2023-7-14 17:10:0 Author: ricercasecurity.blogspot.com(查看原文) 阅读量:16 收藏
Author: hugeh0ge
This article is Part 2 of the 4 blog posts in the Fuzzing Farm series. You can find the previous post at "Fuzzing Farm #1: Fuzzing GEGL with fuzzuf."
As mentioned in Part 1, our Fuzzing Farm team uses our fuzzing framework, fuzzuf, to find software bugs. It's not just the Fuzzing Farm team that works with fuzzers in our company; many situations arise where we need to evaluate the performance of different fuzzers, both in the development of Fuzzuf itself and in other research.
However, there is little organized documentation about evaluating fuzzers, and numerous pitfalls exist in benchmarking. Without careful evaluation, one may draw incorrect conclusions. Does greater code coverage mean better performance? Is a fuzzer that finds more crashes superior?
Evaluating the performance of a fuzzer is a challenging task. Setting up the experiment properly and drawing useful conclusions can be very difficult. Unfortunately, even in academia, where experiments should adhere to scientific standards, researchers sometimes rush to conclusions in statistically incorrect ways, or fail to set up experiments in a way that the fuzzing community recommends.
In this article, we provide some cautions and recommended experimental settings for evaluating the performance of fuzzers. These recommendations are based on our research and experience in performance evaluations.
Before going over the general recommended experimental setup, we will first elaborate on some problems in the performance evaluation of fuzzers.
Ambiguity of Metrics
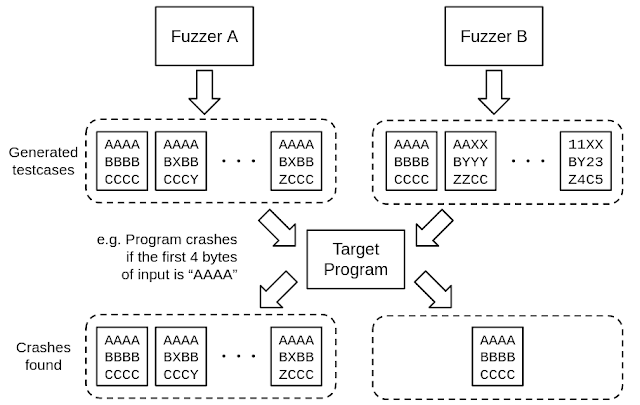
The first challenge in evaluating the "performance" of a fuzzer is to establish an evaluation metric. While the aim of a fuzzer is typically to discover crashes (resulting from bugs or vulnerabilities), some people believe that the more crashes a fuzzer detects, the better its performance.
However, consider the scenario where fuzzer A detects crashes p, q, and r, and fuzzer B detects crashes r and s. Can we conclude that fuzzer A is superior because it found one more crash than fuzzer B? In this case, we must also take into account the fact that fuzzer A could not find crash s (and similarly, fuzzer B could not find crashes p and q).
Thus, if we want to assess fuzzer A's superiority based on this outcome alone, we should focus on evaluating fuzzers that can generally uncover a large number of crashes across a wide range of program-under-test (PUT), without considering the types of crashes that they can find.
Moreover, it is important to note that if we rely on the number of crashes as an evaluation metric, crash deduplication must be as precise as possible. Since a mutation-based fuzzer generates many similar inputs, it creates a large number of inputs that trigger crashes on the same bugs.
Generally, the fuzzer itself lacks the ability to pinpoint the cause of the crash and can only provide a simple classification. As a result, the number of inputs that cause crashes is frequently not equivalent to the number of bugs/vulnerabilities found.
Consider an example where fuzzer A discovers 100 inputs that cause crash r, while fuzzer B identifies only one input that causes crash r. In this case, we cannot merely conclude that there is a difference of 99 in the number of crashes detected. (See Figure 1)
 |
Figure 1. More crashes found in Fuzzer A, but all inputs are causing the same bug |
Moreover, a more fundamental problem is the duration of the experiment. Even if you run fuzzers on real-world software for several days, in most cases, you will only discover a few dozen bugs or vulnerabilities. Consequently, there is usually no significant difference between multiple fuzzers. Especially, if none of the fuzzers can detect any crashes, there is nothing to evaluate.
For that reason, code coverage (the amount of code blocks, etc. that could be reached during fuzzing) is often used as an alternative. It is widely believed (*) that there is a correlation between code coverage and the potential number of crashes that a fuzzer can find, but it is not proportional. Therefore, it is not appropriate to rely solely on code coverage to determine the expected number of crashes.
While it is generally true that higher code coverage increases the likelihood of finding a crash, it is not always the case. For example, if fuzzer A and B have similar code coverage but neither has found a crash, it is controversial to assume that fuzzer A is more likely to find crashes just because its code coverage is slightly higher.
As mentioned above, it is important to pay attention to the values corresponding to the "y-axis," such as the number of crashes and code coverage, but it is also important to pay attention to the values corresponding to the "x-axis." When we compare the performance of fuzzers, the graph is often plotted with the time elapsed on the x-axis and the code coverage on the y-axis. However, depending on the element of interest, it may be better to set the x-axis to the number of PUT executions and compare the code coverage according to the number of PUT executions (see Figure 2).
 |
| Figure 2. Example graph showing the number of PUT executions on the x-axis (From EcoFuzz) |
For instance, let's assume that you have applied some optimization to a fuzzer and you want to measure its effects. If the optimization aims to improve the execution speed, you should evaluate it on a graph with time as the x-axis. This is because the "probability of reaching a new code block in one PUT execution" remains unchanged even if the execution speed increases. Therefore, there should be no difference in the graph with the number of executions on the x-axis. In other words, a way to check for bugs in the implemented optimization is to observe if there is any change in the graph with the number of executions on the x-axis.
On the other hand, if you expect that the optimization will change the "probability of reaching a new code block in one PUT execution" due to new mutation algorithms or other factors, a graph with the number of executions on the x-axis will provide a more accurate evaluation than a graph with time on the x-axis. 1
Another important note on code coverage is that the size of code coverage is not directly proportional to the number of times a new code block is found. When a new code block is discovered, it is often the case that other new code blocks are also found at the same time due to subsequent processing beyond that block.
So, even if a fuzzer discovers 10,000 code blocks, it is natural that the fuzzer's hit coverage increases only around 1,000 times. Therefore, it is important to consider the special characteristics of each fuzzer when evaluating their performance.
For example, two fuzzers cannot be evaluated solely on the basis of whether they hit coverage increases frequently or less often. Other factors such as the actual code coverage achieved and the complexity of the conditions leading to the discovered paths should also be considered.
As shown in Figure 3, both fuzzer A and B have the same code coverage value. 2 However, the number of coverage increases (number of new branches found) and paths reached are different. If fuzzer A can only reach the leftmost path due to poor mutation performance, fuzzer B is considered superior.
On the other hand, if the conditions for reaching the leftmost path are very complex and the rest of the paths are uninteresting procedures such as error handling, then fuzzer A is considered superior for finding the important path. Moreover, depending on the Control Flow Graph (CFG), the code coverage of fuzzer A may be larger or smaller than that of fuzzer B. Therefore, comparisons of code coverage must take into account the unique characteristics of each fuzzer.
 |
| Figure 3. Fuzzer A and B show the same code coverage while the paths found are different |
Uncertainty of the Fuzzer
While a fuzzer generates or mutates test cases, it draws random numbers to produce many different inputs. Since it relies on these random numbers, its behavior is subject to uncertainty. 3 Furthermore, the performance of the fuzzer will depend on how long it runs and the type of PUT. Let’s discuss the problems caused by such uncertainty.
Figure 4 shows the results of some experiments from fuzzbench. The horizontal axis represents the elapsed time, and the vertical axis represents the code coverage (Code Region) at that point. The number of instances running each fuzzer is 14. The thick line with dots represents the average value of the code coverage, and the areas above and below show the 95% confidence interval.
 |
| Figure 4. Coverage of various fuzzers measured for 23 hours |
Based on the graph, we can conclude that aflplusplus_optimal achieves the largest code coverage with a high probability at the end of the 23-hour experiment, both in terms of the mean value and the confidence interval. However, if we had stopped the experiment at 12 hours, the mean value of aflplusplus_optimal would not even come close to that of afl.
Since the increase in coverage is time series data and the trend of the increase is different for each fuzzer, it is impossible to determine whether the fuzzer that is considered the best at a given time will also be the best further down the road.
Having a time series also presents other problems. As mentioned earlier, fuzzers behave randomly, so even if you fuzz the exact same PUT with the same settings, different sources of random numbers can produce very different results. As an example, refer to the graph from the following tweet discussing this issue.
 |
| Figure 5. Coverage of each of the 20 measurements on one instance |
This graph shows the change in coverage when the same fuzzer (aflfast) is run on the same machine 20 times, with time on the horizontal axis and coverage on the vertical axis.
From the graph, it is evident that evaluating performance with a small number of instances is risky. Evaluating each fuzzer with only one instance is roughly equivalent to randomly selecting just one curve from the 20 curves in this graph and looking at it alone. The average behavior of the fuzzer expected from that one curve would be very different from the average behavior expected from all 20 of these curves.
Let's compare the fuzzbench graph that shows only the mean and confidence interval (Figure 4) with the graph that shows the coverage of the actual 20 instances (Figure 5). Although there are differences in measurement time and PUT, the mean value and confidence interval tend to increase smoothly. On the other hand, the coverage of individual instances shows more staircase-like changes.
This is because there are many periods when the fuzzer cannot find a new code block and becomes stuck. As a result, there are periods of time when code coverage does not change for a certain period, causing a plateau (flat area) on the graph. Unless all instances exit the plateau at about the same time, it is unlikely for data such as averages to be stair-stepped.
Therefore, when looking at graphs that show only means and variances, it is sometimes important to keep in mind that the actual coverage of each instance may be a staircase of extremes.
Strong Dependence on Configurations
It is important to note that the performance of a fuzzer can (seemingly) change significantly with just one different experimental setting.
The setting that produces the most noticeable change is the PUT used. Figures 6.1 through 6.3 show the results for several PUTs in the fuzzbench experiment.
 |
| Figure 6.1. Coverage with freetype2-2017 as PUT |
 |
Figure 6.2. Coverage with bloaty_fuzz_target as PUT |
 |
| Figure 6.3. Coverage with lcms-2017-03-21 as PUT |
These figures demonstrate that the fuzzers with the highest coverage in 23 hours differ from PUT to PUT.
Moreover, the same PUT may elicit completely different fuzzer behavior depending on the software version and build. Specifically, the method of instrumentation4 may significantly impact the performance.
The two most variable settings in fuzz testing are the initial seed and the dictionary. To illustrate this point, let's compare a situation where there is no suitable initial seed for a PUT that parses PDF files to one where a single PDF file is provided as the initial seed.
Without an initial seed PDF file, it is unlikely that the fuzzer will be able to reach code blocks beyond the header checks without first identifying the header (and trailer) of the PDF file format. Additionally, without identifying the format of the object and xref that constructs the PDF file, it is impossible to test the routines processing these structures. It is easy to see that the probability of the fuzzer, which only adds relatively simple random mutations, discovering these formats by chance is very low.
On the other hand, if a decent PDF file is given as a seed, there is no need to find the object or xref structure by fuzzing, nor is there a risk of getting stuck in header validation. Additionally, PDF files may contain other embedded formats, such as JavaScript or Color Profile. If we suppose that the less a fuzzer know about the format, the harder it is to continue PUT execution without error and find new code blocks, then giving a diverse set of initial seeds, including ones with other embedded formats, can be very beneficial.
The same principle applies to dictionaries. Including keywords such as %PDF-1.6, %%EOF, /Parent, and xref in the dictionary increases the likelihood that the associated code blocks will be executed. If these keywords are not present, we can only hope that they will be produced by chance during random string generation
Therefore, even if the fuzzer is the same, the difference in prior knowledge given in advance often leads to differences in performance and completely different results.
In addition to initial seeds and dictionaries, there are other ways to provide a fuzzer with prior knowledge. One such way is to adjust hyperparameters. A fuzzer typically has many parameters, which are usually in the form of macros or other compile-time specifications. For example, the AFL family has a hyperparameter called MAX_FILE, which limits the file size generated by the fuzzer. By default, this value is set to 1 MB, which is large enough to generate files of varying sizes. However, if we know that "PUT only accepts input up to 100 bytes and discards any input larger than that," we can lower this parameter to 100. This will reduce the possibility of generating meaningless input and lead to more efficient fuzzing. Even a small change in a single parameter can significantly increase or decrease performance.
We have explained that the performance of the same fuzzer can vary significantly depending on the presence or absence of prior knowledge. So, how does prior knowledge affect the performance of different fuzzers?
To ensure a fair performance evaluation, it is important to maintain the same initial seeds or dictionaries for each fuzzer. By making the experimental conditions as uniform as possible, we can create a valid experimental setting. Whether we start with no initial seed or use 10,000 initial seeds, applying the same conditions to all fuzzers will produce a valid experiment.
However, it is surprising that in some experimental settings, the dominance of the fuzzer can be reversed. For example, consider two settings: one with no decent initial seeds, and another with decent enough initial seeds.
In the first setting, where there are no decent initial seeds, fuzzers with relatively simple random mutations are likely to get stuck. In such a situation, only fuzzers using special algorithms, such as REDQUEEN and concolic fuzzers that have SMT solvers, can reach new code blocks and get out of the plateau.
On the other hand, in a setting with decent initial seeds, it is quite possible to handle the case where you have to generate a specific keyword to get out of the plateau even if only random mutation is used. Not only does the initial seed have the keyword, but cloning and splicing mutations that copy bytes from other seeds also increase the likelihood that the newly generated input will have the keyword.
In other words, the presence of the initial seed has a certain dictionary-like effect. Therefore, special fuzzers may perform better in the first setting, while fuzzers with simple random mutations may perform better in the second setting.
So what is the best experimental setting?
As with the discussion on PUT selection, there is no single correct answer for seed selection. It is best to choose a setting that closely imitates the actual situation in which the fuzzer will be used.
For instance, if the input format is a commonly used one, like a PDF file, there are already initial seeds and dictionaries publicly available that have been optimized over the years. Since these seeds are expected to be used by anyone, it is acceptable to use them for performance evaluation.
On the other hand, if the fuzzer is expected to run in circumstances where prior knowledge is not available, it is reasonable to benchmark in a situation that does not provide prior knowledge. It is important to clearly indicate the purpose of the fuzzer being evaluated and the assumptions made when constructing the experimental setting.
In addition, it is noteworthy that experimental settings are not limited to explicit parameters that can bring about changes. The following is a portion of the AFL code:
/* Let's keep things moving with slow binaries. */
if (avg_us > 50000) havoc_div = 10; /* 0-19 execs/sec */
else if (avg_us > 20000) havoc_div = 5; /* 20-49 execs/sec */
else if (avg_us > 10000) havoc_div = 2; /* 50-100 execs/sec */
.....
stage_max = (doing_det ? HAVOC_CYCLES_INIT : HAVOC_CYCLES) *
perf_score / havoc_div / 100;
.....
/* We essentially just do several thousand runs (depending on perf_score)
where we take the input file and make random stacked tweaks. */
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) {
The code determines how many times to mutate a single seed based on the number of times the PUT can be executed per second. In other words, fuzzing the same PUT with the same fuzzer and experimental settings may exhibit different behavior and produce different results depending on the machine used for the experiment, differences in CPU load, and many other factors. Essentially, a pure fuzzing algorithm should behave consistently regardless of the machine used, but this inconsistency may be caused by optimization for practicality. Therefore, it is important to make efforts to keep not only the experimental setup but also the experimental environment as identical as possible.
In light of the issues raised thus far, we will discuss some recommended experimental settings.
Set up a hypothesis
As with all scientific experiments, it is advisable to avoid conducting experiments without a hypothesis. We should only conduct experiments after clearly defining what we want to demonstrate or confirm. In many cases, experiments without a hypothesis can lead to meaningless results or biases in observation, making it easy to focus on spurious correlations.
Make an evaluation metric
To begin, you must decide which metric to use as the evaluation metric. This can be the number of crashes, code coverage, or some other metric.
If you choose to use the number of crashes, we recommend using MAGMA as the evaluation dataset. Currently, MAGMA is widely recognized as a dataset that allows for complete deduplication of crashes found. If you are unable to use the MAGMA dataset for evaluating the number of crashes, it is necessary to provide a mechanism to deduplicate crashes with the highest possible accuracy. For instance, the deduplication algorithm implemented in the AFL family is very inaccurate and almost useless.
Choosing PUTs and configurations
Unless you have a special motivation, such as debugging purposes, you should always prepare multiple PUTs for performance evaluation. In the author’s experience, it is advisable to use at least 3 PUTs when experimenting with a specific input format (i.e., when you have a hypothesis such as "I want to show that this fuzzer is good at fuzzing PDF viewer") and 6 or more when experimenting with any input format. Experimental results with fewer than 6 PUTs may appear to have some kind of tendency by chance, which is a weak argument for performance evaluation. The paper "On the Reliability of Coverage-Based Fuzzer Benchmarking [1]" states that we should prepare at least 10 programs.
The PUT used for testing fuzzers should ideally be a large software program, such as a well-known open-source program used in the real world. Using a self-written or small program with only a few dozen or a few hundred lines of code is not recommended5. This is because fuzzers are generally intended to be practical.
It is also important to select the PUT as randomly as possible to reduce selection bias and eliminate arbitrariness. If you want to impose conditions on the PUT, such as being a well-known OSS, it is recommended to first create a set of PUTs that meet the conditions and then randomly select some of them.
After selecting the PUTs, you must adjust the configurations for each PUT, including the initial seeds, dictionary, and other available parameters. It is recommended that you carefully consider these configurations to obtain the most practical results possible. If possible, you can use AFL's preset dictionaries or choose an existing corpus that appears to be suitable initial seeds (e.g., https://github.com/mozilla/pdf.js/tree/master/test/pdfs).
Choosing the experimental environment and duration
Before starting the experiment, you need to set up the experiment environment, determine the duration of the experiment, and decide on the number of machine instances. It is important to consider factors such as the number of PUTs, deadline, available funds, and computing resources. Although it is difficult to determine the ideal values, we will first explain the optimal conditions and then discuss where we can make concessions.
To ensure accurate results, it is recommended that all machines used in the experiments be as identical as possible. For example, you can run all experiments on the same machine or use the same resource instance in a SaaS environment.
Regarding the period of the experiment, as mentioned previously, there is a problem: we do not know whether the fuzzer that is considered the best at a given time will also be the best when more time elapses. In extreme cases, even if you run the fuzzer for a very long time, you cannot eliminate this concern.
However, intuitively, the longer you run the fuzzer, the less likely it is that such a reversal will occur. In reference [1], based on empirical experiments, it is recommended to run the experiment for at least 12 hours, and usually for 24 hours or more.
The number of instances will affect the statistical tests described in the next section, "Statistical Evaluation." Intuitively, one might think that having more instances would lead to a more accurate prediction of the average behavior of the fuzzer. Reference [1] recommends using at least 10 instances, but preferably 20 or more.
Let's now calculate the time required for the experiment. To put it simply, the CPU time required for an experiment can be calculated as follows:
(Required Time [h])
= (# of PUTs) x (# of Instances) x (Time of Experiment [h]) x (# of Fuzzer to Compare with)
If we were to adopt the numbers recommended in [1] for everything, including a single fuzzer, we would need an extremely large amount of resources and time: 10 x 20 x 1[d] = 20[CPU-day]. Therefore, in many cases, we must make some concessions.
First, in the author’s opinion, the duration of the experiment should not be shorter than 24 hours. When possible, it should be extended beyond 24 hours. Some may think that it is nonsensical to set a limit on the time because the number of PUTs executed in the same amount of time depends on the CPU's performance and the number of parallel instances. However, in our experience with DGX, which consists of more powerful CPUs than typical consumer CPUs, the majority of instances continue to increase coverage even after 24 hours. Considering that sometimes increased coverage revealed new tendencies, it is recomended to run for a minimum of 24 hours in any environment.
It may be possible to save time by running multiple instances on a single machine. However, the following points should be noted:
- Ensure that the machine is not overloaded.
- Monitor the frequency of PUT executions per second and keep it at a reasonable level.
- There is no standard for the exact frequency of PUT executions. For instance, you may use CPUs with performance similar to those used in standard benchmarks such as fuzzbench.
- Usually, fuzzers are likely to have no problem running their instances in parallel up to the same number of physical cores6. However, even running only one instance on a single physical core can result in low performance sometimes. In particular, when several hundred instances are set up on a machine with several hundred cores, some operations such as fork become very slow, to the point where the experiment can be pointless. It is inevitable that the more processes you create, the heavier the OS processing becomes, and this is a limitation of the OS. Therefore, the number of instances should be determined with a margin.
- Avoid running different (comparing) fuzzers at the same time.
- This is to ensure that the load of fuzzer A does not have an adverse effect on fuzzer B.
- In some avoidable situations, where measured data is not susceptible to an adverse effect and is not to be published in a paper (data for internal use, etc.), it is acceptable to run them at the same time. However, this should always be clearly stated.
If you have limited computing resources, you may use multiple machines as long as each PUT is performed on a unified machine. For example, PUT X should run on machine A while PUT Y runs on machine B
In cases where you are not planning to submit a paper and reducing the number of PUTs is unavoidable, you may consider using less than 10 PUTs. However, as stated earlier, it is recommended to use at least 6 PUTs whenever possible. If you decide to use fewer PUTs, you must be very careful of confirmation bias.
Statistical Evaluation
This is the most challenging part. Unfortunately, many papers fail to conduct statistically correct evaluations. Since fuzzing campaigns can be considered as random time series data, it is reasonable to compare them using statistical methods to determine whether they are effective or not. Ultimately, what is being discussed here is the general difficulty of doing statistical tests right, not just in the context of fuzzing. A detailed explanation of this point would require a solid mathematical background and would be beyond the scope of this article. Therefore, we will only describe some common mistakes often observed in this field.
- Nonparametric tests must be used.
- Intuitively, the randomness of a fuzzing campaign does not exhibit good properties such as following a normal distribution. Therefore, few assumptions should be made about the distribution. In other words, it is appropriate to use nonparametric methods.
- Most papers follow this rule.
- The significance level α should be strict enough, and the number of samples should be sufficient.
- The significance level α serves as the threshold for the p-value. In simple terms, α is a value that represents the probability of a hypothesis being false when the test result indicates true (or vice versa by reversing the result to 1-α).
- The setting of α is free, so there are various de facto standards depending on the field. In the fuzzing community, p < 0.05 is common. In the author’s opinion, p < 0.01 should be used, but this is a personal belief and not a problem. However, it is not allowed to decide α after looking at the results of statistical tests. In recent years, there seems to be a trend, among some people that probably feel setting α meaningless, of simply displaying the p-value without setting α
- Nonparametric tests require fewer assumptions than parametric tests and typically require more information (= sample size). On the other hand, fuzzing campaigns are very heavy on each trial and it is difficult to increase the number of instances, making it difficult to obtain significant results. (That's why fraud such as changing p-values later occurs.) For example, there may be a huge difference in the test between 10 and 20 instances.
- Multiple testing problem should be properly solved.
- Unfortunately, there are not many papers that handle this issue correctly7. It is difficult to handle the problem properly including the sample size. As a result, the results appear to be ambiguous in many papers.
The test commonly used in fuzzing research papers is the Mann-Whitney U test. However, this test can only determine whether two groups follow different distributions or whether the rank sum of one group is significantly better than that of another group. It generally cannot determine whether the mean or median of one group is significantly higher than that of another group.
Furthermore, within the fuzzing community, the Brunner-Munzel test is more suitable and has a higher detection ability than the Mann-Whitney U test. However, there seems to be no discussion about this, and the Mann-Whitney U test is becoming the de facto standard, as papers recommending it are being cited.
Thus, there are many aspects to consider when comparing fuzzers for each PUT (range where statistical methods can be applied). Drawing conclusions across PUTs is even more challenging.
Drawing a conclusion like "fuzzer A has these characteristics" is difficult because even if the same fuzzer is used, each PUT shows completely different tendencies and results. Additionally, the impact of PUT on the fuzzer's performance cannot be modeled by formulas or any other means. Furthermore, since only a few dozen PUTs are used in experiments, each with different characteristics, statistical methods cannot be applied.
Therefore, experimenters must reach their own conclusions through methods that satisfy them. An example is “Rank 8 fuzzers. Count the number of times they were in the top 3 when ranking 8 fuzzer's code coverage in each of 10 PUTs in descending order. The fuzzer with the highest value could then be considered the best.”.
This way, there is no complete consensus in the fuzzing community on statistical evaluation methods for experimental results. Depending on what one wants to determine from the experimental results, it is necessary to carefully consider what statistical methods to use.
This article explains some of the pitfalls that may occur when evaluating the performance of a fuzzer, as well as some notes on how to construct an experimental setup. When evaluating the performance of fuzzers, it is important to understand the characteristics of each fuzzer and set up an appropriate experiment according to the problem you want to investigate.
We will investigate the performances of different fuzzers and continue research and development to incorporate them in fuzzuf.
In the next article, we will cover the concept of patch analysis, which is important in the development of 1-day exploits, using Google Chrome's 1-day as an example.
[1] Marcel Böhme, Laszlo Szekeres, Jonathan Metzman. On the Reliability of Coverage-Based Fuzzer Benchmarking. 44th International Conference on Software Engineering (ICSE 2022) https://mboehme.github.io/paper/ICSE22.pdf
[2] Marcel Böhme, Danushka Liyanage, Valentin Wüstholz. Estimating residual risk in greybox fuzzing. Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2021) https://mboehme.github.io/paper/FSE21.pdf
1: Of course, with both graphs, you can also explain that the optimization has no negative effect on the execution speed.
2: Code coverage may vary depending on the instrumentation methods used (e.g., with dominator tree optimization), but we will simplify by ignoring these cases.
3: Although the seed for the pseudorandom generator can be fixed, the behavior and performance of fuzzers can still vary depending on the chosen seed values.
4: Adding codes to the program to feed back information from the PUT to the fuzzer, such as coverage measurements.
5: Unless there is a special reason such as working with small programs for pilot implementation.
6: Note that some fuzzer implementations bind to a CPU core.
7: Comparing Fuzzers on a Level Playing Field with FuzzBench is a good example of a paper that appropriately handles testing.
如有侵权请联系:admin#unsafe.sh