bitcask 存储模型是由 riak 设计出来的, riak 是一个类似 amazon dynamodb 的分布式 kv 数据库,其设计也是无主模型,开发语言是 erlang。riak 在社区中没多少热度了,但 bitcask 存储模型的热度依然存在,当然相比主流的 lsmTree 和 B+tree 实现的数据库还差点意思。
riak bitcask 论文地址: https://riak.com/assets/bitcask-intro.pdf
golang 社区中基于 bitcask 存储模型实现的 kv 引擎有 rosedb 和 nutsdb,两者的实现原理大同小异,使用方面也都实现了 redis 的数据结构,解决纯 KV 存储格式不能满足多样的业务需求。
本文主要以 rosedb 项目代码为主,分析 bitcask 存储模型在工程上的实现,如何在简单的 KV 模型上构建复杂的兼容 redis 的数据结构。
golang bitcask rosedb 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-bitcask-rosedb
bitcask 存储设计
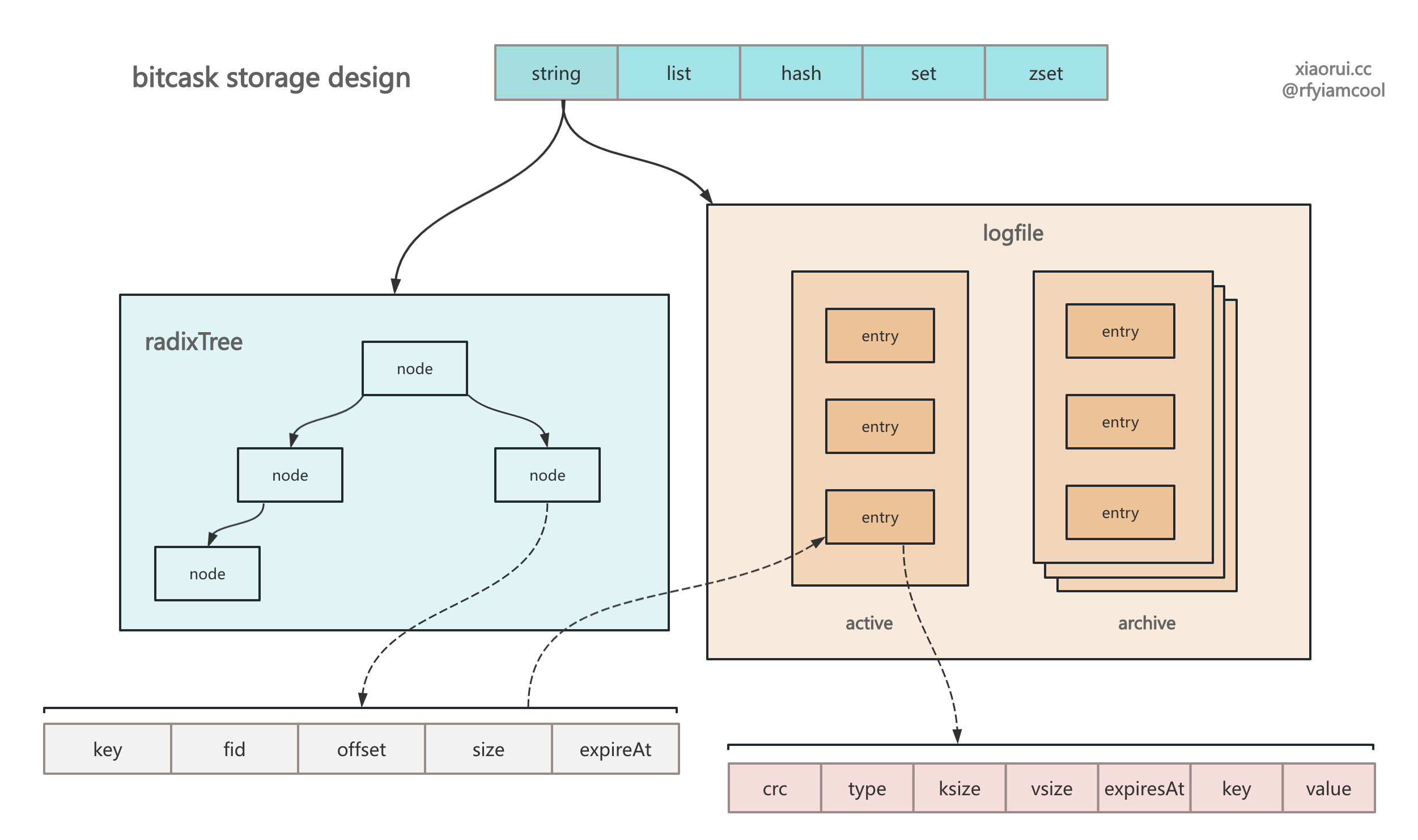
基于 bitcask 存储模型设计的 kv 存储引擎,所有的写操作都是先构建一个 entry,经过编码后写到活跃 logfile 文件里。在 bitcask 论文里提到只能有一个活跃的 logfile 日志文件,活跃的 logfile 才能进行写操作。而其他的 logfile 都为归档 logfile 日志文件,只能读,不能写。
在把 entry 写到活跃的 logfile 后,可以得知该 entry 在哪个文件里、偏移量多少和 entry 大小是多少,这个 value 的位置信息叫做 valuePos。
bitcask 需要在内存里构建索引,索引可以是红黑树、平衡二叉树、b+tree、skiplist 跳表或者 radixTree 基数树等。rosedb 选用的是 radixTree 基数树,这里不讨论这些索引的优缺点。rosedb 索引的 key 为业务的 key,而 value 是 valuePos,上面有说 valuePos 含有 fid、offset、size 这三个信息,通过该三个信息就可以找到文件,在通过读取 offset 后的 size 数据编解码 entry 对象。
type valuePos struct {
fid uint32
offset int64
entrySize int
}
rosedb 为了实现过期功能,则 radixTree 索引节点里还加入了过期时间字段。
一直进行写操作,当 logfile 的存储空间大于阈值时,则会生成新的 logfile 文件,而老的 logfile 被标记为归档文件,所以 bitcask 模型的存储引擎,活跃的 logfile 只有一个,而归档的 logfile 有多个。
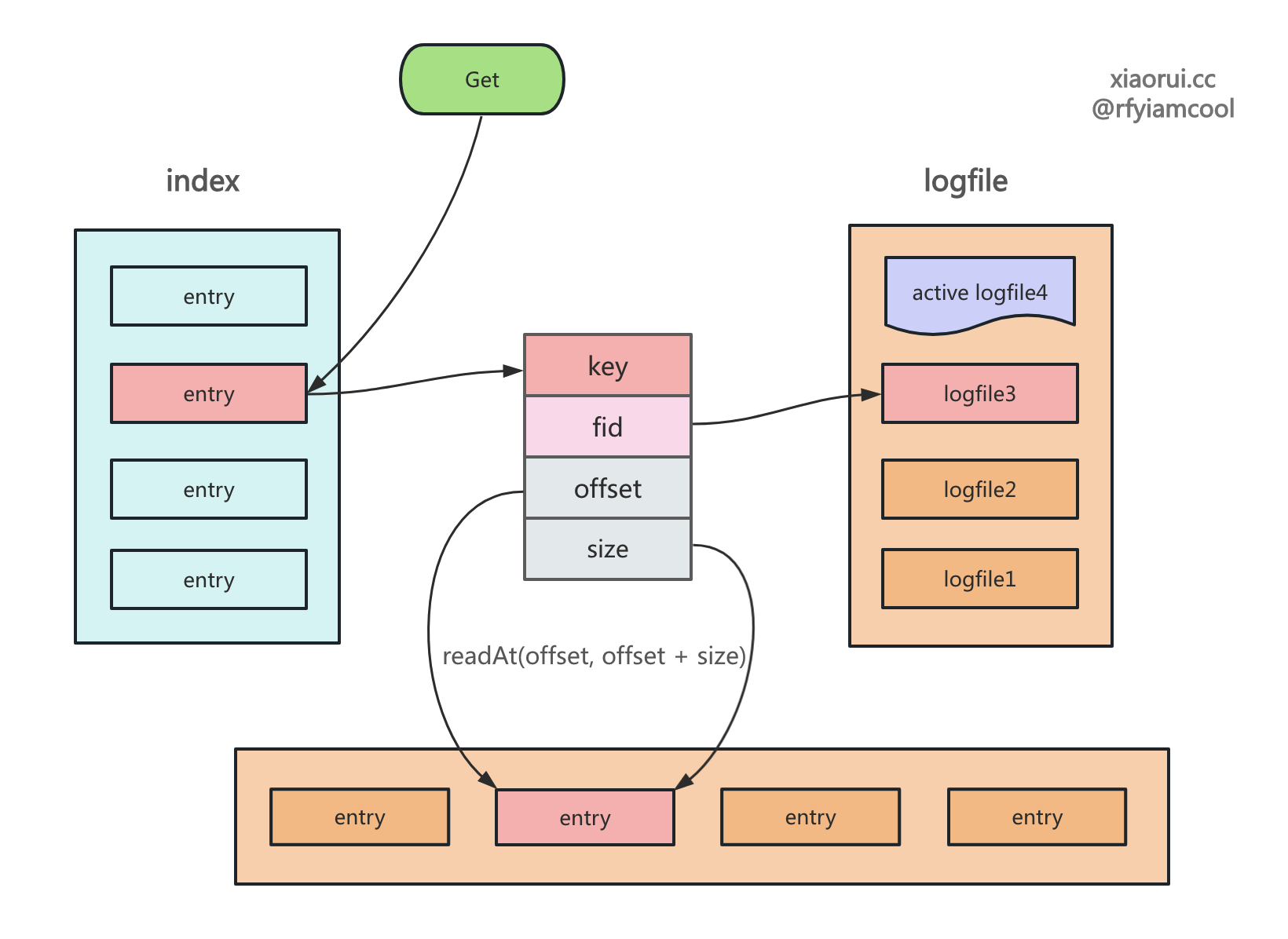
读取
在读取数据时,先从索引里查找 key 对应的 valuePos,如找不到 key,说明 key 不存在。然后根据 valuePos 的 fid 找到对应的 logfile 日志对象,再根据 valuePos 的 偏移量 offset 和数据大小 size 读出数据。
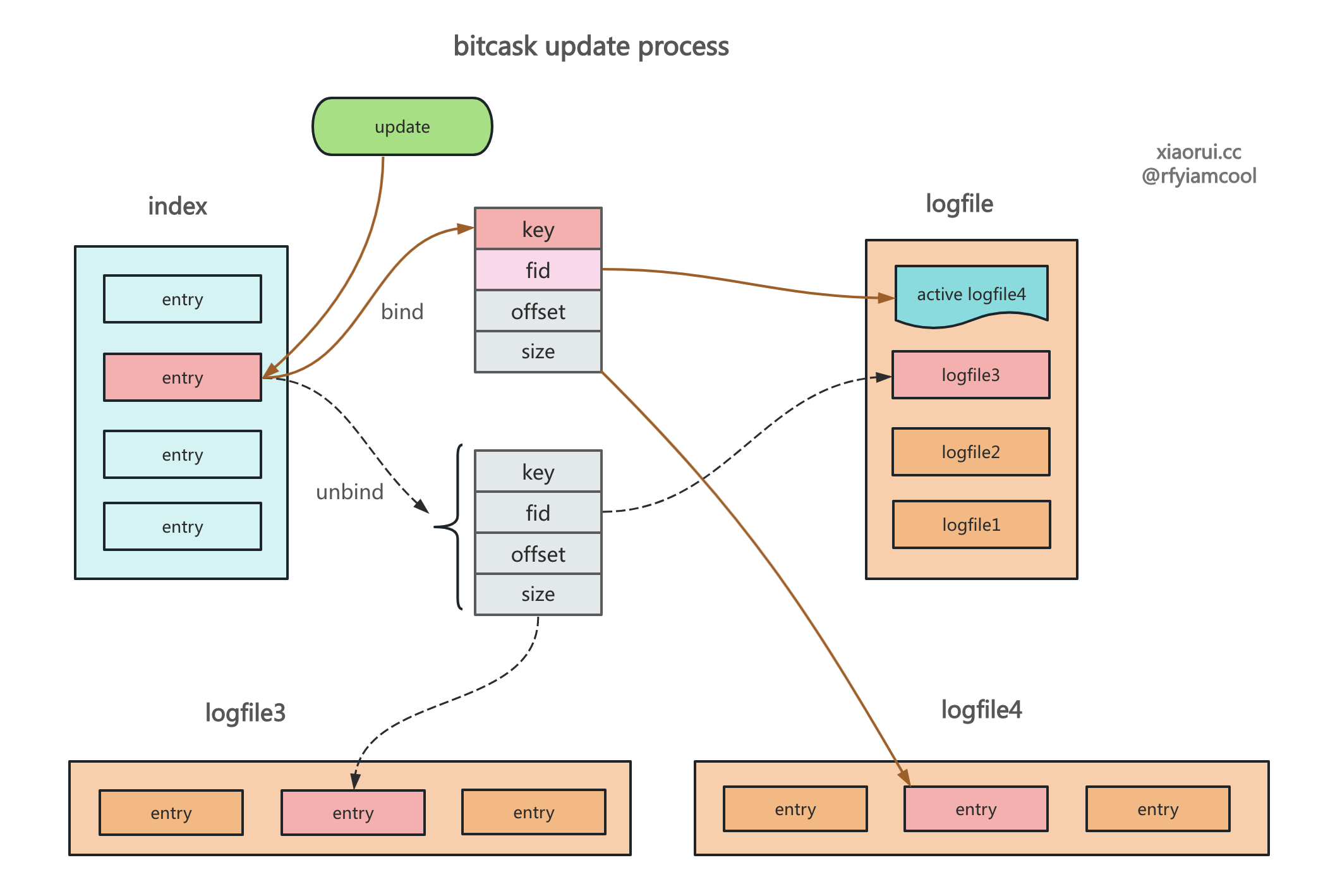
更新和删除
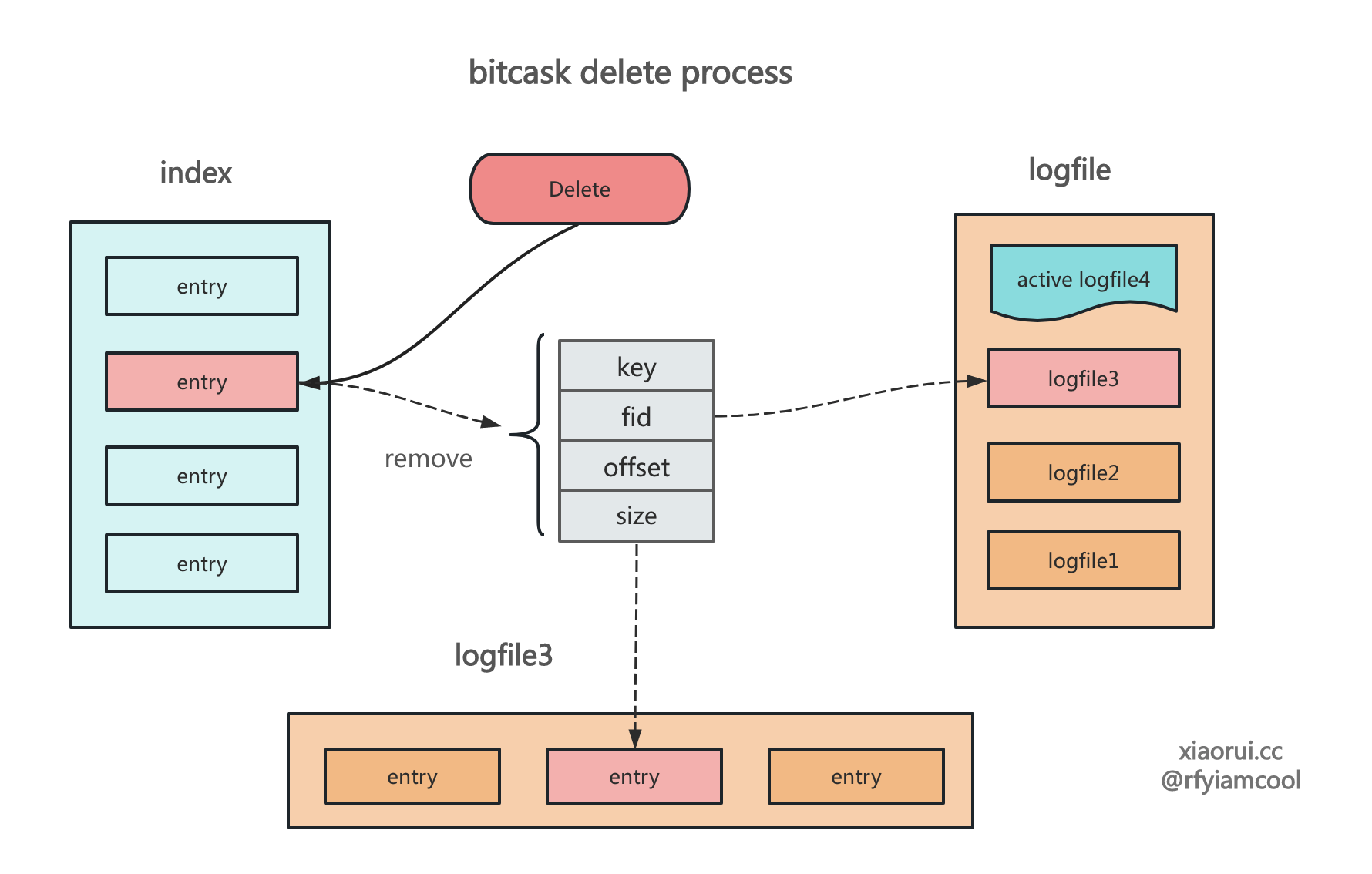
bitcask 下的更新和删除数据操作有些不同,删除操作则是在 logfile 里写入一个带 delete 标记的数据,接着删除索引即可,而更新操作跟插入操作是一样的,追加写数据,然后更新索引,让索引指向最新的 valuePos 位置上。
下图为 bitcask 的更新操作
下图为 bitcask 的删除操作
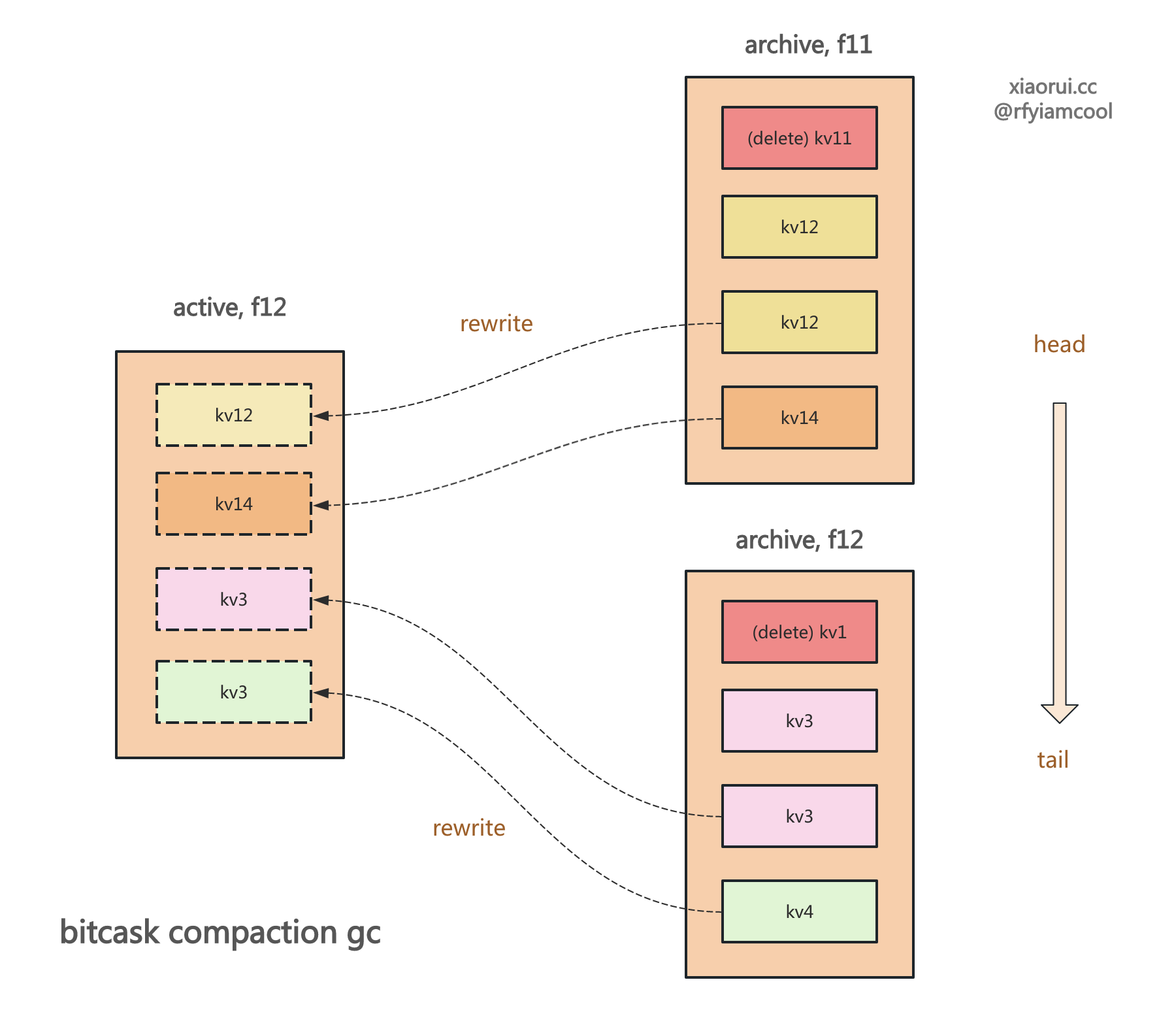
如何 GC 垃圾回收 ?
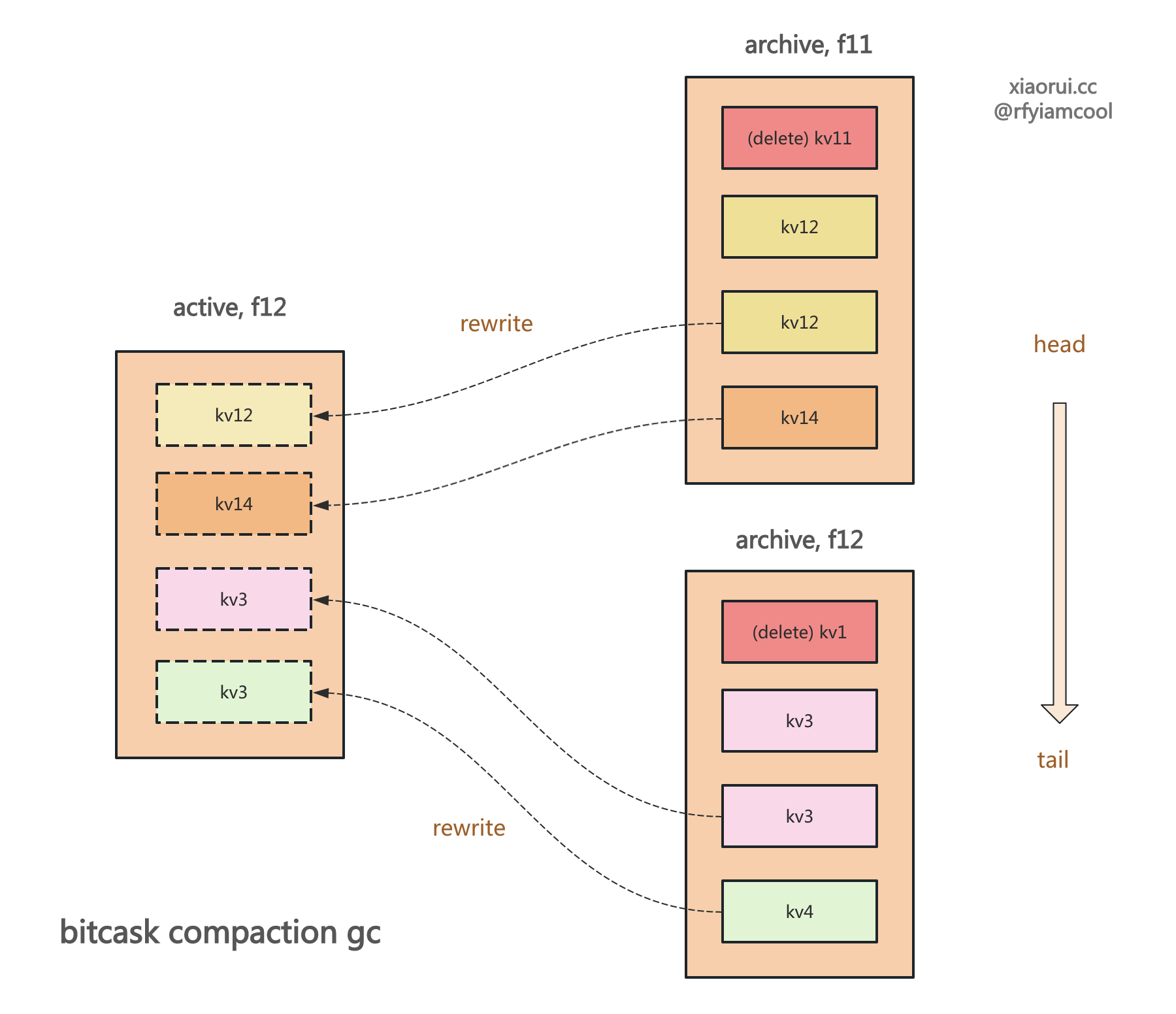
使用 bitcask 模型实现的 kv 存储引擎不会直接原理删除数据,而是通过 compaction gc 合并垃圾回收的方式来释放空间。 社区基于 bitcask 的 rosedb 和 nutsdb 当然也这么设计的。
其原理是这样的,首先过滤出满足垃圾回收阈值的 logfile,rosedb 的判断 GC 阈值公式是 垃圾存储空间/总存储空间 > 0.5。接着遍历读取超过阈值的 logfile 日志文件里的所有 entry,每个 entry 都要跟当前索引做对比,如果跟索引的 valuePos 一致,则说明该 entry 需要重写,这里的重写就是把 entry 写到当前的活跃 logfile,再更新内存索引指向到新的 valuePos 信息。
bitcask 存储模型不适合数据多的场景 ?
为什么说 bitcask 模型不适合大存储模型 ? 就是因为其需要在内存里构建全量的索引,当数据特别多的时候,单单索引的开销也很大,还有启动时需要扫描所有的 logfile 文件内的数据来构建索引。当使用 sata 这类机械盘做存储时,假设 Disk磁盘吞吐在 200MB 左右,那么读取 20GB 的 DB 数据少说需要 100 秒。如果 DB 文件在 100GB,差不多需要近 10 分钟加载时间。
为了提高启动阶段的初始化速度,riak bitcask 论文里有提到使用 .hint 文件存储 key 和 valuePos 的索引,也就是为每个 logfile 分配一个 .hint 索引文件,该索引文件内只存储 key 和 valuePos 数据。数据库启动时只需要读取 .hint 文件即可。当然每次写数据时,除了去写 logfile 外,还需要把索引信息写到 .hint 文件。
当然也可以在内存里再多一个维护当前 active logfile 的索引信息,索引为 key 和 valuePos。当 active logfile 超过阈值被切到不可变的归档 logfile 时,顺便把该 logfile 对应的索引数据落到 .hint 文件里。这样下来,归档的 logfile 自然是有 .hint,活跃的 logfile 没有 .hint 文件,那么启动恢复时直接读 logfile 构建索引。当然也可以在归档时,遍历读尽数据的header,然后写到 .hint 文件,由于刚归档的 logfile 大概率也在 page cache 中,还有 logfile 文件也不大,不会造成太多的 disk io。
rosedb 和 nutsdb 都没有设计 .hint 索引,猜想是跟 bitcask 实际应用场景有关,作为单机存储引擎不会有太多的数据,硬扫也还可以接受。像 k8s 依赖的中间件 etcd 在使用 boltdb 时,key 为 revison ,value 为 kv 键值,所以需要启动时把 boltdb 读完读尽才可构建 treeindex 索引。😅
下面是 rosedb 遍历读取 logfile,并构建索引的过程。
func (db *RoseDB) loadIndexFromLogFiles() error {
iterateAndHandle := func(dataType DataType, wg *sync.WaitGroup) {
defer wg.Done()
fids := db.fidMap[dataType]
if len(fids) == 0 {
return
}
// 对 logfile 正排序,旧的文件优先处理.
sort.Slice(fids, func(i, j int) bool {
return fids[i] < fids[j]
})
// 遍历 logfile 集合.
for i, fid := range fids {
var logFile *logfile.LogFile
if i == len(fids)-1 {
logFile = db.activeLogFiles[dataType]
} else {
logFile = db.archivedLogFiles[dataType][fid]
}
if logFile == nil {
logger.Fatalf("log file is nil, failed to open db")
}
// 初始化偏移量
var offset int64
for {
// 从偏移量读取 entry,其内部先读取 entry header,再根据 ksize 和 vsize 获取 kv 键值数据.
entry, esize, err := logFile.ReadLogEntry(offset)
if err != nil {
// 如果文件读到头,则跳出
if err == io.EOF || err == logfile.ErrEndOfEntry {
break
}
}
// 构建 valuePos 文件偏移量信息
pos := &valuePos{fid: fid, offset: offset}
// 把数据添加到 dataType 相关的索引里.
db.buildIndex(dataType, entry, pos)
// 累加偏移量
offset += esize
}
// 如果遍历到最新的 logfile, 则原子保存当前的活跃日志文件的 offset.
if i == len(fids)-1 {
atomic.StoreInt64(&logFile.WriteAt, offset)
}
}
}
wg := new(sync.WaitGroup)
wg.Add(logFileTypeNum)
// 为每个 dataType 启动给协程来加载数据,并构建索引.
for i := 0; i < logFileTypeNum; i++ {
go iterateAndHandle(DataType(i), wg)
}
wg.Wait()
return nil
}
如何在 KV 基础上构建 redis 数据结构 ?
riak bitcask 论文只是 kv 存储引擎的实现,没有提到其他数据结构的实现。rosedb 和 nutsdb 都实现了 redis 常用的那几个数据结构,如 string、list、set、hash、zset。
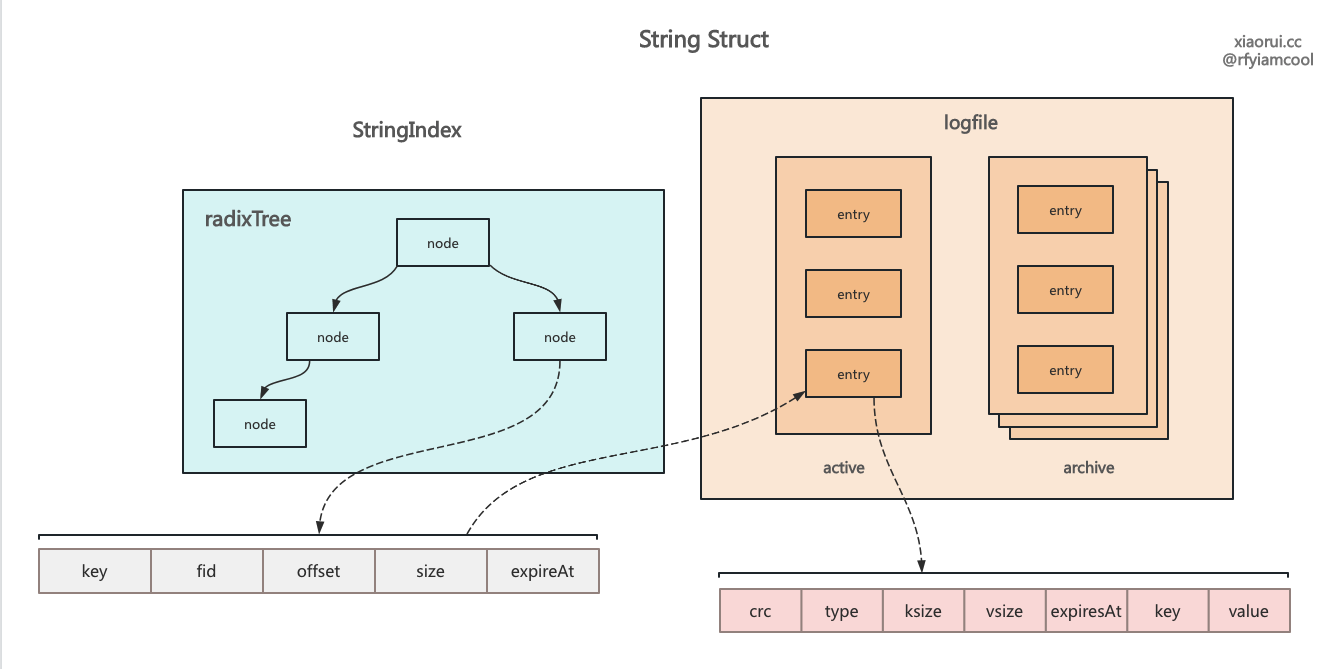
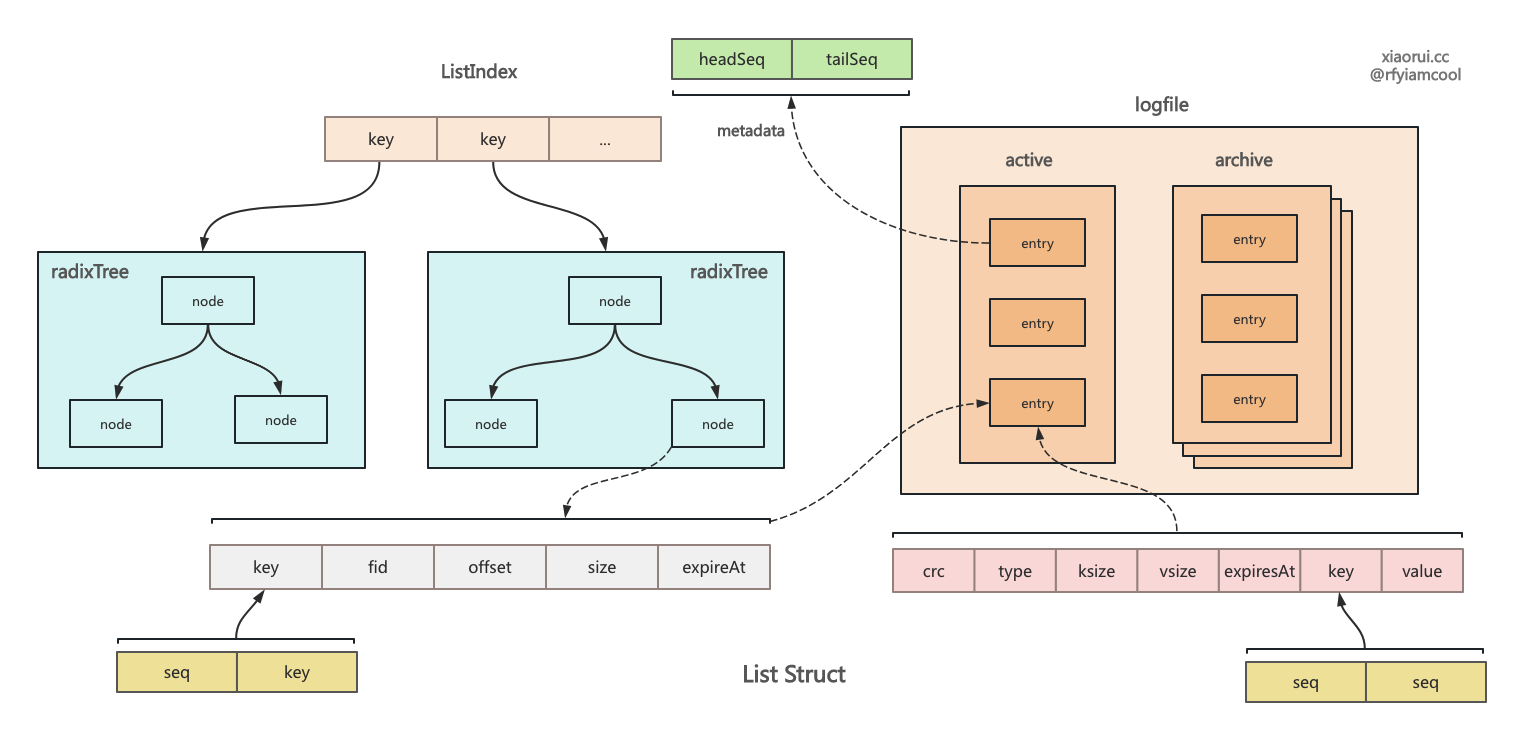
rosedb 实现方法有些巧妙,数据依旧存到 logfile 里,然后在内存里构建索引。string 是个简单的 kv,实现最简单,也最基础。list 是个链表结构,需要存储一个 metadata 记录了当前头尾的序号,后面的增删改查都依赖这个序号。hash 是个字典结构,radixtree 索引中记录 field 和 valuePos 的关系,而 logfile 的 key 为 key 和 field 的组合。 set 是个集合结构,radixtree 索引中记录了 member 的哈希值,而 logfile 记录了完整的 kv。zset 是 rosedb 里最为复杂的结构,其内部使用 sortedset 和 radixtree 来实现。
需要注意下,rosedb 里有 5 个 redis 数据结构类型,每个数据类型都有独立的索引对象,有独立的 logfile 日志文件,包括活跃和归档的,还有独立的 discard 统计文件。🤔 这样分而治之架构显得更清晰整洁,且更好的实现并发,不同数据类型并发写时,互不影响,可直接并发处理。还有在触发垃圾回收时,rosedb 会为每个数据类型开启一个 GC 协程,这样也做到了互不干扰。discard 用来记录每个 logfile 的垃圾数据占用统计,其内部也会按照数据类型分离开来,同样做到了并发处理。
rosedb 里 string 结构的设计
rosedb 里 list 列表结构的设计
rosedb 里 hash 字典结构的设计
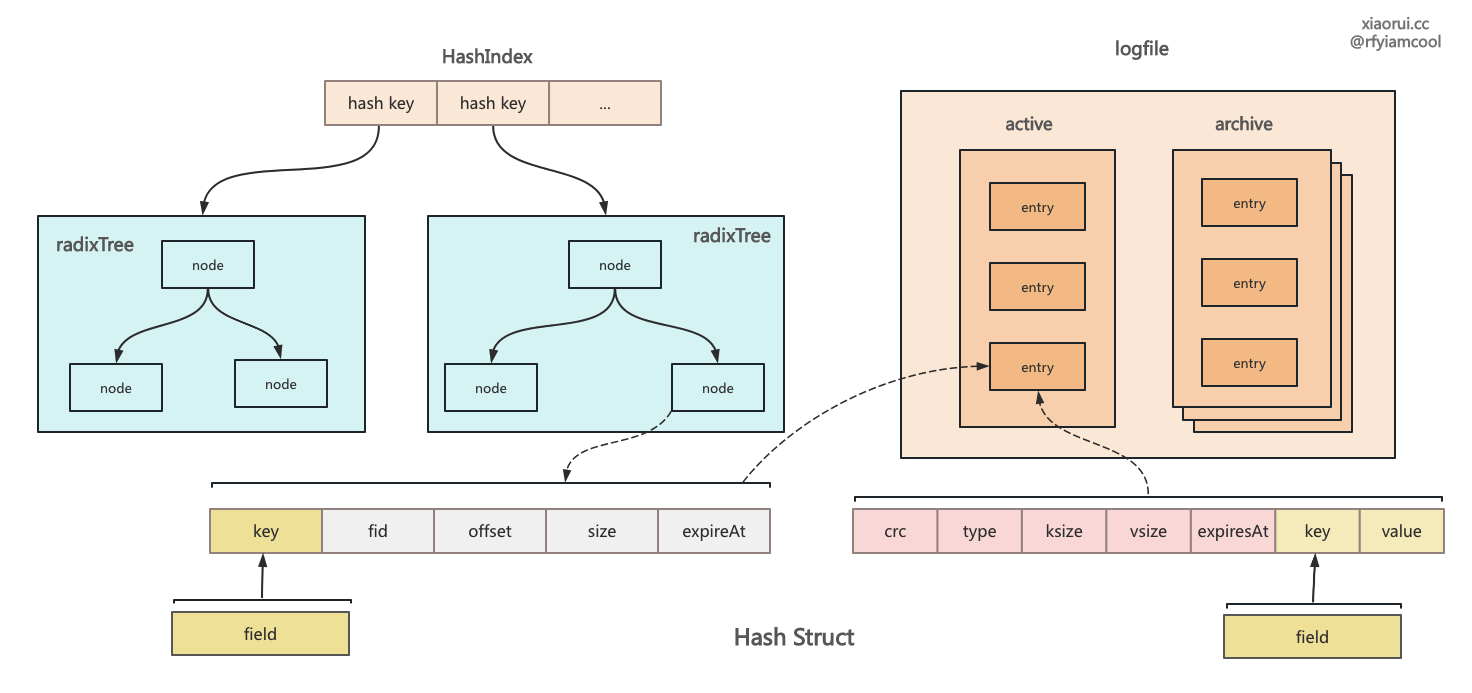
rosedb 里 set 集合结构的设计
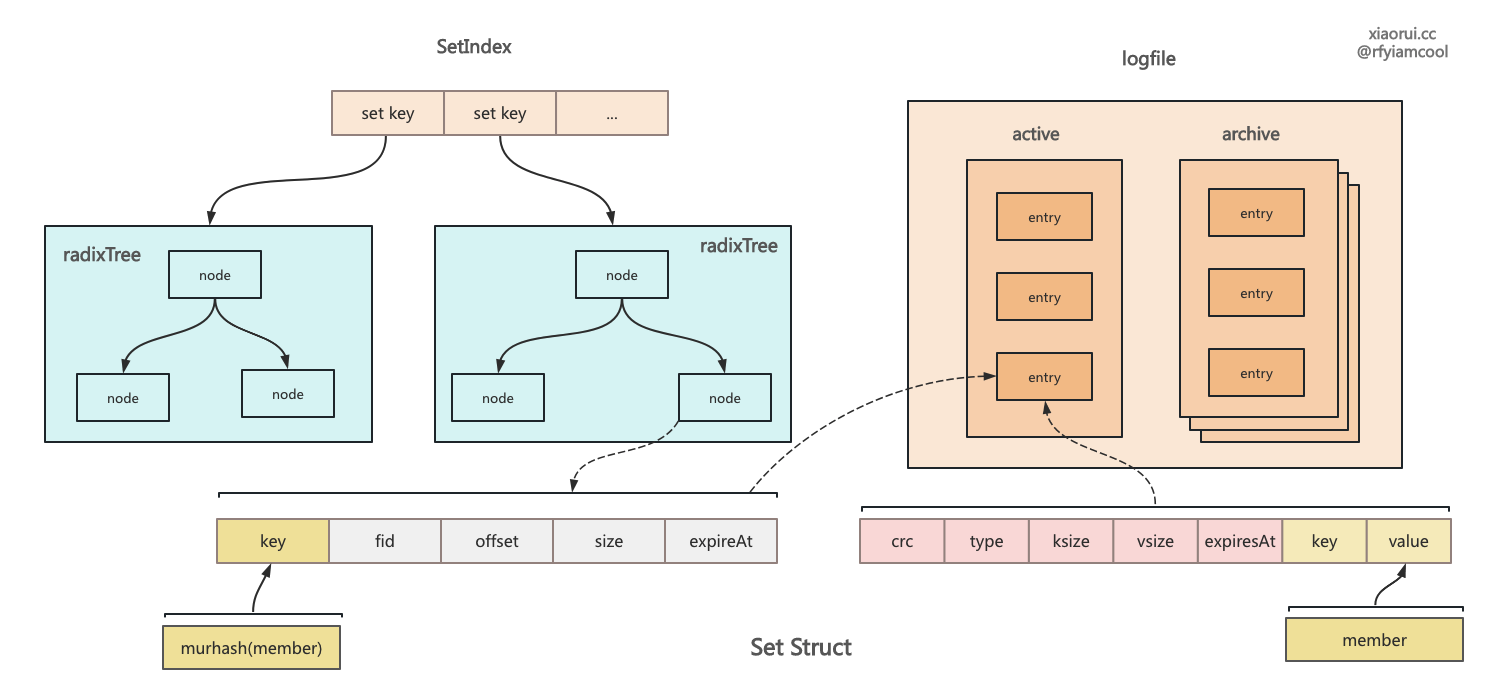
rosedb 里 zset 有序集合结构的设计
bitcask 的性能如何 ?
对比查询的性能
如果是点查的话,bitcask 要比 lsm-tree 这类的存储引擎性能要高的,因为 bitcask 的索引中有全量数据索引,通过 key 找到 valuePos,再通过 valuesPos 直接到 logfile 读取相关数据即可。而 lsmtree 则需要先到 活跃 memtable 查找,再到不可变 immutable table 集合里查找,继续尝试在 L0 层里所有符合 key 范围内的 SSTable 里查找,再到 L1,L2, LevelN…,直到找到数据。
但范围查询要比 lsm-tree 存储引擎差一些,原因是 bitcask logfile 日志文件内部没有对 kv 排序,logfile 文件之间也无排序,有序是依赖在内存里构建索引来实现的。当进行范围查询时,通过 bitcask 有序索引找到 key 对应的 valuePos,再依次到文件中读取。这些 value 在各个 logfile 文件中,查询时会使用大量的随机 IO。
对比写入性能
bitcask 跟 lsm-tree 存储引擎差不多。bitcask 直接写到 logfile 里,然后把 valuePos 更新到索引中。而像 rocksdb 和 badger 是先把数据写到 memtable 对应的 wal 文件中,然后在 memtable 的跳表 skiplist 中添加 node 索引节点,该 node 的 value 指向到 wal 的 offset 和 size。
对比合并性能
bitcask 的 compaction gc 合并和垃圾回收的过程相对比较简单,rocksdb 和 badger 实现了并发合并,先选定 level,则选定 sstable,可按照 keyrange 划分 sstable 范围来实现并发合并。bitcask 的合并垃圾回收虽然简单,但足矣满足 bitcask 的需求。
rosedb 什么场景会丢失数据 ?
首先需要知道所有存储引擎都有类似 sync 同步写选项的,当然名字可能不同,redis 为 appendfsync 策略,mysql 为 innodb_flush_log_at_trx_commit 参数。在开启该选项后,每次写完数据都要主动发起 sync 调用,同步写会影响性能。对数据安全性要求高的,需要开启同步写。对于性能高的可以关闭同步写策略,采用定时刷盘,或者干脆不主动刷盘,而只依赖内核线程 pdflush 去管理 page cache 的刷盘,通常满足 deadline 和脏页率会发起刷盘。
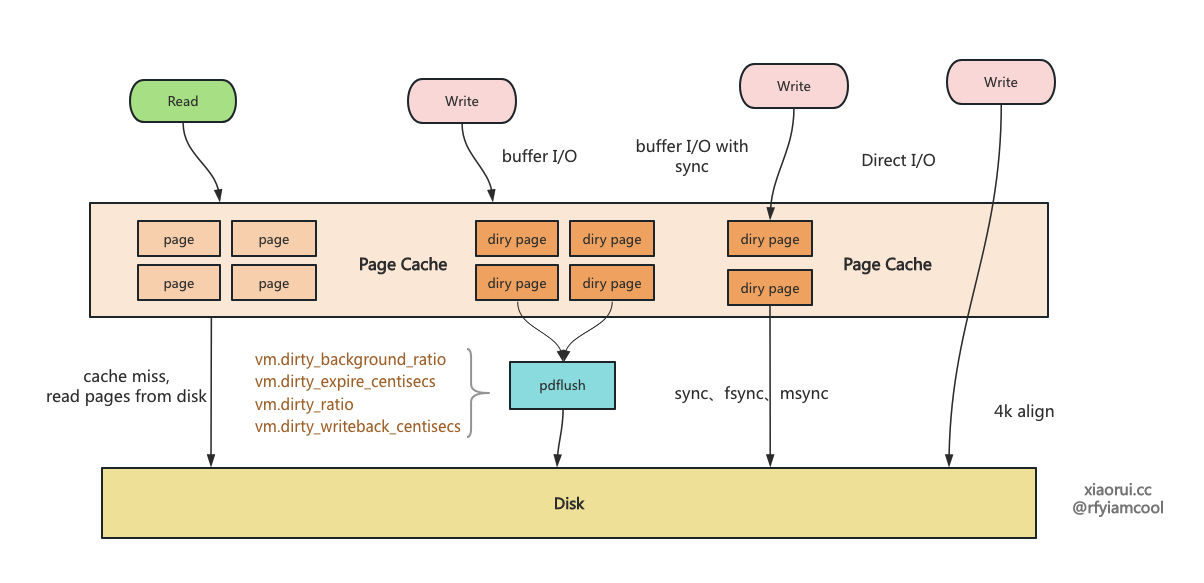
社区中 rosedb、nutsdb、badgerDB、leveldb、rocksdb 等主流的引擎默认都关闭了同步写操作,毕竟同步写确实影响性能。普通 sata3 磁盘的 io latency 时延在 5ms 左右,那么在不使用批量写的条件写,每秒写的上线可以到 200 条的数据。nvme ssd 企业固态硬盘的 io lantency 时延可以低到 < 100us 左右,每秒理论可以写 10000 条数据,当然这里不能超过 IO 吞吐带宽。
分析下 rosedb 数据写入的详细流程 ?
把传入的 kv 键值编码字节数组,之后把数据先写到 logfile 里,这里其实是先写到 page cahce 里,相关的 page 页被标记成脏页,还加入到 buffer cache 链表。
判断是否开启 sync 选项,如开启则调用 sync 同步刷盘。如何在不开启 sync 的情况下服务挂了,数据还在 page cache ( buffer cache ) 中,不丢数据的。当然如果服务器直接掉电,那么没来得及刷盘的 page,必然是丢了。其实 sync 刷盘完毕,也不能保证数据安全。因为大多数磁盘内部也是有读写缓存的,当服务器断电掉电后,sata 盘虽然带电,但有概率支撑不到把缓存里的数据写完,企业的 sata 盘缓存可以做到 256 MB。而 ssd 也是带有掉电保护机制,在异常掉电下可以把缓存里的数据写完,其原理就是在 ssd 上加入电容,再检测到掉电后主动把 DRAM 缓存里数据刷到 Nand 闪存里。
当然,为了保证 sync 的安全性,你也可以用把磁盘内部的高速缓存关闭。服务器掉电的概率其实很低的。
下图为 wd 企业盘的缓存容量.
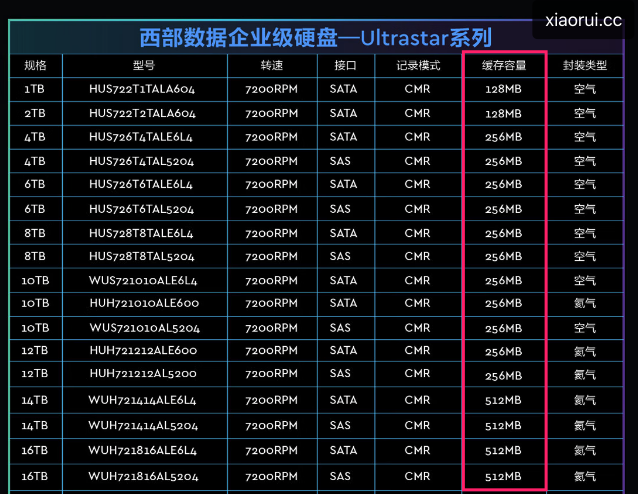
下图为 ssd 断电保护电容.

compaction gc 合并及垃圾回收过程中是否丢失数据?
compaction gc 过程崩溃不会丢失数据。比如把一个的 logfile 合并清理掉,合并的过程中服务挂了,那么新老 logfile 都存在,按照 bitcask 的恢复设计会按照从老到新的顺序恢复 logfile,可以完整的恢复数据。
