cckuailong
读完需要
速读仅需 4 分钟
1
行业词汇是对于行业的定义。
为什么是这些词,以及对于词汇的定义,很有讲究。
A16z 6 月 21 日,推出 ai 词汇宝典,包含了 100 个高频词汇。看看有没有你不知道的?
2
Accelerator(加速器):一种专为加速 AI 应用而设计的微处理器。
Agents(代理):能够独立并主动执行某些任务的软件,无需人类干预。
AGI (Artificial General Intelligence,人工通用智能):微软的研究人员已将 AGI 定义为在任何智力任务上都能与人类匹敌的人工智能。
Alignment(对齐):确保 AI 系统的目标与人类价值观相符的任务。
ASI (Artificial Super Intelligence,人工超级智能):尽管存在争议,ASI 通常被定义为超越人类思维能力的人工智能。
Attention(注意力机制):在神经网络的上下文中,注意力机制帮助模型在产生输出时专注于输入的相关部分。
Back Propagation(反向传播):在训练神经网络中常用的一种算法,指计算损失函数相对于网络权重的梯度的方法。
Bias(偏见):AI 模型对数据做出的假设。"偏见方差权衡"是需要达成的平衡,即模型对数据的假设和模型的预测在不同训练数据下的变化程度之间的平衡。
Chain of Thought(思维链条):在 AI 中,这个术语通常用来描述 AI 模型用来做出决策的一系列推理步骤。
Chatbot(聊天机器人):一种通过文本或语音交互模拟人类对话的计算机程序。聊天机器人通常使用自然语言处理技术来理解用户输入并提供相关的回应。
ChatGPT(ChatGPT):OpenAI 开发的一种大规模的 AI 语言模型,可以生成类人的文本。
CLIP (Contrastive Language–Image Pretraining,对比语言-图像预训练):OpenAI 开发的一种 AI 模型,可以连接图像和文本,使其能够理解和生成图像的描述。
Compute(计算):在训练或运行 AI 模型中使用的计算资源(如 CPU 或 GPU 时间)。
Convolutional Neural Network (CNN,卷积神经网络):一种深度学习模型,通过应用一系列过滤器来处理具有网格状拓扑结构的数据(例如,图像)。这样的模型通常用于图像识别任务。
Data Augmentation(数据增强):通过添加对现有数据的轻微修改的副本,增加用于训练模型的数据量和多样性的过程。
Deep Learning(深度学习):机器学习的一个子领域,专注于训练具有多层的神经网络,从而实现复杂模式的学习。
Diffusion(扩散):在 AI 和机器学习中,一种通过开始使用一部分真实数据并添加随机噪声来生成新数据的技术。扩散模型是一种生成模型,在该模型中,神经网络被训练以预测当随机噪声被添加到数据时的反向过程。扩散模型被用来生成与训练数据相似的新数据样本。
Double Descent(双下降):机器学习中的一种现象,其中模型性能随着复杂性的增加而提高,然后恶化,然后再次提高。
Embedding(嵌入):数据的新型表示,通常是向量空间。相似的数据点具有更相似的嵌入。
Emergence/Emergent Behavior (“sharp left turns,” intelligence explosions,出现/新兴行为[“急转弯”,智力爆炸]):在 AI 中,新兴行为指的是从简单的规则或交互中产生的复杂行为。“急转弯”和“智力爆炸”是 AI 发展突然并急剧变化的推测性场景,通常与 AGI 的到来有关。
End-to-End Learning(端到端学习):一种机器学习模型,无需手动设计特征。模型只需输入原始数据,并从这些输入中学习。
Expert Systems(专家系统):应用人工智能技术为特定领域内的复杂问题提供解决方案。
Explainable AI (XAI,可解释 AI):专注于创建提供明确和可理解的决策解释的透明模型的 AI 子领域。
Fine-tuning(微调):采取一个已经在大数据集上预训练的模型,然后在特定的、更小的数据集上进行二次训练以适应特定的任务或问题。
Forward Propagation(正向传播):在神经网络中,正向传播是将输入数据输入到网络并通过每一层(从输入层到隐藏层,最后到输出层)传递以产生输出的过程。网络应用权重和偏置到输入,并使用激活函数生成最终输出。
Foundation Model(基础模型):在广泛数据上训练的大型 AI 模型,用于适应特定任务。
General Adversarial Network (GAN,生成对抗网络):一种用于生成与某些现有数据相似的新数据的机器学习模型。它将两个神经网络互相对抗:一个“生成器”创建新数据,一个“判别器”试图区分该数据和真实数据。
Generative AI(生成型 AI):一个专注于创建可以基于现有数据的模式和示例生成新的、原创的内容(如图像、音乐或文本)的模型的 AI 分支。
GPT (Generative Pretrained Transformer,GPT,生成预训练变压器):由 OpenAI 开发的大型 AI 语言模型,可以生成类似人类的文本。
GPU (Graphics Processing Unit,GPU,图形处理单元):一种专用的微处理器类型,主要设计用于快速渲染图像以输出到显示器。GPU 还非常有效地执行训练和运行神经网络所需的计算。
Gradient Descent(梯度下降):在机器学习中,梯度下降是一种优化方法,通过根据其损失函数的最大改善方向逐渐调整模型的参数。例如,在线性回归中,梯度下降通过反复调整线的斜率和截距来寻找最佳拟合线,以最小化预测错误。
Hallucinate/Hallucination (幻觉/幻想):在 AI 的上下文中,幻想指的是模型生成的内容不基于实际数据或与现实大相径庭的现象。
Hidden Layer (隐藏层):在神经网络中,隐藏层是人工神神经元的层,这些神经元并未直接连接到输入或输出。
Hyperparameter Tuning (超参数调优):选择机器学习模型的超参数(数据未学习的参数)的适当值的过程。
Inference (推理):用已训练的机器学习模型进行预测的过程。
Instruction Tuning (指令调优):一种机器学习技术,其中模型根据数据集中给出的特定指令进行微调。
Large Language Model (LLM,大型语言模型):一种可以生成类人类文本的 AI 模型,训练在广泛的数据集上。
Latent Space (潜在空间):在机器学习中,这个术语指的是模型(如神经网络)创建的数据的压缩表示。相似的数据点在潜在空间中更接近。
Loss Function (or Cost Function,损失函数或成本函数):机器学习模型在训练期间试图最小化的函数。它量化了模型预测与真实值的差距。
Machine Learning (机器学习):一种人工智能类型,使系统能够在无需明确编程的情况下自动学习并从经验中改进。
Mixture of Experts (专家混合):一种机器学习技术,其中训练了几个专门的子模型(“专家”),并且他们的预测是以取决于输入的方式组合的。
Multimodal (多模态):在 AI 中,这指的是可以理解和生成跨多种数据类型(如文本和图像)的信息的模型。
Natural Language Processing (NLP,自然语言处理):一个关注计算机和人类通过自然语言进行交互的 AI 子领域。NLP 的最终目标是阅读,解读,理解,并以有价值的方式理解人类语言。
NeRF (Neural Radiance Fields,神经辐射场):使用神经网络从 2D 图像创建 3D 场景的方法。它可以用于照片真实的渲染,视图合成等等。
Neural Network (神经网络):一种受人脑启发的 AI 模型。它由连接在一起的单位或节点组成——称为神经元——这些神经元按层次组织。神经元接收输入,对它们进行一些计算,并产生输出。
Objective Function (目标函数):机器学习模型在训练期间试图最大化或最小化的函数。
Overfitting (过拟合):当一个统计模型或机器学习算法无法充分捕获数据的基础结构时发生的建模错误。
Parameters (参数):在机器学习中,参数是模型用来做预测的内部变量。它们在训练过程中从训练数据中学习。例如,在神经网络中,权重和偏差就是参数。
Pre-training (预训练):训练机器学习模型的初始阶段,其中模型从数据中学习通用特征、模式和表示,而不需要具体了解将来将应用的任务的具体知识。这种无监督或半监督的学习过程使模型能够发展出对基础数据分布的基础理解,并提取出可以用于特定任务的后续微调中的有意义的特征。
Prompt (提示):设置任务或查询模型的初始上下文或指示。
Regularization (正则化):在机器学习中,正则化是一种用于防止过拟合的技术,通过在模型的损失函数中添加一个惩罚项。这个惩罚阻止模型过度依赖训练数据中的复杂模式,从而提倡更具普遍性和不易过拟合的模型。
Reinforcement Learning (强化学习):一种机器学习类型,其中一个代理通过在环境中采取行动来最大化某些奖励来学习做决策。
RLHF (Reinforcement Learning from Human Feedback,来自人类反馈的强化学习):一种通过学习人类对模型输出给予的反馈来训练 AI 模型的方法。
Singularity (奇点):在 AI 的上下文中,奇点(也被称为技术奇点)指的是一个假设的未来时点,当时技术增长变得无法控制和不可逆转,导致对人类文明的不可预见的变化。
Supervised Learning (监督学习):一种机器学习类型,在该类型中,模型被提供带有标签的训练数据。
Symbolic Artificial Intelligence (符号人工智能):一种利用符号推理解决问题和表示知识的 AI 类型。
TensorFlow (TensorFlow):由 Google 开发的用于构建和训练机器学习模型的开源机器学习平台。
TPU (Tensor Processing Unit,张量处理单元):Google 专门开发的用于加速机器学习工作负载的一种微处理器类型。
Training Data (训练数据):用于训练机器学习模型的数据集。
Transfer Learning (迁移学习):机器学习中使用预训练模型用于新问题的一种方法。
Transformer (Transformer):主要用于处理自然语言等序列数据的一种特定类型的神经网络架构。由于一种叫做“注意力”的机机制,Transformer 模型能够处理数据中的长距离依赖关系,这种机制允许模型在产生输出时权衡不同输入的重要性。
Underfitting (欠拟合):当统计模型或机器学习算法不能充分捕获数据的基础结构时发生的建模错误。
Unsupervised Learning (无监督学习):一种机器学习类型,其中模型并未提供带标签的训练数据,而必须自行识别数据中的模式。
Validation Data (验证数据):机器学习中用于调整超参数(即,架构,而非权重)的模型的数据集子集,该子集与训练和测试数据集分开。
XAI (Explainable AI,可解释的 AI):一种 AI 子领域,专注于创建提供其决策的清晰和可理解解释的透明模型。
Zero-shot Learning (零样本学习):一种机器学习类型,其中模型对在训练期间未见过的条件进行预测,无需任何微调。
One-shot Learning (单样本学习):机器学习中的一种策略,其中机器学习模型从一个单一的训练样例中学习一种新的任务或概念。
Multi-task Learning (多任务学习):机器学习的一种方法,其中一个模型被训练来同时执行多个任务,而不仅仅是单一任务。
3
https://a16z.com/ai-glossary/
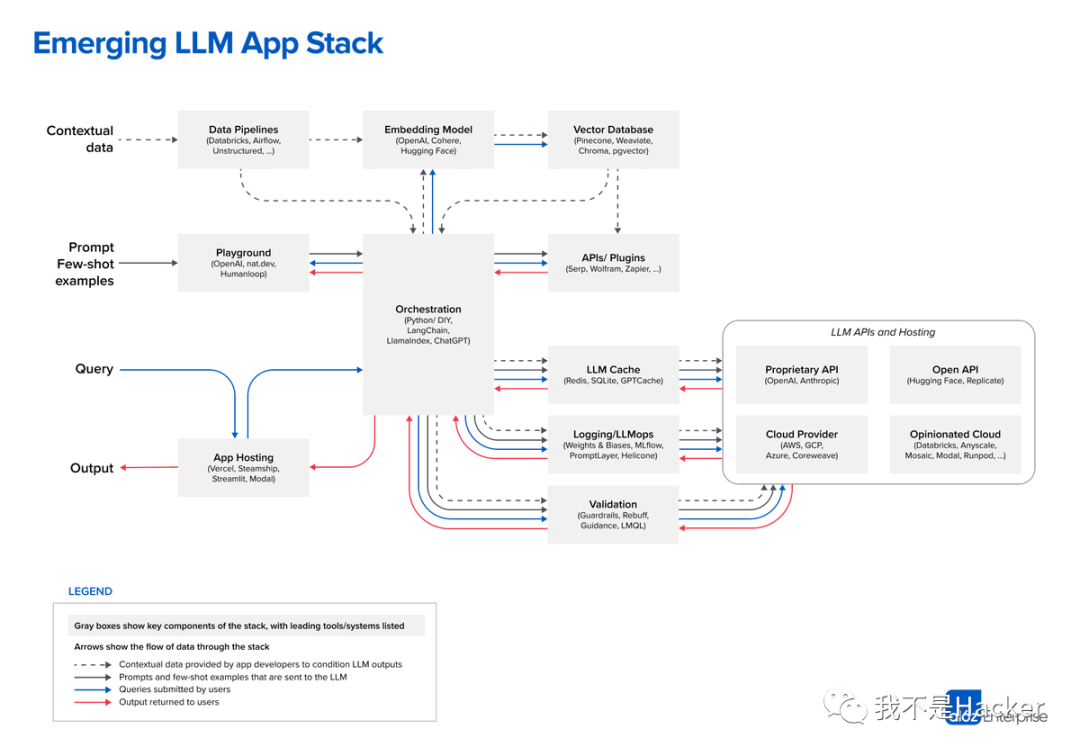
大型语言模型是一种强大的新原语,用于构建软件。但是由于它们如此新颖——并且与普通计算资源的行为方式如此不同——我们并不总是明确知道如何使用它们。
在这篇文章中,我们分享了一种新兴的LLM应用栈的参考架构。它展示了我们在AI创业公司和先进技术公司中最常见的系统、工具和设计模式。这个栈还处在非常早期的阶段,并可能随着底层技术的进步而发生重大变化,但我们希望它对现在正在使用LLM的开发者来说会是一个有用的参考。
这项工作是基于我们与AI创业公司创始人和工程师的对话。我们特别依赖于以下人士的输入:Ted Benson、Harrison Chase、Ben Firshman、Ali Ghodsi、Raza Habib、Andrej Karpathy、Greg Kogan、Jerry Liu、Moin Nadeem、Diego Oppenheimer、Shreya Rajpal、Ion Stoica、Dennis Xu、Matei Zaharia和Jared Zoneraich。感谢你们的帮助!
如有侵权请联系:admin#unsafe.sh