2023-7-19 16:12:0 Author: ricercasecurity.blogspot.com(查看原文) 阅读量:11 收藏
著者:Dronex, ptr-yudai
はじめに
この記事は、Fuzzing Farmシリーズ全4章のパート4で、パート3の記事「Fuzzing Farm #3: パッチ解析とPoC開発」の続きです。
Fuzzing Farmチームでは、前回の記事で紹介したように、1-dayエクスプロイトだけでなく0-dayエクスプロイトの開発にも取り組んでいます。Fuzzing Farmシリーズ最終章では、弊社エンジニアが発見した0-dayと、そのエクスプロイト開発について解説します。
我々は1年以上前の2022年4月の段階で、CVE-2022-24834に該当するRedisの脆弱性を発見し、RCE(Remote Code Execution; 任意コマンド実行)エクスプロイトの開発を完了していました。ベンダ側も修正を急いでくれましたが、利用者側の対応に時間を要したため、前回パート3の記事から今回の投稿まで期間が空いてしまいました。しかし、先日修正が完了してベンダからの情報公開が決まったため、我々もこの記事を投稿することにしました。
CVE-2022-24834
CVE-2022-24834はRedisのLuaインタプリタに含まれていた脆弱性で、弊社メンバーのDronexとptr-yudaiが発見・報告しました。Redisはオープンソースアプリケーションで、データベースやキャッシュなどとして世界中で利用されているデータストアです。
この脆弱性は2022年4月に報告し、2023年7月10日に修正パッチが入りました。
脆弱性発見までの経緯
今回Fuzzing Farmチームでは、オープンソースソフトウェアの中から、ユーザ数・ソフトウェアの規模・影響の大きさなどを考慮して複数のターゲット候補を選び、最終的にRedisを対象としました。
Redisの中にも様々な機能があるため、脆弱性を探す上ではある程度対象を絞って調査した方が効率が良いです。Redisはデータストアですが、Luaインタプリタを備えており、複雑な処理を実現できるように設計されています。この機能には、過去にもCVE-2015-8080やCVE-2018-11218のような脆弱性が報告されています。そこで、今回はRedisのLua機能を重点的に調査しました。
Lua以外にも複数の箇所で脆弱性や問題が見つかりましたが、CVE-2022-24834はエクスプロイト可能であり、また技術的に面白いと感じたため、今回のブログ記事で紹介することにしました。
脆弱性の原因
CVE-2022-24834の原因は、Luaインタプリタの中でもJSONに関する機能にあり、コード中では json_append_string が該当します。
/* json_append_string args:
* - lua_State
* - JSON strbuf
* - String (Lua stack index)
*
* Returns nothing. Doesn't remove string from Lua stack */
static void json_append_string(lua_State *l, strbuf_t *json, int lindex)
{
const char *escstr;
int i;
const char *str;
size_t len;
str = lua_tolstring(l, lindex, &len);
/* Worst case is len * 6 (all unicode escapes).
* This buffer is reused constantly for small strings
* If there are any excess pages, they won't be hit anyway.
* This gains ~5% speedup. */
strbuf_ensure_empty_length(json, len * 6 + 2); // [1]
strbuf_append_char_unsafe(json, '\\"');
for (i = 0; i < len; i++) {
escstr = char2escape[(unsigned char)str[i]];
if (escstr)
strbuf_append_string(json, escstr);
else
strbuf_append_char_unsafe(json, str[i]);
}
strbuf_append_char_unsafe(json, '\\"');
}
この関数はLuaの文字列オブジェクトをJSON文字列リテラルにエンコードする関数です。例えば、Hello, 世界 という文字列は "Hello, \\u4e16\\u754c" にエンコードされます。
コメント[1]で示した箇所では、エンコード後の文字列バッファを確保しています。先程の例からも分かるように、1文字はUnicodeエスケープで6バイトになる可能性があるので len * 6 をしており、さらにダブルクォートの2文字分を長さに足しています。
バッファサイズの計算で算術演算が入るときは、常に整数オーバーフローを気にしましょう。今回の場合、変数 len は size_t 型で定義されているため64-bit整数となります。もしここで整数オーバーフローさせたければ (2^64 - 2) / 6 バイトの文字列をエンコードする必要がありますが、これは現実的なサイズではありません。ここに脆弱性はないのでしょうか?
strbuf_ensure_empty_length の定義を見てみましょう。
static inline void strbuf_ensure_empty_length(strbuf_t *s, int len)
{
if (len > strbuf_empty_length(s)) // [2]
strbuf_resize(s, s->length + len);
}
なんと、長さの引数が int 型になっています!
したがって、 len * 6 + 1 を int 型へキャストする再、整数オーバーフローが発生する可能性があります。ある程度大きい値が len に入ると、例えば次のようになります。
0x200000000 * 6 + 2=0xc0000002→-10737418220x300000000 * 6 + 2=0x120000002→536870914(上位ビット切り捨て)
整数オーバーフローが発生した場合、本来の要求サイズでバッファが確保されません。特に、整数オーバーフローの結果が負の値になった場合、コメント[2]が必ずfalseになるため、バッファのリサイズが発生しません。さらに、strbuf_append_char_unsafe は名前の通り、バッファサイズのチェックを行わずにバッファに文字を追加します。したがって、ヒープバッファオーバーフローが発生します。
バッファオーバーフローを起こすためには、エンコード前の文字列の長さが (0x80000000 - 2) / 6 = 0x15555555 バイト必要です。これは341MiB程度なので、64-bitシステムでは現実的に可能な長さです。
エクスプロイト開発
エクスプロイトにおける課題
ヒープバッファオーバーフローができるとはいえ、今回の状況では以下のような厳しい制約があります。
【問題1】最低でも変換文字列+2バイト書き込む必要がある。
リサイズ前のバッファに対して0x15555557バイト書き込むため、ヒープ領域を大きく破壊します。したがって、動作に必要なデータを破壊しないように注意する必要があります。また、そもそもオーバーフローのサイズが通常のヒープ領域のサイズを大幅に超えているため、書き込みがマップされていない領域に到達してクラッシュします。
【問題2】ASLRとPIEが有効である。
近年のアプリケーションがほとんどそうであるように、RedisもPIEが有効です。当然システムのASLRも有効であるため、何かしらの手段でアドレスをリークする必要があります。
【問題3】データがUnicodeエスケープされる。
JSON文字列リテラルとしてエンコードしたデータがオーバーフローするため、NULL文字を含む多くの文字がUnicodeエスケープされます。したがって、単純に任意のバイト列をオーバーフローで書き込むことはできません。
【問題4】ダブルクォートが付加される。
書き込まれるバイト列の末尾は必ず " (文字列リテラルの閉じ引用符)になります。
まずは問題1のクラッシュを解決しなければエクスプロイトは始まりません。クラッシュの問題については、事前に巨大なデータを確保してヒープを拡張しておくことで解決します。LuaはGC(Garbage Collector)を利用しているため、ある程度大きい文字列データを確保して削除すれば、GCが発火するタイミングで解放されます。データが解放されてもメモリはマップされたままなので、ヒープバッファオーバーフローで大量のデータを書き込んでもクラッシュしません。
また、ヒープバッファオーバーフローによってRedisが動作するのに必要なデータが破壊されてはいけません。これは事前にヒープを適切に操作しておくことで実現可能です。
次に、問題2について実は簡単に解決できますが、これについては後述します。
最後にエクスプロイト可能性に関わるもっとも重要な問題が、問題3と4です。ヒープオーバーフローができても、書き込めるデータに強い制約があるため、安定したエクスプロイトを書けるかが課題になります。
Luaの構造
エクスプロイトの方針を考える前に、Luaがメモリ上でどのようにデータを管理しているかについて調べておきましょう。
まず、Luaはメモリ管理にマーク&スイープ方式のGCを使っています。GCを強制的に発動させるビルトイン関数 collectgarbage が用意されているので、GCについてはそこまで気にする必要はありません。
また、Luaのオブジェクトは、タグ付きの構造体 TValue で管理されます。
typedef union {
GCObject *gc;
void *p;
lua_Number n;
int b;
} Value;
#define TValuefields Value value; int tt
typedef struct lua_TValue {
TValuefields;
} TValue;
tt が型を表し、次のいずれかの値を取ります。
#define LUA_TNONE (-1)
#define LUA_TNIL 0
#define LUA_TBOOLEAN 1
#define LUA_TLIGHTUSERDATA 2
#define LUA_TNUMBER 3
#define LUA_TSTRING 4
#define LUA_TTABLE 5
#define LUA_TFUNCTION 6
#define LUA_TUSERDATA 7
#define LUA_TTHREAD 8
いくつかの重要な型について簡単に説明します。
LUA_TNUMBER- Luaのnumber型を持ちます。内部的には単純な
double型です。
- Luaのnumber型を持ちます。内部的には単純な
LUA_TSTRING- Luaの文字列型を持ちます。メモリ上ではヘッダの直後に文字列本体が配置されます。Luaの文字列はイミュータブルで、内容の書き換えはできません。
- 確保した文字列に対してはハッシュ値が計算され、Lua側で管理されています。これにより、同一の文字列が複数回メモリに確保されることを防いでいます。
typedef union TString {
L_Umaxalign dummy; /* ensures maximum alignment for strings */
struct {
CommonHeader;
lu_byte reserved;
unsigned int hash;
size_t len;
} tsv;
} TString;
LUA_TTABLE- Luaのテーブル型を持ちます。テーブル型は配列も連想配列も持つことができるオブジェクトです。
- 配列として使用される場合、
TValue配列へのポインタarrayと、そのサイズsizearrayが利用されます。
typedef struct Table {
CommonHeader;
lu_byte flags; /* 1<<p means tagmethod(p) is not present */
int readonly;
lu_byte lsizenode; /* log2 of size of `node' array */
struct Table *metatable;
TValue *array; /* array part */
Node *node;
Node *lastfree; /* any free position is before this position */
GCObject *gclist;
int sizearray; /* size of `array' array */
} Table;
LUA_TFUNCTION- Luaのクロージャ型を持ちます。Lua上で定義された関数へのクロージャ
LClosureか、ビルトイン関数のようにC言語で定義された関数へのクロージャCClosureが利用されます。
- Luaのクロージャ型を持ちます。Lua上で定義された関数へのクロージャ
typedef struct CClosure {
ClosureHeader;
lua_CFunction f;
TValue upvalue[1];
} CClosure;
typedef struct LClosure {
ClosureHeader;
struct Proto *p;
UpVal *upvals[1];
} LClosure;
typedef union Closure {
CClosure c;
LClosure l;
} Closure;
Addrof primitiveの作成
ASLRやPIEが有効な以上、問題2を解決する必要がありますが、実はこの問題は簡単に解決できます。
Luaのテーブルやビルトイン関数を tostring で文字列化すると、Luaの仕様によってそれぞれ確保されたオブジェクトのヒープ上のアドレスが文字列として返ります。つまり、オブジェクトのアドレスを取得するaddrof primitiveは、脆弱性に関係なく持っています。

ヒープのアドレスが得られるため、ASLRの問題は解決できました。
Fakeobjの作成
ヒープバッファオーバーフローで書き込める文字種に制限があるため、有効なアドレス値全体を書き込むことは不可能です。このような場合、主に以下の2通りのエクスプロイト手法が考えられます。
-
配列サイズのようなメタデータを書き換える。
オーバーフローで書き込めるデータに制限があっても、サイズ情報のようなメタデータを書き換えて、それを起点に別の方法で攻撃できれば良いです。今回の条件ではどうでしょうか。
まず、文字列型についてはイミュータブルなので、サイズ情報を書き換えても値の書き込みはできません。また、テーブル型の配列については、サイズ情報がポインタよりも後ろにあるため、ポインタを破壊せずにサイズ情報のみを書き換えることができません。
したがって、今回の条件ではメタデータを書き換える方針は難しそうです。
-
ポインタの下位バイトのみを部分的に書き換える。
部分的にポインタを書き換えることで、偽のアドレスにポインタを向けることができます。例えばテーブル型の配列ポインタの下位1バイトを書き換えて偽の配列に向ければ、エクスプロイトに繋がりそうです。今回はこちらの方針でエクスプロイトを開発します。
問題4でも述べたように、オーバーフローするデータの末尾は必ず " (0x22)になります。配列へのポインタの最下位バイトをこれで書き換えることで、誤ったメモリアドレスを配列へのポインタとして認識させられます。
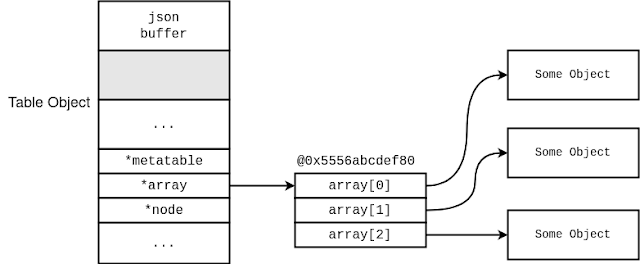
エクスプロイトが複雑なので図で確認してみましょう。まず、正常なテーブル(配列)は図1のような構造になっています。テーブルオブジェクトがあり、その array が TValue の配列実体を指しています。 TValue がテーブルや文字列などポインタを持つ型であった場合、さらにそのオブジェクト実体へのポインタがあります。
 |
| 図1. 正常なテーブルオブジェクト |
我々はヒープオーバーフローでポインタ array の最下位1バイトを " (0x22)に書き換えます。正規の配列実体より少し低いアドレスに文字列を使って偽の配列を用意しておきます。すると、図2のように、ポインタ array が偽の配列を指し、任意の偽オブジェクトを取得できます。幸いなことに、ポインタ metatable は適当な値でも、Luaのメタテーブルを使わなければクラッシュしません。
 |
| 図2. 配列ポインタの下位1バイトを書き換えたテーブル |
問題として、最後の1バイト(0x22)がちょうど配列へのポインタ array の最下位バイトを書き換える位置に、テーブルオブジェクトを確保する必要があります。この問題は、free済みのチャンクを消費するヒープスプレーによって安定化できます。なお、偽の配列や偽のオブジェクトについては、addrof primitiveを持っているため、正確なアドレスが分かります。
これにより、問題3と問題4を回避しつつfakeobjが作成できます。ただし、このfakeobjは1回しか使えないため、まだprimitiveとしては使えません。
AAR/AAW primitiveの作成
より強力なprimitiveとして、任意アドレス読み書き、AAR(Arbitrary Address Read)とAAW(Arbitrary Address Write)を作っていきましょう。
偽のオブジェクトが作成できたため、偽のテーブル構造体が作成できます。この偽配列のベースアドレスをなるべく低いアドレスにし、サイズを可能な限り大きくとります。すると、この偽配列はヒープの広い領域を参照できるテーブルになります。
 |
| 図3. 偽テーブルオブジェクトの作成 |
配列の型をnumber型にしておけば、指定アドレスにある程度自由な値を書き込めます。ただし、 TValue の性質上、単純な読み書きではありません。 TValue そのものは、値の実体(あるいはポインタ)と型情報を持った16バイトの構造体です。number型の場合、次の制約があります。
- 書き込み:valueにdouble型の値が書き込まれる。また、型情報が
LUA_TNUMBERで上書きされる。 - 読み込み:valueからdouble型の値を読み込む。ただし、型情報が
LUA_TNUMBERになっていないとassertionエラーが起きる。
書き込みに関しては、書き込み先のアドレスより8バイト後ろに LUA_TNUMBER が同時に書き込まれる点に注意しましょう。図4のようになります。
 |
| 図4. 任意アドレスへの書き込み |
読み込みに関しては、型情報が正しい必要があるため、読み込みたいアドレスより8バイト後ろに、事前に LUA_TNUMBER を書き込んでおく必要があります。(したがって、この方法で読み込み専用メモリを読むことはできません。)図5のようになります。
 |
| 図5. 任意アドレスからの読み込み |
また、 TValue は0x10バイトなので、偽テーブルの array が指すベースアドレスからは、0x10の倍数ごとのアドレスにしか書き込めません。そこで、図6に示すように、ベースアドレス-8を指すもう1つの偽テーブルを作ります。右側に示したテーブルのアドレスとサイズは、 arrayと sizearray のオフセットが幸いにも0x10の倍数のため、偽テーブルからの相対書き込みで書き換えられます。
 |
| 図6. AAR/AAW primitive |
これにより、ヒープ上のデータを( LUA_TNUMBER が書き込まれるという制約はありますが )自由に読み書きできる、相対的なAAR/AAW primitiveが作れました。
Addrof/Fakeobj primitiveの作成
現状持っているaddrof primitiveは tostring を利用したものなので、テーブルや関数などの一部のオブジェクトにしか使えません。また、fakeobjも最初の1度しか利用できませんでした。
しかし、現在はAAR/AAW primitiveを持っているため、addrof/fakeobj primitiveが作れそうです。今ヒープを完全に制御できるので、ヒープバッファオーバーフローでfakeobjを作ったときよりも簡単にfakeobjが作れます。図7のように、適当な配列の array が指す先のアドレスと型情報を書き換えれば、任意の型のオブジェクトが生成できます。
 |
| 図7. fakeobj primitiveの作成 |
同様に図8のように、配列にリークしたいオブジェクトを格納して、型情報を LUA_TNUMBER に書き換えておきます。すると、次に配列を読んだときにnumber型と認識するため、オブジェクトのアドレスが得られます。
 |
| 図8. addrof primitiveの作成 |
最後の仕上げ:RCE
ここまで来れば、RIPの制御は簡単です。 CClosure 型の関数はC言語で書かれた関数を呼び出します。つまり、関数ポインタを持っています。したがって、fakeobjで偽のビルトイン関数を作って呼び出せば、任意のアドレスをcallできます。
問題は引数が制御できないことです。Redisは execve 関数を使うため、PLT(Procedure Linkage Table)から execve を呼び出せます。しかし、任意コマンド実行するためには execve の3引数を適切に渡す必要があります。このようなときは、Call Oriented Programmingで引数を制御しましょう。
Call chainを組むときに最初に調べるのは、呼ばれている関数ポインタがどこから来たかです。関数を呼び出す luaD_precall を読むと、次のように rax+0x20 に置かれた関数ポインタが呼ばれていることが分かります。

つまり、RAXは現在制御可能な偽関数オブジェクトを指していることになります。したがって、 call qword ptr [rax+XXX] のような命令で終わるgadgetでcall chainを構築しましょう。(関数ポインタそのものはオフセット0x20に位置するので、それ以外の場所を使ってchainを作ります。)
Call chain中では、以下の3つの操作をすれば良いです。
- RDX (envp)を0にする。
- RSI (argv)に
argvを入れる。 - RDI (pathname)に
argv[0]を入れる。
まずRDXを0にするgadgetですが、次のgadgetが便利そうです。
0x000abb6a:
xor edx, edx;
xor esi, esi;
mov rdi, rbp;
call qword ptr [rax+0x38];
次にRDIとRSIには具体的なアドレスを入れる必要があります。RAXの指すアドレスにあるデータが制御可能なので、この周辺からmovするgadgetを探します。例えば以下のgadgetが見つかります。
0x001554c8:
mov rdi, [rax];
call qword ptr [rax+0x18];
RSIに値を入れるgadgetも以下のものが見つかります。しかし、先程のgadgetにおけるRDIのソースと同じであり、またRDXを破壊する上、callのソースが最初のgadgetと被ってしまっています。
0x000d1f3e:
mov rsi, [rax]; // conflict!
mov rdx, rbp; // overwrite!
call qword ptr [rax+0x38]; // conflict!
そこで、今回は次のgadgetを使いました。
0x0012718b:
mov rsi, [rdi+8];
mov rdi, [rdi];
call qword ptr [rax+0x10];
このgadgetはRDI, RSI両方の値を設定できます。値のソースはRDIですが、これは2番目のgadgetで設定できるため問題ありません。複雑ですが、図9のような構成になります。
 |
| 図9. Call Chainの構築 |
エクスプロイト
最終的なエクスプロイトコードは以下のリポジトリを参照してください。修正が入る直前のコミットで動作検証をしました。
CVE-2022-24823 - RICSecLab/exploit-poc-public
実際にエクスプロイトを動かすと、次のようにRCEできていることが確認できます。
如有侵权请联系:admin#unsafe.sh