原文标题:Scalable Detection of Promotional Website Defacements in Black Hat SEO Campaigns原文作者:Ronghai Ya 2023-6-27 21:2:53 Author: 安全学术圈(查看原文) 阅读量:30 收藏
原文标题:Scalable Detection of Promotional Website Defacements in Black Hat SEO Campaigns
原文作者:Ronghai Yang, Xianbo Wang, Cheng Chi, Dawei Wang, Jiawei He, Siming Pang, Wing Cheong Lau
原文链接:https://www.usenix.org/system/files/sec21-yang-ronghai.pdf
发表会议:USENIX Security Symposium 2021.
笔记作者:[email protected]安全学术圈
笔记小编:黄诚@安全学术圈
1、研究介绍
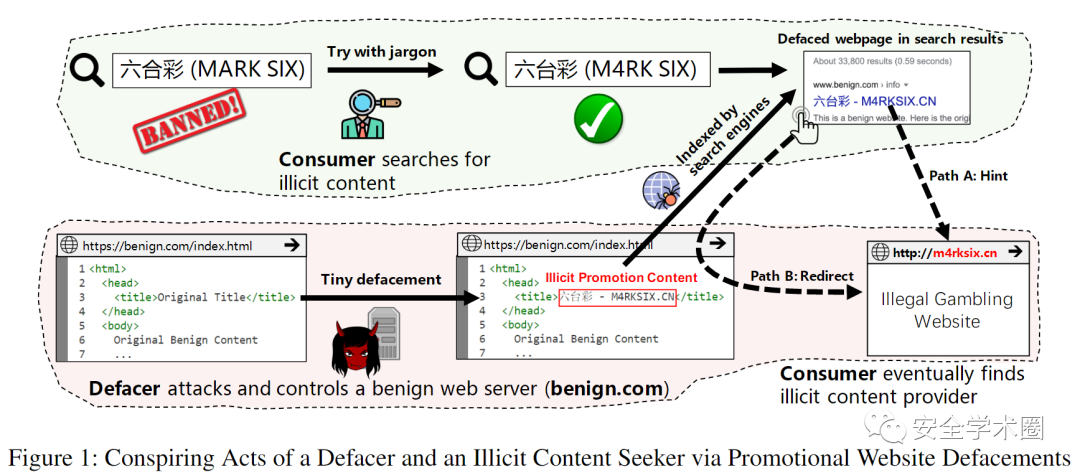
为了推广非法的商品和服务,不法分子通常会利用网站的漏洞将欺诈性内容注入受害者网页。尽管这种推广方式在黑帽SEO中极其常见,但是针对网站推广篡改的可扩展检测仍然是一个悬而未决的问题。攻击者通常以隐蔽的方式注入内容,如混淆非法产品的描述或篡改的存在使它们无法被检测。
为了解决上述问题,本文设计了大规模保护网站免受推广篡改的篡改监控系统,其设计主要基于两个关键发现:对于有效的推广,非法商品或服务的黑话需要易于被目标客户理解;为了促进地下产业,篡改通常会提高网页的搜索引擎排名,同时保持隐蔽不被网站的维护者和合法用户发现。针对这两个特点,作者首先设计了一种黑话归一化算法(Jargon Normalization Algorithm),将混淆后的行话映射到其原始形式。作者接着开发了一种标签嵌入机制(Tag Embedding Mechanism),使得系统能够更多关注那些视觉上不明显但对搜索引擎排名有影响力的HTML标签。
2、主要创新点
Jargon Normalization Algorithm
作者介绍了两种类型的混淆黑话,即谐音(homophonic)和同态(homomorphic),例如六合彩的谐音黑话为六和彩,同态黑话则为六台彩。针对这两种黑话,作者设计了黑话归一化算法,主要包含4个步骤:
(1)首先使用中文维基作为语料库训练语言模型,用于判断一个语言序列是否是正常语句(不通畅,不常用)。
(2)接着使用语言模型筛选数据集中概率较低的语言序列,这些语言序列更有可能包含混淆黑话。
(3)从语言序列中识别混淆黑化并将其还原为正常语句。
(4)对于还原后的候选黑话,只有被语言模型识别为正常的语句才会还原到数据集中。
对于谐音黑话,作者使用滑动窗口来将黑话转换为拼音形式,并通过计算其和已有黑话间的编辑距离来判断相似程度。而对于同态黑话,作者使用了四字号码(可理解为一种感知哈希算法)来计算中文字符间的相似度。
Tag Embedding Mechanism
仅关注网页文本内容会带来噪声干扰,而根据文本内容所处的标签位置不同其影响程度也可能不同,因此作者在模型的设计中使用了层次注意力网络并关注了标签和文本内容两个维度。
3、个人思考
本文针对推广篡改的两大特点设计了一种高效的检测系统,并在本地数据集和在野实验中均取得了良好的结果。尽管该系统的设计侧重于检测中文网站篡改,作者选取英文作为对象在文中展示了如何将方法迁移至其他语境。然而,系统的效果依赖已知的黑话语料库,并且文章没有讨论检测结果中是否包含黑话语料库之外的新型黑话,即系统检测未知黑话的能力。
论文团队信息
通讯作者:杨荣海 电子邮箱:[email protected] 个人主页:https://yangronghai.github.io
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh