2023-7-5 20:6:5 Author: www.forcepoint.com(查看原文) 阅读量:12 收藏
Open source LLMs
Open source LLMs are models which are released to the public, typically through model sharing sites like HuggingFace. Meta released their LLaMA model in February, with major news outlets stating that this was a risky decision, as the model itself is effectively the crown jewels of the entire machine learning operation. Competitors, or lone evangelists can reverse engineer the model itself to reveal the weights of the configured training data, or some of the training data itself.
Then there comes the second risk, which is arguably much greater. As I have proved previously, it is possible to overcome the ChatGPT safeguards, however with Open Source Large Language models there is the concept of built-in censorship, but it is entirely possible to refine a base model to respond to prompts without adding censorship to the model itself.
Refining a Large Language Model
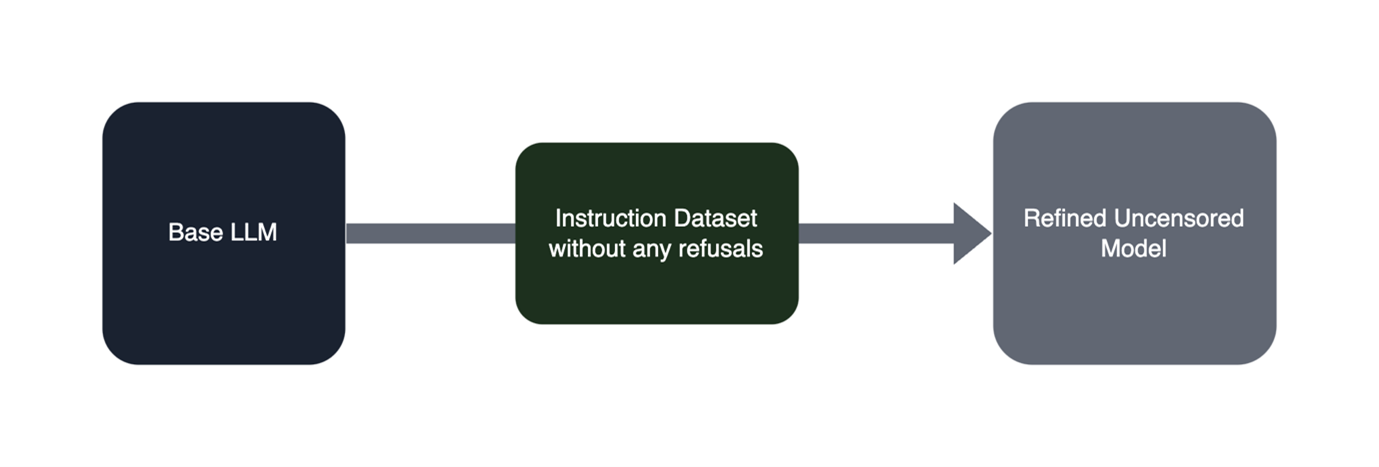
When a Large Language model is built, it is typically created as a ‘base Large Language Model’. This means that there is usually broad language understanding and prediction capabilities, but do not always follow instructions provided in the prompt. For chatbots such as ChatGPT to be able to accurately follow instructions, they must be first Instruction Tuned.
This means taking the original base Large Language Model and refining it with an instruction-based dataset with built in ‘refusals’. This is where certain prompts should be labelled as unethical or immoral and a refusal is put into the model itself to ensure the model does not respond to inappropriate requests. A prominent example of this was in January when it was revealed that workers in Kenya were paid less than $2 per hour to refine the output of GPT and ChatGPT by labelling input and output content as part of the model refining process.
The lack of censorship with Open Source LLMs
However, there has been a rise in demand and interest for ‘uncensored’ chatbots that use Large Language Models. An uncensored chatbot is a model without those same refusals that are put into the likes of ChatGPT and Bard, and thus does not have the same guardrails that a closed source and hosted platform has like ChatGPT.
The risk here is obvious— if you were to ask the chatbot to generate misogynistic, racist, or even content that could pose a risk to national security, it will happily comply and generate that content without any refusals or warnings that the content generated could be illegal. Conversely, If the same was to occur with ChatGPT or Bard, your inappropriate prompt would be logged and the response would not be generated. Worst still, the refined uncensored model can generate responses locally on a single desktop without the need to talk to the internet.
The ’trainer’ of the base model can do this by manually removing the refusals within the instruction dataset itself. This means that instead of learning about any refusals, the model will simply comply with all requests regardless of legality or morality.

The argument for this however, is that commercially released LLM chatbots will always be biased, towards the viewpoint of the large technology companies that develop and refine the models that are most used. We have seen real-world examples of this; back in March David Rozaro ran several political orientation tests against ChatGPT and found that it was both left wing and liberal in its natural biases. Researchers at the Allen Institute for IT also found when prompted with specific questions, ChatGPT revealed racist biases.
In my opinion, the rise in more “GPT-like” chatbots that caters to a wider audience in terms of their beliefs and viewpoints is a good thing. Uncensored, open sourced, unregulated LLMs offer a way to achieve this. However, while these modern general purpose, uncensored open source LLMs are extremely powerful pieces of software, they need to be treated as the significant potential risk they are since they can do things like generate unethical, even illegal content. At its worst, uncensored LLMs could be used to cause harm or pose a real threat to national security.
When it comes to technology, we know bad actors will use it for personal gain. This is especially true when looking at uncensored open source LLMs. It’s one area of AI that needs to be regulated and monitored closely by global governments and organizations alike.
如有侵权请联系:admin#unsafe.sh