59]) >> 8;
v15 = dword_106EF9E68[v59];
v16 = dword_106EF9E68[v47] >> 24;
v17 = dword_106EF9E68[v47] >> 16;
v18 = LOWORD(dword_106EF9E68[v47]) >> 8;
v19 = dword_106EF9E68[v47];
v20 = dword_106EF9E68[v51] >> 24;
v21 = dword_106EF9E68[v51] >> 16;
v22 = LOWORD(dword_106EF9E68[v51]) >> 8;
v23 = dword_106EF9E68[v51];
v24 = dword_106EF9E68[v55] >> 24;
v25 = dword_106EF9E68[v55] >> 16;
v26 = LOWORD(dword_106EF9E68[v55]) >> 8;
v27 = dword_106EF9E68[v55];
for ( m = 0; m < 16; ++m )
*(&v28 + m) = (byte_106EF9968[*(&v12 + m) & 0xF ^ 16 * (*(&v28 + m) & 0xF)] >> 4) & 0xF ^ 16
* ((byte_106EF9968[(*(&v12 + m) >> 4) & 0xF ^ 16 * ((*(&v28 + m) >> 4) & 0xF)] >> 4) & 0xF);
for ( n = 0; n < 16; ++n )
*(&v44 + n) = (byte_106EF9968[*(key2_1 + n + 16 * j) & 0xF ^ 16 * (*(&v28 + n) & 0xF)] >> 4) & 0xF ^ 16 * ((byte_106EF9968[(*(key2_1 + n + 16 * j) >> 4) & 0xF ^ 16 * ((*(&v28 + n) >> 4) & 0xF)] >> 4) & 0xF);
}
v28 = byte_106EFA268[v44];
v29 = byte_106EFA268[v49];
v30 = byte_106EFA268[v54];
v31 = byte_106EFA268[v59];
v32 = byte_106EFA268[v48];
v33 = byte_106EFA268[v53];
v34 = byte_106EFA268[v58];
v35 = byte_106EFA268[v47];
v36 = byte_106EFA268[v52];
v37 = byte_106EFA268[v57];
v38 = byte_106EFA268[v46];
v39 = byte_106EFA268[v51];
v40 = byte_106EFA268[v56];
v41 = byte_106EFA268[v45];
v42 = byte_106EFA268[v50];
v43 = byte_106EFA268[v55];
for ( ii = 0; ii < 16; ++ii )
*(a2 + ii) = (byte_106EFA368[*(key2_1 + ii + 16 * j) & 0xF ^ 16 * (*(&v28 + ii) & 0xF)] >> 4) & 0xF ^ 16 * ((byte_106EFA368[(*(key2_1 + ii + 16 * j) >> 4) & 0xF ^ 16 * ((*(&v28 + ii) >> 4) & 0xF)] >> 4) & 0xF);
return result;
}
其实逆向到这里,我一直怀疑着,就是bangcle算法究竟把aes魔改到什么程度?虽然最外层的算法名写的是laes,而且上层函数也的确明文分组与iv异或,并且根据trace及分析来看,中间也的确是9轮循环。那么他是否仅仅改了码表而已?还是说不仅改了码表,甚至连aes内部算法也重写了?我能否对照标准的aes来还原他?以及他的key为什么是180位,而标准的aes仅仅是16位,又如何用key呢?带着这些个疑问,我开始了进入了使用trace还原算法的世界。
1
2
3
4
key2_1 = *key2;
v3 = *(key2 + 4) + (*(key2 + 4) < 0 ? 0x1F : 0); //(1)
for ( i = 0; i < 16; ++i ) //(2)
*(&v44 + i) = (byte_106EF9068[*(key2_1 + i) & 0xF ^ 16 * (*(result + i) & 0xF)] >> 4) & 0xF ^ 16 * ((byte_106EF9068[(*(key2_1 + i) >> 4) & 0xF ^ 16 * ((*(result + i) >> 4) & 0xF)] >> 4) & 0xF);
那这里判断算法是否输出正确,有两种方式。首先是传统的方式,这个循环里最后生成的值是*(&v44 + i),而这个值最终是通过异或得来,因此我们查看ida里汇编的地址
第二种方式,得益于frida stalker在trace时可以定制化输出,比如在大佬的trace脚本中,我们可以将readCString()改成hexdump出了两行内容
于是我们也可以直接去trace搜整个for循环的结果4c da e9 c4 5a a1 0f 28 1e a2 01 ed 5b b6 62 b9,发现内存里有很多地方都有,也即证明了此步还原准确。
接下来,又进入了一个大循环中for ( j = 1; j < (v3 >> 5) + 6; ++j ) 因为上一步中已经还原出v3=0x80,因此手动计算下(v3 >> 5) + 6 = (0x80 >> 5) + 6 = 10。也即aes标准算法中的9轮循环。
首先就是,这一部分代码里,无论是输入还是输出都是局部变量。比如像这一行还好说v28 = dword_106EF9168[v44] >> 24; v44也就是上一个算法的结果,但v28是谁呢?甚至于下一个4组v32 = dword_106EF9168[v48] >> 24; v32,v48都是局部变量,这又该如何还原呢?
1
2
3
4
5
6
//trace日志
[0x100092118] 0x104c42118 lsr w10, w10,
...
[0x100092138] 0x104c42138 lsr w10, w10,
[0x10009213c] 0x104c4213c and w10, w10,
...
我尝试将v48认为是v44+1的值(0xda)来进行计算(v44 = 4c da e9 c4 5a a1 0f 28 1e a2 01 ed 5b b6 62 b9,最最初计算的16字节的结果,在第一组v44等于4c),但遗憾的是我得出来的值却无法与trace结果相对应
我计算出来的v32/v33是0x18/0x67,但trace的结果却是0x2d/0x37 ??? 看来事情并没有我所猜测这么简单。于是分析trace,看看值是怎么来的。
1
2
3
4
5
6
7
8
9
10
11
12
13
//trace结果
[0x100092188] 0x104c42188 ldurb w10, [x29,
[0x10009218c] 0x104c4218c mov x11, x10;
[0x100092190] 0x104c42190 orr x12, xzr,
[0x100092194] 0x104c42194 mul x11, x11, x12;
[0x100092198] 0x104c42198 add x11, x9, x11;
10baa92d0 af 37 37 2d fa 73 73 d2 3e c7 c7 48 d3 a4 a4 0c .77-.ss.>..H....
10baa92e0 ff 77 77 dd 59 51 51 5e d1 8b 8b 4d 10 52 52 16 .ww.YQQ^...M.RR.),
[0x10009219c] 0x104c421bc ldr w10, [x11];
[0x1000921a0] 0x104c421a0 lsr w10, w10,
...
[0x1000921c0] 0x104c421c0 lsr w10, w10,
[0x1000921c4] 0x104c421c4 and w10, w10,
发现两个值都是从0x2d3737af偏移而来,而0x2d3737af也是魔改后码表里的值dword_106EF9168[v48]; ,也就是说真正要看的是v48如何等于5a。跟到5a最初被赋值的地方ldurb w10, [x29, #-0x14]; # x10: 0x6d --> 0x5a 发现是从x29-0x14的地方取值,按正常逻辑,只要搜,谁往[x29, #-0x14]的地方赋值就行,不过trace里搜不到。所以到这里差不多就比较懵,值跟不下去了。
于是我又换了另一种猜想,如果v44不是一个char数组呢?假设他是一个int指针,那么如果v48=*(v44+1),那么v48的值应该是v44往后偏移4个字节,于是查看完整的v44: 4c da e9 c4 5a a1 0f 28 1e a2 01 ed 5b b6 62 b9,第一个值是4c没问题,第一个四组验证过了。如果按照刚刚的猜想,往后偏移4个字节,那么v48应该是?5a!发现对上了!那赶紧趁热打铁,验证接下来的两个值是不是1e和5b,也就是v49=1e,v50=5b。查看下trace
1
2
3
4
5
6
//trace
[0x100092210] 0x104c42210 ldurb w10, [x29,
[0x100092214] 0x104c42214 mov x11, x10;
...
[0x1000922b8] 0x104c422b8 ldurb w10, [x29,
[0x1000922bc] 0x104c422bc mov x11, x10;
1
2
3
4
5
6
7
8
//trace 码表的index
[0x100092320] 0x104c42320 ldurb w10, [x29,
...
[0x1000923a8] 0x104c423a8 ldurb w10, [x29,
...
[0x100092430] 0x104c42430 ldurb w10, [x29,
...
[0x1000924b8] 0x104c424b8 ldurb w10, [x29,
我们最初介绍了aes的标准流程时,提到了aes的内部小算法,这个就是行移位算法。aes将16个字节先看成是一个4*4的矩阵,然后分别对矩阵进行变化,所谓的行移位算法也是固定的一种模式,如下图
也就是说,我们这16个字节真正的使用方式是,先进行ShiftRows行移位,然后在进行SubBytes字节替换(魔改码表里取值),这也是bangcle_laes的一个混合小算法。
1
2
3
4
5
6
7
8
//clion算法还原部分
uint8_t *shiftp = (uint8_t *)*v44;
uint8_t state[4][4] = {0};
//转成二维数组state
convert_array(shiftp,state);
///进行行移位
ShiftRow(state);
uint8_t * p = (uint8_t *)state;
1
2
3
4
5
(lldb) x *v44
0x1327041c0: 4c da e9 c4 5a a1 0f 28 1e a2 01 ed 5b b6 62 b9 L���Z�.(.�.�[�b�
-->
(lldb) x p
0x16f18b2a8: 4c 5a 1e 5b a1 a2 b6 da 01 62 e9 0f b9 c4 28 ed LZ.[����.b�.��(�
其实到这里,虽说算法还原成功,但是过程却极其艰难。我也抱怨过ida里为什么不把算法的过程表现出来呢?看来还是ida反汇编有问题?这确实是我当时的疑惑。后来与Virenz大佬讨论一番,发现并不是ida没有表现,而是因为你并不理解ida的"想法"。
回过头来看,发现ida早已清清楚楚的告诉了你,虽然他不能精准的将代码全部还原,仅仅以一些局部变量表示。但是他会告诉你他反汇编的内在逻辑。比如上图中可分为两块,v28~v43这16个字段是顺序的,通过结果来看其在内存中也是连续的,也即可以表示为一个数组。
1
v44 v45 v46 v47 v48 v49 v50 v51 v52 v53 v53 v55 v56 v57 v58 v59
1
2
(lldb) x result
0x1327047b0: 77 1a 85 29 14 b6 3c 51 c5 5c b2 2d 52 19 ce 73 w..).�<Q�\�-R.�s
通过上边的分析,发现这个bangcle的AES魔改的很厉害,基本就是一个AES的架子,内部已经完全混乱了。其次还有他的密钥key我们还没有分析,也在这里说明下。我们都知道,正常的AES key是16位的,他的主要作用就是在AES算法中进行AddRoundKey(轮密钥加)的过程。
AddRoundKey的算法就是将16字节的“输入”与16字节子密钥进行异或得到输出数据,而子密钥的获取是通过密钥拓展编排算法得来(密钥编排算法就不做过多介绍,较复杂)。从之前的AES算法流程中也可以看到,从初始变换到10轮加密计算,总共用到了11次AddRoundKey,也就是说,密钥扩展编排后,总共会占11*16=176个字节的内存空间。
而bangcle的AES原本传入的密钥就是180位的,也可以说,他把密钥编排的算法前移了。那可能有小伙伴就问了,你不是说密钥编排后,总共是176位吗,那多出来的4位呢?其实在进行加密算法前,他也对密钥key进行了处理。我们看下相关的计算
可以清楚的看到,他key的前4位( key[i%3] )实际上是用于"解密"后边176位的密钥,也就是说原始的key实际是加密(异或)过的。这样做的目的,我也只是有个猜想,那就是他解密后的176字节的key真的是用密钥编排算法算出来的,而不是没有规则的key。因为密钥编排算法编出来的子密钥,实际上是能逆推出主密钥的,有兴趣的小伙伴可以去了解下DFA差分故障攻击的原理,也是会用到这一点。
到这里,本文也已经结束了,也许各位已经看的很累了,但总之还是希望对你有所帮助!本文的样本相信仔细看的小伙伴都能看出是哪个app,想练手的话就在AppStore下载最新版就行。
如有侵权请联系:admin#unsafe.sh