基于ChatGLM-6B 部署本地私有化ChatGPT一、开源模型1、ChatGLM-6B介绍清华大学知识工程 (KEG) 实验室和智谱AI公司与于2023年共同训练的语言模型;ChatGLM-6B 2023-6-24 17:50:23 Author: 哆啦安全(查看原文) 阅读量:84 收藏
基于ChatGLM-6B 部署本地私有化ChatGPT
一、开源模型
1、ChatGLM-6B介绍
清华大学知识工程 (KEG) 实验室和智谱AI公司与于2023年共同训练的语言模型;ChatGLM-6B 参考了 ChatGPT 的设计思路,在千 亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调等技术实现与人类意图对齐(即让机 器的回答符合人类的期望和价值观);
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数;
结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存);
ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答;
2、ChatGLM-6B 有如下特点
充分的中英双语预训练:ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力;
优化的模型架构和大小:吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能;
较低的部署门槛:FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上;
更长的序列长度:相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用;
人类意图对齐训练:使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示;因此,ChatGLM-6B 具备了一定条件下较好的对话与问答能力;
3、ChatGLM-6B 也有相当多已知的局限和不足
模型容量较小:6B 的小容量,决定了其相对较弱的模型记忆和语言能力;在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;
她也不擅长逻辑类问题(如数学、编程)的解答;
可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容;
较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况;
英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾;
易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容;
二、系统部署
1、硬件需求
2、系统环境
操作系统:CentOS 7.6/Ubuntu (内存:32G)
显卡配置:2x NVIDIA Gefore 3070Ti 8G (共16G显存)
Python 3.8.13 (版本不要高于3.10,否则有些依赖无法下载,像paddlepaddle 2.4.2在高版本Python还不支持)
# 安装Python3.8所需依赖sudo yum -y install gcc zlib zlib-devel openssl-devel# 下载源码wget https://www.python.org/ftp/python/3.8.13/Python-3.8.13.tgz# 解压缩tar -zxvf Python-3.8.13.tgz# 编译配置,注意:不要加 --enable-optimizations 参数./configure --prefix=/usr/local/python3# 编译并安装make && make install
3、部署ChatGLM 6B
3.1下载源码
直接下载chatGLM-6B https://github.com/THUDM/ChatGLM-6B
git下载 git clone https://github.com/THUDM/ChatGLM-6B
3.2安装依赖
进入ChatGLM-6B目录
使用 pip 安装依赖:pip install -r requirements.txt,其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。
此外,如果需要在 cpu 上运行量化后的模型,还需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选 openmp。Windows 测试环境 gcc 版本为 TDM-GCC 10.3.0, Linux 为 gcc 11.3.0
3.3下载模型
从 Hugging Face Hub 下载
可以手动下载https://huggingface.co/THUDM/chatglm-6b/tree/main
git下载 git clone https://huggingface.co/THUDM/chatglm-6b
将模型下载到本地之后,将以上代码中的 THUDM/chatglm-6b 替换为你本地的 chatglm-6b 文件夹的路径,即可从本地加载模型;
在chatglm-6b文件下创建一个model文件夹放模型文件
3.4代码调用
可以通过如下代码调用 ChatGLM-6B 模型来生成对话:
模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在 from_pretrained 的调用中增加 revision="v1.1.0" 参数
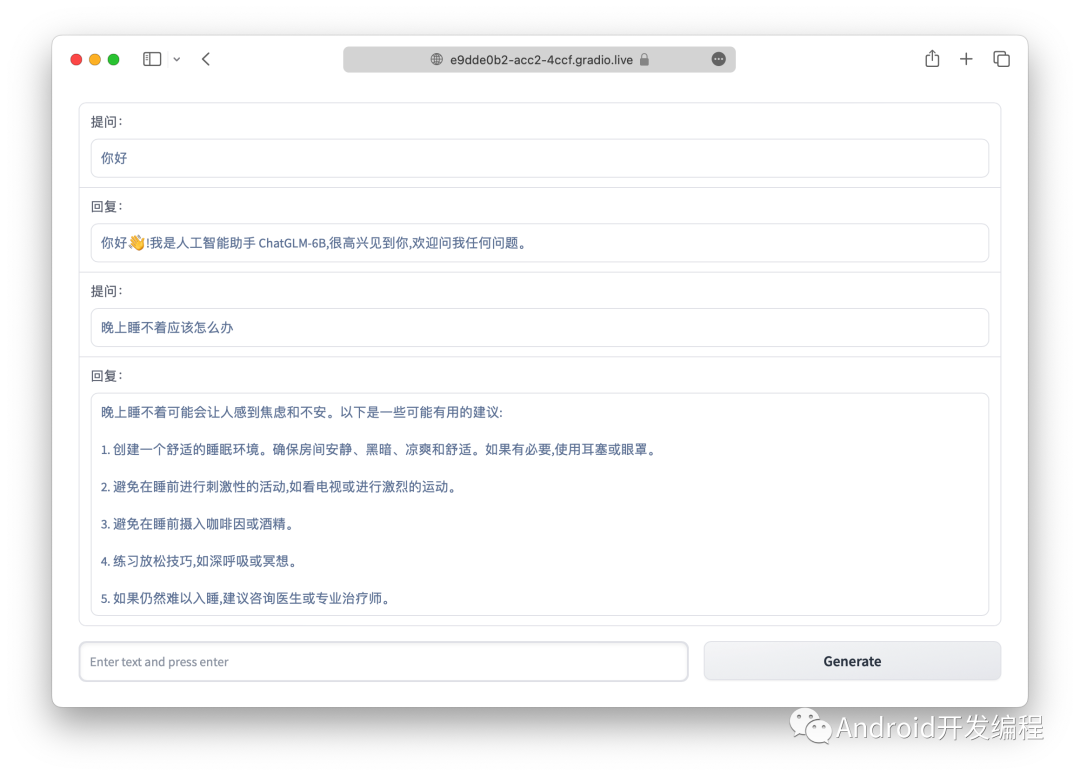
>>> from transformers import AutoTokenizer, AutoModel>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()>>> model = model.eval()>>> response, history = model.chat(tokenizer, "你好", history=[])>>> print(response)你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)>>> print(response)
3.5低成本部署
模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(8).half().cuda()
进行 2 至 3 轮对话后,8-bit 量化下 GPU 显存占用约为 10GB,4-bit 量化下仅需 6GB 占用。随着对话轮数的增多,对应消耗显存也随之增长,由于采用了相对位置编码,理论上 ChatGLM-6B 支持无限长的 context-length,但总长度超过 2048(训练长度)后性能会逐渐下降。
模型量化会带来一定的性能损失,经过测试,ChatGLM-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。使用 GPT-Q 等量化方案可以进一步压缩量化精度/提升相同量化精度下的模型性能,欢迎大家提出对应的 Pull Request。
量化过程需要在内存中首先加载 FP16 格式的模型,消耗大概 13GB 的内存。如果你的内存不足的话,可以直接加载量化后的模型,INT4 量化后的模型仅需大概 5.2GB 的内存:
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
量化模型的参数文件也可以从这里手动下载。
3.6CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
如果你的内存不足,可以直接加载量化后的模型:
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
如果遇到了报错 Could not find module 'nvcuda.dll' 或者 RuntimeError: Unknown platform: darwin (MacOS) ,请从本地加载模型
3.7多卡部署
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate: pip install accelerate,然后通过如下方法加载模型:
from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm-6b", num_gpus=2)
即可将模型部署到两张 GPU 上进行推理。你可以将 num_gpus 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 device_map 参数来自己指定
四、系统启动
4.1网页版 Demo
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动
4.2命令行 Demo
运行仓库中 cli_demo.py:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序
4.2API部署
首先需要安装额外的依赖 pip install fastapi uvicorn,然后运行仓库中的 api.py:
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" \-H 'Content-Type: application/json' \-d '{"prompt": "你好", "history": []}'得到的返回值为{"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-03-23 21:38:40"}
4.3部署中常见问题
问题1、torch.cuda.OutOfMemoryError: CUDA out of memory
很明显,显存不足,建议切换到chatglm-6b-int4或者chatglm-6b-int4
torch.cuda.OutOfMemoryError: CUDA out of memory
问题2、"RuntimeError: Library cudart is not initialized"
这个错误通常是由于缺少或损坏的 CUDA 库文件引起的。要解决这个问题,需要安装 CUDA Toolkit :
安装CUDA Toolkitsudo yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.reposudo yum clean allsudo yum -y install nvidia-driver-latest-dkmssudo yum -y install cuda
推荐阅读
如有侵权请联系:admin#unsafe.sh