1 背景
1.1 什么是外卖搜索导购?
搜索导购是外卖搜索中的个性化搜索词建议模块的统称,在搜索路径中的各处为用户提供引导,提升用户的选购效率。下面按照用户使用外卖搜索的路径来介绍搜索导购的各个模块:① 用户进入外卖首页,美团在顶部搜索框的内部和下方分别提供搜索建议,即框内词和框下词;② 用户点击搜索框会进入到搜索引导页中,我们在历史搜索下方的搜索发现中提供搜索建议;③ 用户在搜索框中主动输入搜索词后,将会唤起搜索词联想功能,即搜索SUG,为用户提供补全搜索词的建议;④ 用户发起搜索后将进入到搜索结果页。
整体流程如下图1所示,其中红框部分即为本文讨论的重点:框内词、框下词以及搜索发现模块。

1.2 为什么要做智能陪伴型的外卖搜索导购?
在餐饮领域,用户体验永远是线下商家优化的重点。其中,导购服务直接影响着用户的购前决策,对商家的转化率和营业额有着重大的意义。像海底捞等商家甚至主打极致的用户体验,通过无微不至的店员服务让用户感到“时时刻刻被关怀”。外卖服务将餐饮消费场景从线下搬到了线上,用户通过搜索/推荐场景找到自己感兴趣的商家和菜品,但相较于线下环境中有“时刻关怀着”的店员,线上这个过程显得较为“被动和冰冷”。
基于以上灵感,我们决定从2022年开始着力打造智能陪伴型导购。在用户使用搜索/推荐时,我们围绕用户表现出的兴趣主动提供更智能的搜索建议,更好地承接用户实时变化的意图和被激发出的灵感。同时,我们也解决了用户打字输入成本高、不知道附近的供给能否满足他们的需求以及不知道如何清晰表达他们的需求等三个方面的痛点。
2 问题与挑战
如何将智能陪伴型导购这一充满“赛博朋克”感的构想在美团外卖场景进行落地呢?我们遇到了以下的挑战:
- 挑战1:线下的导购追求一对一的极致实时的个性化体验,而外卖搜索的导购如何由被动导购(用户手动刷新才会触发导购系统的刷新)变为主动导购(智能感知和判断用户在什么时间、什么场景需要针对性的刷新导购),强化用户实时的个性化体验,智能感知和判断用户每一个需要服务的场景?解决方案:借助美团自研的Alita端智能[1][2]的意图感知能力,智能判断何时需要针对性地刷新。同时,对模型引入实时异构行为序列进行建模,打造端云结合排序模型,感知用户实时多变的兴趣。
- 挑战2:导购的优化除了满足用户体验之外,还需要为整体的转化目标负责,如何让导购的优化与下游场景/整体场景的优化目标保持一致?解决方案:对全场景数据进行统一建模,打造基于自监督学习的统一模型,在对样本进行“无效”过滤以及归因的基础上,同时联动搜索结果页进行全链路的多目标效率优化。
- 挑战3:如何像基于大模型对话入口一样将用户在物理世界的行为转化为机器/算法可以理解的信息,并像真人导购一样和用户“对话”?解决方案:我们后续计划通过对用户行为的理解,尝试在适当时机主动将用户引导到大模型的对话入口,满足其深度对话的需求。
3 主要工作
我们将以上提到的问题和挑战作为主线,分为两个章节进行详细介绍。其中在3.1章节介绍框内词智能刷新,3.2章节介绍导购Query推荐全场景统一模型。
3.1 框内词智能刷新
3.1.1 智能刷新推荐框架
整体链路
上文提到,要实现框内词智能刷新,搭建出一套适用于外卖的、基于端智能框架的Query推荐系统非常重要。搭建思路可以用4W1H来总结:
- Where/How:框内词智能刷新的Query展示在哪?框内词智能刷新的Query的展现形式是什么?(涉及产品形态)
- Who/When:框内词智能刷新需要对什么样的用户触发?在什么时机下触发?(涉及用户意图感知)
- What:框内词智能刷新需要展示什么?(涉及算法策略)
在对上述问题进行深入思考和多方探讨后,我们最终与产品、端智能、客户端、应用服务和推荐工程等相关方一起,搭建了适用于外卖导购的框内词智能刷新Query推荐链路:

上图2展示了从“用户点击首页Feed商家卡片”开始,到框内词智能刷新的Query展现”的全流程。当客户端收集到用户进店行为后,调用Alita的意图感知引擎;满足框内词智能刷新的触发条件后,对用户在端上的进行特征处理、计算和存储,并将计算好的特征传递给客户端组装框内词智能刷新的请求;框内词智能刷新的请求经过应用服务层的Disptch透传给Query推荐的后端服务,经过召回、排序、过滤、机制、封装阶段,最终返回框内词智能刷新的结果到客户端进行展示。
产品形态
早期导购服务在用户进入外卖首页时会主动触发刷新,但除非用户手动触发刷新操作,框内词会一直轮播首次刷新时的结果,造成了大量的流量浪费。
为了解决这个问题,我们尝试利用基于Alita的意图感知能力。如视频演示,当用户在首页浏览商家并加购菜品“【爆款】麻酱凉皮”后返回首页,吸顶的搜索框中的框内词会自动更新,并轮播到新的搜索词“凉皮”,同时展示擦亮动效。当用户点击搜索按钮后,会直接跳转到搜索结果页,展示更多与凉皮相关的商家及菜品,帮助用户进行选购。
3.1.2 智能刷新推荐策略
端实时信号收集
用户实时的下单兴趣与用户在主页、店内的实时行为有着较强的关联,如何通过端上实时信号的收集能力去获取、加工实时行为以便于推荐系统更好理解用户意图是我们关注的重点。相比服务端,用户在端上的特征主要有以下两个特点:
- 实时性更好,从“准实时”到“超实时”的交互;
- 维度更细,从“交互Item”进化到“Item交互的Micro-粒度”[3]。
因此,借助端智能的能力,我们不再受限于用户主动下拉请求刷新的机制,能够实时感知用户实时行为、偏好,实时智能决策更新推荐结果,缓解反馈信号感知延迟问题。
我们梳理了用户点击商家卡片后在店内以及店内商品详情页的主要行为,利用Alita在端上信息收集的能力,获取了当前Session内的商家的点击信息及在店内其停留时长等信息,同时我们记录了用户在店内针对菜品的各种行为,具体包括查看、点击或者加购等,以参数的形式传给后端供推荐排序策略使用,更细粒度地捕捉用户实时变化的述求。
端实时触发策略
为了探索最优的触发条件,我们根据用户在店内的不同行为和用户停留时间,结合如下图4所示的用户店内停留时长分布以及用户首页点击数量分布,尝试了菜品点击菜品、加购菜品等行为触发,停留时长(10s/5s/2s/0s)触发等条件。
实验证明,放宽触发条件虽然会通过增加框内词智能刷新请求的曝光量,覆盖更多的用户,有利于后续策略迭代,但也会增大不置信触发的风险,导致框内词的效率下降。最终,我们选定将进店大于2s或者进店点击过菜品作为智能刷新的触发条件,两个条件满足其一即可。
此外,考虑到用户在店内浏览商家详情页期间会点击或加购不止一个菜品,而且用户在商家详情页的停留时长越长、用户行为越丰富,服务端的推荐结果也就越精准,所以我们没有选择当用户满足触发条件后(进店大于2s或者进店点击过菜品)立即触发作为我们的触发时机,而是选择对于满足触发条件的请求,会在“用户从首页Feed的商家详情页离店后立即触发”作为我们的触发时机。
这么做的好处是,离店时会将用户在店内的所有行为通过客户端带到服务端,帮助智能刷新系统可以更精确地捕获用户的喜好,同时还可以减少同一商家内多次触发带来的不必要的性能开销。同时为了缓解性能的压力,我们设置了同一Session内最多触发30次刷新的策略限制,经过统计该策略覆盖的UV超过90%,已经可以满足我们的需求。

在线效果及线上指标计算口径如下:
- 搜索UV_RPM = 搜索实付交易额/ 搜索曝光人数(DAU)* 1000
- 搜索UV_CXR = 搜索交易用户数 / 搜索曝光人数(DAU)
- 框内词UV_CTR = 框内词点击用户数 / 框内词曝光用户数

智能刷新召回策略
通过数据分析,我们发现14.9%的用户会在进店行为后发起搜索,且此种情况贡献了搜索20%的QV,证明了搜/推场景联动可以帮助外卖场景“新动线”(搜索联动推荐联合优化,带动外卖全局的增长)的推进。进一步分析发现,以上情况下,60%的用户的搜索Query与用户Last-Click行为存在强相关性,表现为用户通常会在点击商家后继续搜索Last-Click店铺相应的品牌或者主营品类。
基于以上分析,本文对召回策略进行优化。与用户手动刷新框内词的请求不同,我们对框内词智能刷新系统的召回进行了以下两点优化,一个是对于Trigger实时性的优化,另一个是为了更贴合用户实时的兴趣意图,我们利用更实时的Trigger设计了多种X2Q的召回[3]。
- 端云联动的Trigger实时性优化:通过将端上Alita的特征透传到用户兴趣中心Tribe中,在Tribe中实现端特征解析加工,使Tribe拥有更加实时的用户特征信息。我们融合了在端侧收集到的实时信号以及云侧用户兴趣中心收集到的实时点击序列,将最近一个商家作为我们的触发Trigger。
- 新增POI2Query召回:根据商家历史30天搜索成单数据,聚合搜索场景下单到当前POI的Top Query集合,得到搜索成单商家Query召回;通过挖掘过去30天用户在点击对应POI后搜索的Top Query集合,得到点击商家后搜索Query召回。
- 新增SPU2Query召回:利用端上获取到的触发框内词智能刷新的点击和加购SPU信息作为Trigger,根据SPU历史30天搜索成单数据,聚合搜索场景下单到当前SPU的Top Query集合。
- 新增POI2Query2Query召回:早期的优化验证了POI2Query的有效性,所以我们通过Swing CF的方式理解计算了Query之间的相似性,将用户触发端智能的POI泛化的Top1的Query作为Trigger,泛化出相似的相关Query。
我们在线上进行了多组召回的消融实验,具体效果如下表:

智能刷新排序策略
基于端/云融合排序模型:鉴于场景冷启,我们刚开始直接使用了非智能刷新场景的导购排序模型(用户手动刷新场景调用的框内词模型),该模型引入了用户实时商家点击序列、实时搜索序列以及用户的Last Behavior进行联合建模。由于智能刷新场景有实时性要求更高的特点,如图5所示,我们在用户行为序列的使用中,融合了端上搜集的更为实时的信号,提升了用户行为序列的实时性。

基于预训练的自监督学习模型(利用用户主动输入数据进行预训练,场景数据Fine-tuning的方式进行学习):为了更好地学习到本场景内用户的兴趣偏好,本文在词服务多场景建模的模型中加入了智能刷新场景内的数据进行模型迭代。为了防止因为新场景数据较少导致过拟合,我们利用用户主动输入数据进行预训练,场景数据Fine-tuning的方式进行学习,并取得了不错的效果,详细做法见3.2。
线上消融实验的具体效果见下表:

3.2 导购Query推荐全场景统一模型
随着端智能在导购场景的应用,词服务场景已经扩展到了如图1所示的五个场景(框内词、框下词、搜索发现、框内词智能刷新以及猜你想搜)。然而,如果每个场景都单独迭代一个模型,这将耗费大量时间和精力。此外,单场景模型无法利用多个场景的共性进行辅助学习。对于新场景或小场景等训练数据较少的场景,直接使用单个场景的数据进行训练,很容易导致过拟合问题。因此,我们尝试统一导购的五个Query推荐场景的模型。
下面,本文将从特征建设、样本建设、用户实时异构行为序列建模、导购联动搜索结果页全链路多目标效率优化以及基于自监督学习的全场景统一模型等五个模块分别介绍我们的工作。
3.2.1 特征建设
特征在排序的效果中,起到非常重要的作用,基于外卖搜索导购的实际场景,结合外卖推搜特征Matrix规范及特征重要度分析,如下图6所示,我们从User、POI、Query、Context以及组合等5个维度[4]入手来构建外卖导购特征Matrix,特征数量共120+。

- User维度:该维度包括用户在不同时间窗口内的不同行为统计特征,比如时间窗口可以选择1天/7天/30天/60天/180天等,行为特征主要有搜索行为、点击行为以及购买行为等,以此来表征用户的兴趣。
- POI维度:主要是POI在不同时间窗口的行为统计特征来表征POI的热度,时间窗口和行为类型参考User维度的设定,除此之外,还包括POI的商家分类等基础属性信息。
- Query维度:主要包括Query的搜索量、点击率以及成单率等统计特征,此外还包括Query的商家分类及分词信息。
- Context维度:主要是时间,如时段、星期几、节假日;场景特征,如当前所处场景(框内、框下、搜索发现)等等。
- 组合维度:Context-Item组合维度,组合Areaid_x_item以及Period_x_item的交叉维度,挖掘不同时段下Item的曝光点击率等特征;User-Item组合维度,User在不同时间窗口内对Item搜索、点击等行为次数等。
除了上面提到的5种维度的特征外,为了配合异构行为序列建模,我们也设计了用户的异构序列特征,该部分在3.2.3中详细介绍。
3.2.2 样本建设
“无效”样本过滤
在用户点外卖时,打开美团外卖App会默认访问外卖首页,同时会默认曝光词服务。因此,无论用户是否想浏览词服务,前端都会对其进行曝光,同时在引导页的搜索发现也是同理。而传统的点击率模型的样本标注会将曝光未点击Item标注为负样本,因此对那些并不是想浏览词服务的用户(如进入App就直接去了主列表或者金刚页),就会引入有偏负样本,即把用户可能只是因为没注意到词服务而没点击的样本,都算成了用户不想点击的负样本,从而使得训练与评估样本集不能精确反映用户的兴趣偏好。
为了消除上面提到的有偏负样本的影响,我们基于搜索导购词服务的实际场景特点(框内词、框下词在首页默认曝光及搜索发现在引导页默认曝光),我们进行了“无效”样本过滤,对于是否“无效”的定义,我们进行了以下尝试和探索:
- User维度的“无效”样本过滤:通过统计用户在过去的历史7天内对导购有无行为,如果有过点击行为,我们认为这部分用户是可以感知到导购功能的,保留其所有的请求数据,而对7天在导购无行为的用户,如果本次请求中用户没有任何点击,我们会将本条请求的样本全部过滤掉。具体的,在首页如果用户在当前请求对框内词和框下词都没有点击,我们会将本次请求的样本全部过滤,同理该策略也会使用在引导页的搜索发现样本上。
- Session维度的“无效”样本过滤:如果当前Session内用户在导购内有点击行为,我们会将Session内所有请求样本都保留,反之我们会认为本次Session用户没有感知到导购,会将本次Session内所有请求样本视为“无效”样本。
- QV维度的“无效”样本过滤:如果当前请求用户没有任何点击行为,我们会将本次请求的样本视作“无效”样本。具体的,在首页如果当前请求框内词和框下词都没有点击的样本,我们会将本次请求的样本过滤,同理该策略也会使用在引导页的搜索发现样本上。
可以看到,User维度->Session维度->QV维度是过滤条件依次收紧的过程,通过下表的离线实验我们发现,对于三个场景GAUC的表现上,QV维度的“无效”样本过滤效果最佳。

我们将离线最优的版本(QV维度“无效”样本过滤)在线上进行了实验,效果如下表所示:

搜索多场景样本归因
在外卖搜索导购中,每天有数百万用户浏览了某个Query之后虽然没有在导购对其点击/下单,却在搜索其他入口(SUG/主动搜索)对其点击/下单。例如在图7的左图中,框下词模块为用户推荐出“川菜”,但是用户没有使用框下词,而且去主动搜索“川菜”,进而在SUG/主动搜索下单,同理在图7的搜索发现模型也存在相似的情况。
然而,在导购精排模型的样本中会将在本场景曝光未点击的样本视为CTR/CXR的负样本,因此模型在训练时会收到这些Query不符合用户点击/成单偏好的监督信号,从而学着去将它们排得靠后,造成模型优化的方向与实际中这些Query满足用户点击/成单偏好的事实相反的偏差。因此,我们需要解决这一Query推荐场景下的样本归因偏差问题,来提升外卖搜索场景下的千人成交率。

为解决这一问题,关键在于要让模型具有预估导购内点击/成单能力之外,还要有预估用户搜索全局点击/成单的能力。为此,我们将模型中的CTR/CXR的预估目标,由曝光后导购入口内点击/成单概率升级为曝光后搜索全局点击/成单概率这样一种可落地的实现方式。
基于这一方案,我们在构造样本时,抓住关键细节,为严格保证搜索全局点击/成单Label的物理含义,对于导购入口曝光未点击/成单,之后搜索其他入口(如SUG/主动搜索)有点击/成单的情况,只在样本中将最接近成交时间戳的导购入口曝光的未点击/成单负样本修正为点击/成单正样本。经数据分析,我们发现上述搜索全局成交归因建模方式可对每天的训练样本扩充约30%的点击/成单正样本,有较为充足的影响面。
由于样本归因偏差建模修改了Label,因此需要一个新的离线评估准则。为了评估模型的有效性,我们回归问题本质,仍抓住模型是否做到了保证对本入口点击/成单样本的预估能力的基础上,具有了更强的搜索全局点击/成单预估能力的关键要点,来构建评估体系。
具体地,我们交叉评估基线模型与搜索多场景样本归因纠偏模型的CTR/CXR预估,分在导购入口内点击/成单样本及在搜索全局点击/成单样本上的GAUC。结果显示,搜索多场景样本归因模型,在保证对导购入口点击/成单样本的排序能力基本不降的同时,显著提升了对搜索全局点击/成单样本的排序能力,进而证明模型的有效性。
全网成交纠偏模型的在离线效果如下表所示:

我们将全网成交纠偏模型在线上进行了实验,效果如下表所示:

3.2.3 用户实时异构行为序列建模
用户兴趣建模一直被业界认为是实现排序结果“千人千面”的关键,是个性化排序系统中必不可少的一个模块。虽然用户兴趣建模已有诸多研究,但结合外卖搜索业务本身的LBS特色进行用户兴趣建模,仍是一项不小的挑战。目前,词服务模块在用户行为兴趣向量上的探索还处于空白阶段,于是我们决定对词服务模型进行用户兴趣建模,以此来提升模型捕获用户兴趣的能力。
搭建导购用户兴趣建模五维体系:如图8所示,我们搭建了理想版的导购用户兴趣建模五维体系,形成了“行为周期、行为情景、行为模式、行为表示、兴趣抽取”用户兴趣五维建模体系迭代认知[5]。

首先,用户兴趣是随着时间动态变化的,为了更好地理解用户的兴趣偏好和需求,我们可以按照行为周期维度将用户的全周期兴趣划分为用户实时兴趣、短期兴趣和长期兴趣。
其次,外卖LBS特性导致用户在不同的LBS情景下具有不同的行为偏好,归结为行为情景维度。
再次,结合外卖本身业务特色,用户的主要行为包括搜索/浏览/点击/加购/下单等行为,将这一系列动作归结为行为模式维度。
最后,业界用户兴趣建模同样面临的问题,使用哪些行为特征来表示用户兴趣,将这归结为行为表示维度,以及如何对用户兴趣进行抽取得到最终兴趣向量,归结为兴趣抽取维度。可以说,“行为表示”决定了用户兴趣表示的上限,“兴趣抽取”决定了逼近用户兴趣表示上限的可能。
实时异构行为序列选取:与传统的商家推荐建模方式不同[6],我们在建模用户对商家的行为序列的同时,根据搜索导购的场景特点,将用户的实时搜索序列和商家泛化Order-Query等异构序列联合建模,以保留场景特色并取得更好的效果。为了帮助模型从行为序列中更精准地捕捉到用户的兴趣,我们引入了序列的Sideinfo信息来辅助学习,在行为表示上,我们引入点击商家ID和Query ID以及基础类特征:商家名、商家Tag、Query分类、Query分词等特征;在行为情景上,我们将LBS特性作为上下文特征:就餐时间、区域、距离。
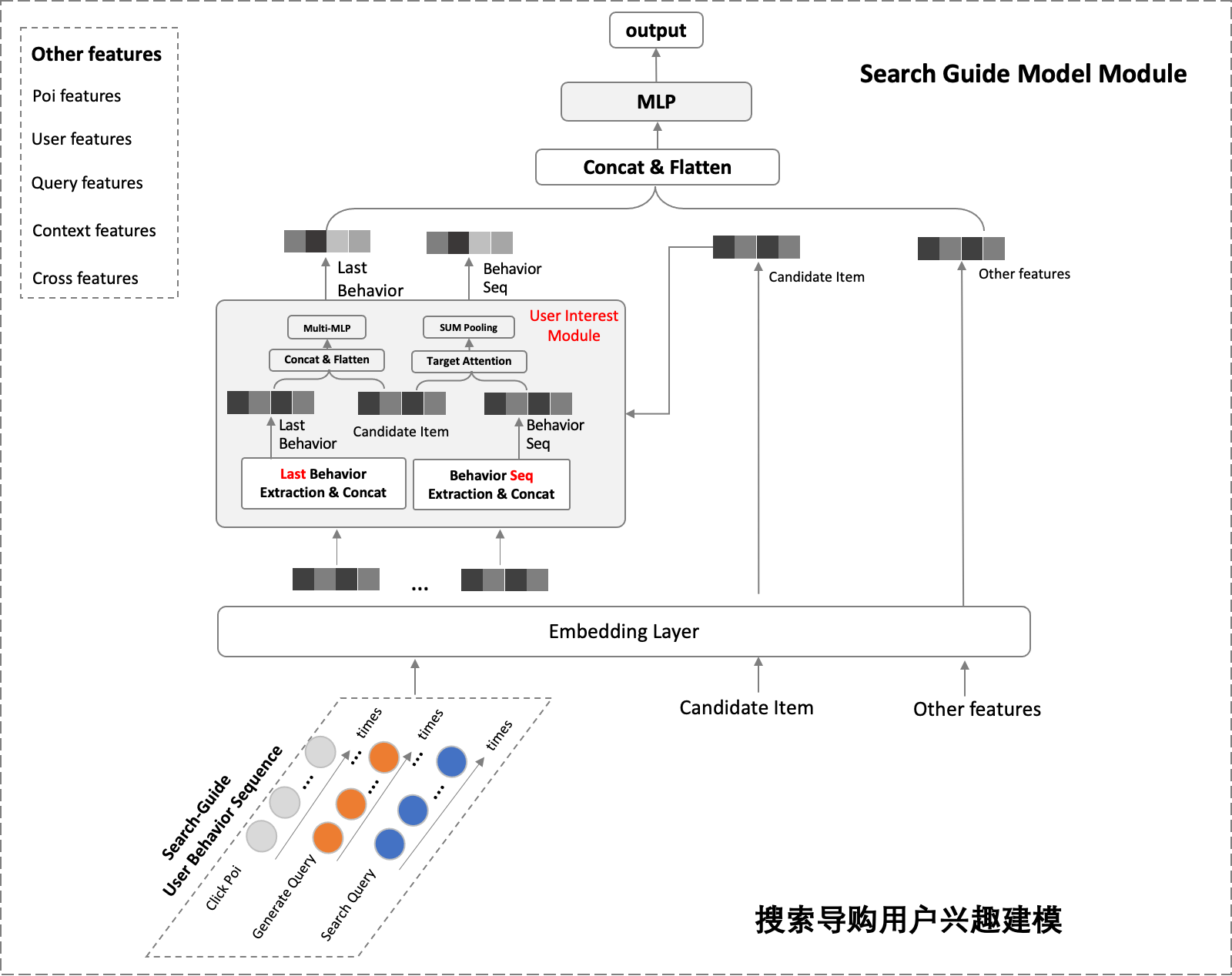
异构行为序列建模:用户行为序列蕴含了非常丰富的用户兴趣和偏好信息,目前主流方法是将用户行为序列中的Item进行Pooling后的结果来表征用户兴趣,这种方式的假设是用户行为序列内的Item对用户兴趣的贡献是等价的,但容易存在噪声。Guorui Zhou等提出的DIN模型[7],认为用户行为序列内不同的Item对用户当前的兴趣,贡献是不同的,通过Attention来刻画这种贡献。因此,我们将模型从DNN升级为DIN,模型结构如下图9所示:

我们将收集到的用户行为序列以及其对应的Sideinfo喂到如下图所示的模型中,Behavior Seq与Target Item进行Target Attention后进行聚合,得到用户的兴趣序列表示,同时由于在早期的尝试中得到了用户Last Click行为十分高效的结论,所以我们将用户三个序列的last行为还进行了单独建模,将三个序列的Last行为及Sideinfo与Target Item进行聚合,然后经过一个MLP,得到用户最实时的兴趣表示。将上述的两个兴趣表示与Target Item以及Other features聚合后经过MLP后,得到Output。
我们对用户实时异构行为序列建模进行了多组离线的消融实验,离线效果如下表所示:

我们将离线最优的版本(3个序列+3个Last行为)在线上进行了实验,效果如下表所示:

3.2.4 导购联动搜索结果页全链路多目标效率优化
导购场景作为引流入口,外卖用户在导购的成单路径可以抽象为[1]导购Query曝光->[2]导购Query点击->[3]搜索结果页曝光->[4]搜索结果页点击->[5]搜索结果页加购->[6]搜索结果页成单。如果优化目标仅考虑导购场景内的信号“场景内的CTR作为目标”,却并未直接面向搜索场景的整体效率,即联动搜索结果页的用户反馈来优化,存在局部最优的问题。为此,我们引入词服务下游场景,即搜索结果页的用户反馈信号,并进行词服务PV维度的归因,构建CXR目标并进行建模。
基于以上背景,我们将单目标的导购精排模型升级为多目标模型,增加搜索结果页成单的目标,基于Share-Bottom的结构进行多目标联合建模。为了建模两个目标的共性,同时考虑到CXR是在CTR条件下发生的行为,于是我们采用了Bayesian的思想,将CTR网络的最后一层的输出Concat到CXR的上面,再计算CXR的Logit。模型结构如图10所示:

在机制上,我们通过机制公式融合CTR和CXR两个目标$S \text { core }=w{1} * p C T R+w{2} * p C X R$。在通过多组实验验证,当时,在线效果达到最优,后续计划尝试离/在线多目标寻参。
我们对导购联动搜索结果页全链路多目标效率优化进行了多组离线的消融实验,离线效果如下表所示:

我们将离线最优的版本(多目标优化+CTR输出Concat到CXR)在线上进行了实验,效果如下表所示:

3.2.5 基于自监督学习的全场景统一模型
随着“陪伴型”导购场景在搜索各个模块的不断落地,Query推荐场景已经扩展到了五个。然而,单独迭代每个场景的模型面临着如下挑战:
- 小场景和新场景训练数据不足。多个Query推荐场景中,对于新场景(例如框内词智能刷新、猜你想搜)训练数据比较少,直接用单个场景反馈数据训练,会导致过拟合问题;
- 多个场景统一建模。能否同时利用多个场景的数据,建模多个场景的共同点、不同点,提升多场景排序模型的效率呢?
- 反馈闭环问题[8]。目前这种偏向效率的训练方式,会导致排序系统展示出来的item通常具有高频的特点,很多长尾的item没有曝光的机会,马太效应严重,不利于生态的长期健康成长;
- 降本增效。对于多个相似场景,如果每个场景都单独迭代一个模型耗时耗力,同时也需要大量的机器资源。
为了解决以上问题,我们采用了一种基于自监督学习的全场景统一建模的方法[9]。这种方法采取了Pre-training和Fine-tuning两个阶段的方式。通过数据统计,我们发现用户历史搜索行为前后具有关联性。
因此,在预训练阶段,我们借鉴了语言模型BERT[10]中Next Sentence Prediction(NSP)和GPT[11]中Next Word Prediction(NWP)任务的思想,利用用户历史行为数据和用户主动输入的信息(SUG以及主动搜索数据),学习预测用户下一个输入的Query(Next-Query Prediction)。在Fine-tuning阶段,我们使用各场景的隐式反馈数据来Fine-tuning得到全场景统一模型。
由于在预训练阶段让模型见到了更多其他场景的Query,我们可以在一定程度上缓解反馈闭环的问题。同时,在Fine-tuning阶段使用了全场景数据并对场景信息进行建模,所以我们的多个场景统一模型可以在缓解小场景和新场景过拟合问题的同时,还可以兼顾建模出不同场景的共性和特性。下面将分别介绍Pre-training和Fine-tuning。
Pre-training预训练:因为用户主动输入的Query正是Query推荐排序模型理想的结果,所以我们基于用户历史行为,预测下一个用户主动输入的Query。下面我们分别从样本构建、特征Matrix以及预训练流程三部分介绍Pre-training的过程。
- 样本构建:我们使用SUG以及主动搜索场景内数据,采用类似于3.2.2的思想。例如,当用户输入“和府捞面”时,SUG曝光了该Query,但是用户没有点击,而是直接点击搜索按钮主动搜索“和府捞面”,对于这类SUG曝光未点击,但是发生了主动搜索的情况,我们将主动搜索的点击数据归因到SUG数据中。

特征Matrix:在Pre-Train的模型中,挑选出SUG和词服务共用的特征进行预训练,包括用户兴趣建模方面的序列特征以及用户画像特征等。在Fine-Tune阶段,我们会预加载Pre-Train的特征,然后增加了Dense Features和Scenario Features。
预训练流程:我们设计的预训练任务是基于用户历史行为,预测下一个用户主动输入的Query,因为用户主动输入的Query正是Query推荐排序模型理想的结果。由于简单地随机采样会使得负样本过于简单,因此我们采样用户主动搜索Query时SUG曝光未点击的Query作为困难负例[7]。

Fine-tuning微调:利用词服务场景数据微调预训练模型,学习多个场景之间的共性,同时加入场景信息,学习多个场景之间的不同。如上图12所示,由于预训练阶段没有Dense Features和Scenario Features,因此Prediction Layer的输入维度不同,所以Prediction Layer的参数没有共享,两个阶段共享的是Embedding Layer和行为序列建模的部分。实验发现,Fine-tuning阶段固定住Query和POI Embedding时,效果最好。因为这两个Embedding参数量为亿级,训练数据不充分时容易过拟合。同时,我们也通过对比,直接将用户主动行为数据融合到词服务数据中进行训练,实验结果证明了预训练的有效性。
打破反馈闭环:我们分析了在三个场景(框内词、框下词以及搜索发现)的数据,对比了有无预训练的模型半个月内给所有用户推荐出的Unique Query的个数,我们发现当加入预训练后,可以显著提升推荐出的Query多样性,三个场景分别增加9.6%、13.6%以及10.8%的Unique Query的个数,打破了推荐闭环。
后续计划:结合大模型预训练的全场景统一模型,借助大模型更强大的表征和泛化能力,我们计划后续利用大模型对Query的Embedding进行预训练,然后利用本场景内的数据进行Fine-tuning,从而提高模型在导购全场景的推荐效果和泛化能力。
我们对基于自监督学习的全场景统一模型进行了多组离线的消融实验,离线效果如下表所示:

我们将离线最优的版本(预训练+微调阶段不更新Query和POI Embedding)在线上进行了实验,效果如下表所示:

4 总结与展望
本文介绍了我们在外卖智能陪伴型导购的探索与尝试,其中主要包括:
- 借助Alita端智能的意图感知能力,智能判断何时需要针对性的刷新,将被动型导购变成主动型导购。
- 为了追求和线下导购一样一对一极致的实时性的个性化体验,我们在对模型引入实时异构行为序列进行建模的同时,打造端云结合排序模型,捕获用户实时多变的兴趣。
- 导购的优化除了满足用户体验之外,还需要为整体的转化目标负责,我们对全场景数据进行统一建模,打造基于自监督学习的统一模型,在对样本进行“无效”过滤以及归因的基础上,同时联动搜索结果页进行全链路的多目标效率优化。
目前智能陪伴型导购已经在外卖搜索全量,累计收获了如下收益:
- 搜索DAU +1.02%、搜索UV_RPM +1.70%。
- 搜索框内词UV_CTR +187%、搜索框下词UV_CTR +141%、搜索发现词UV_CTR +121%。
未来,我们将从以下方向进行探索优化:
- 智能刷新赋能更多场景:在搜索结果页以及外卖首页Feed页,利用端智能的意图感知能力,判断用户兴趣发生收敛的时机,利用导购Query推荐的能力,响应用户更细粒度的需求表达,满足用户找同类商家、找同品牌商家、找用户感兴趣的商品或者品类的需求。
- 借助大模型的能力赋能导购模型:结合大模型预训练的全场景统一模型,借助大模型更强大的表征和泛化能力,我们计划后续利用大模型对Query的Embedding进行预训练,然后利用本场景内的数据进行Fine-tuning,从而提高模型在导购全场景的推荐效果和泛化能力。
5 本文作者
翔锟、营飞、关璐、泽钰、张聪、晓鹏、北海等,来自美团到家研发平台/搜索推荐技术部。
运祥、周全、张晶等,来自到美团外卖事业部/产品部。
6 参考文献
- [1] Gong Y, Jiang Z, Feng Y, et al. EdgeRec: recommender system on edge in Mobile Taobao[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 2477-2484.
- [2] 端智能在大众点评搜索重排序应用实践
- [3] 交互式推荐在外卖场景的应用
- [4] 美团外卖推荐情境化智能流量分发的实践与探索
- [5] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction- [C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1059-1068.
- [6] Wenlong Sun, Sami Khenissi, Olfa Nasraoui, and Patrick Shafto. 2019. Debiasing the human-recommender system feedback loop in collaborative filtering. In WWW’19. 645–651.
- [7] Gu Y, Bao W, Ou D, et al. Self-Supervised Learning on Users’ Spontaneous Behaviors for Multi-Scenario Ranking in E-commerce[C]//Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021: 3828-3837.
- [8] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
- [9] Radford, Alec, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. “Improving language understanding by generative pre-training.” (2018).
招聘信息
搜索推荐算法工程师
- 了解大规模深度学习、图学习等技术,利用注意力机制、记忆网络、关系网络等模块,从跨多个时空VV场景的海量数据中理解用户需求、发掘用户兴趣,优化点击率、转化率模型,为用户展示更合适、更感兴趣的美食和商品。
- 了解强化学习、可解释深度学习、多模态学习、多目标优化等技术,优化重排、混排模型,智能调控流量分发,优化平台生态,实现消费者和商家共赢。
- 能够使用知识图谱、计算视觉、自然语言生成等技术,面向用户兴趣,帮助商家自动化智能生成展示内容和文案,提升推广效率。
- 追踪并研究人工智能前沿技术,探索技术在零售、医疗电商场景的应用。
感兴趣的同学可以将简历发送至:[email protected]。期待与大家一起共事,共创未来。
如有侵权请联系:admin#unsafe.sh