[TOC]
python并发编程分三个方面:多线程(threading)、多进程(multiprocessing)、多协程(asynico)
CPU密集型计算:压缩/解压缩、加密解密、正则表达式搜索
IO密集型计算:文件处理、网络爬虫、读写数据库
对比
进程:
- 优点:可以实现并行,且只有多进程可以实现并行
- 缺点:占用资源多,可启动数目最少
线程:
- 占用资源少,轻量级
- python的线程是无法并行的(占用多个cpu),只能进行并发
- 切换线程也是有开销的。
- 适合IO密集型运算、同时运行任务不多(线程可启动数量也是有限制的)
协程:
优点:内存开销最小,可启动数量最多
缺点:支持的库比较少,代码复杂,例如爬虫不支持,所以想用多协程爬取的话,可以用aiohttp,不能用requests
适用于:IO密集型、超多任务运行
关系
- 一个进程中可以启动很多线程
- 一个线程中可以启动很多协程
怎样选择
- IO密集型运算优先选择多进程
- 若满足三点:1、需要超多任务量 2、有现成协程库支持 3、代码复杂度可以接受,则选择协程,否则选择线程
python慢的原因
两个原因
- 是解释型语言,边解释边执行
- GIL,无法利用多核CPU
GIL是什么,为什么有GIL
全局解释器锁,是计算机程序设计语言解释器用于==同步==线程的一种机制,它使得任何时刻只有一个线程在运行
python设计初期为了解决线程并发的问题引入了GIL,但是现在很难去除,本质是一种锁,它的好处在于简化了Python对共享资源的管理
怎样规避GIL带来的限制
- IO期间线程会释放GIL,实现CPU和IO的并行,因此GIL的存在对于IO密集型计算是友好的,但是对CPU密集型则会拖慢速度
- 利用multiprocessing,可以利用多核CPU的优势

threading库
https://jusene.github.io/2018/02/13/thread/
- threading.active_count():返回当前存活的threading.Thread线程对象数量,等同于len(threading.enumerate())。
- threading.current_thread():返回此函数的调用者控制的threading.Thread线程对象。如果当前调用者控制的线程不是通过threading.Thread创建的,则返回一个功能受限的虚拟线程对象。
- threading.get_ident():返回当前线程的线程标识符。注意当一个线程退出时,它的线程标识符可能会被之后新创建的线程复用。
- threading.enumerate():返回当前存活的threading.Thread线程对象列表。
- threading.main_thread():返回主线程对象,通常情况下,就是程序启动时Python解释器创建的threading._MainThread线程对象。
- threading.stack_size([size]):返回创建线程时使用的堆栈大小。也可以使用可选参数size指定之后创建线程时的堆栈大小,size可以是0或者一个不小于32KiB的正整数。如果参数没有指定,则默认为0。如果系统或者其他原因不支持改变堆栈大小,则会报RuntimeError错误;如果指定的堆栈大小不合法,则会报ValueError,但并不会修改这个堆栈的大小。32KiB是保证能解释器运行的最小堆栈大小,当然这个值会因为系统或者其他原因有限制,比如它要求的值是大于32KiB的某个值,只需根据要求修改即可。
线程对象:Thread类
守护线程:只有所有守护线程都结束,整个Python程序才会退出,但并不是说Python程序会等待守护线程运行完毕,相反,当程序退出时,如果还有守护线程在运行,程序会去强制终结所有守护线程,当守所有护线程都终结后,程序才会真正退出。可以通过修改daemon属性或者初始化线程时指定daemon参数来指定某个线程为守护线程。
非守护线程:一般创建的线程默认就是非守护线程,包括主线程也是,即在Python程序退出时,如果还有非守护线程在运行,程序会等待直到所有非守护线程都结束后才会退出。
注:守护线程会在程序关闭时突然关闭(如果守护线程在程序关闭时还在运行),它们占用的资源可能没有被正确释放,比如正在修改文档内容等,需要谨慎使用。
构造方法:
Thread(group=None,target=None,name=None,arg=(),kwargs=None,*,daemon=None)
group: 线程组,目前还没有实现,库引用中必须是None
target: 要执行的方法
name: 线程名
args/kwargs: 要传入方法的参数
daemon:
默认为false(不适用于IDLE的交互模式或脚本运行模式,因为交互模式下的主线程只有退出PYTHON时才终止)
- 当子线程的daemon属性为false时,主线程结束时会检测子线程是否结束,如果子线程尚未完成,则主线程会等待子线程完成后再退出
- 当子线程的daemon属性为true时,主线程运行结束时不对子线程进行检查而直接退出,同时子线程随主线程一起结束而不论是否运行完成
实例方法:
isAlive(): 返回线程是否在运行,正在运行指启动后、终止前
getName(): 获取线程名
isDaemon(): 获取是否为后台线程
join(timeout=None): ==阻塞当前上下文环境的线程,直到调用此方法的线程终止或到达指定的timeout,说人话就是会把程序卡在这里,直到这个用了join的线程执行结束才可以执行其他线程,像join(5)就是等待这个线程运行5秒,不加参数就是一直等他运行结束。==
这里也可以看出join也有一定的==同步==的作用
setDaemon(): 设置为后台线程
setName(name): 设置线程名
start(): 启动线程
锁对象:Lock & 递归锁对象:Rlock类
由于线程的随机调度:某线程可能在执行n条后,cpu接着执行其他线程。为了多个线程同时操作一个内存中的资源时不产生混乱,我们使用锁。
实例方法:
- acquire([timeout]): 尝试获得锁定,使线程进入同步阻塞状态。
- release(): 释放锁,使用前线程必须已获得锁定,否则抛出异常。
Lock属于全局,重复锁定会产生死锁;RLock属于线程,可重复施加锁,需要执行相同次数的锁释放。
import threading,time gl_num=0 lock=threading.RLock() def action(): lock.acquire() global gl_num gl_num+=1 time.sleep(1) print('gl_num') lock.release() for i in range(10): t=threading.Thread(target=action) t.start()
条件变量对象:Condition类
Condition通常与一个锁关联,需要在多个Contidion中共享一个锁时,可以传递一个Lock/RLock实例给构造方法,否则它将自动生产一个RLock实例。
可以认为,除了Lock带有的锁定池外,Condition还包含一个等待池,池中的线程处于等待阻塞状态,直到另一个线程调用notify()/notifyAll()通知;得到通知后线程进入锁定池等待锁定。
实例方法:
- acquire([timeout])/release():调用关联的锁的相应方法
- wait([timeout]):调用这个方法将使线程进入Condition的等待池等待通知,并释放锁。使用前线程必须已获得锁定,否则将抛出异常
- notify():调用这个方法将从等待池挑选一个线程并通知,收到通知的线程将自动调用acquire()尝试获得锁定,其他线程仍然在等待池中
-notifyAll():调用这个方法将通知等待池中所有的线程,这些线程都将进入锁定池尝试获得锁定
事件对象:Event类
Event是最简单的线程通信机制之一:一个线程通知事件,其他线程等待事件。Event内置了一个为False的标志,当调用set()时设为True,调用clear()时重置为False。wait()将阻塞线程至等待阻塞状态。
实例方法:
- isSet(): 当内置标志为True时返回True
- set(): 将标志设为True,并通知所有处于等待阻塞状态的线程恢复运行状态
- clear(): 将标志设为False
- wait([timeout]): 如果标志True将立即返回,否则阻塞线程至等待阻塞状态,等待其他线程调用set()
定时器对象:timer类
Timer(定时器)是Thread的派生类,用于在指定时间后调用一个方法。
构造方法:
Timer(interval,function,args=[],kwarg={})
- interval:指定的时间
- function:要执行的方法
- args/kwargs:方法的参数
local类
local是一个小写字母开头的类,用于管理thread-local(线程局部)数据。对于同一个local,线程无法访问其他线程设置的属性;线程设置的属性不会被其他线程设置的同名属性替换。
创建多线程
1、准备一个函数
def my_func(a,b): do_craw(a,b)
2、创建线程
import threading t=threading.Thread(target=myfunc,args=(100,200,))
3、启动线程
4、等待结束
多线程爬虫
基础
main.py
import requests urls = [ f"https://test.com/#p{page}"for page in range(1, 51) ] print(urls) def craw(url): r = requests.get(url) print(len(r.text)) craw(urls[0])
test.py
import main import threading def single_thread(): for url in main.urls: main.craw(url) def multi_thread(): threads = [] for url in main.urls: threads.append( threading.Thread(target=main.craw, args=(url,)) ) for thread in threads: thread.start() for thread in threads: thread.join() '''for thread in threads: thread.join() 的作用是等待每个线程执行结束。在多线程程序中,线程是并行执行的,如果不等待线程执行完成,程序可能会在某个线程还没有完成运行的情况下就结束了。''' single_thread() multi_thread()
生产者-消费者-队列
https://www.kancloud.cn/xmsumi/pythonspider/160105
进程间通信:队列(queue) 管道(pipe)
Queue模块实现了多生产者多消费者队列, 尤其适合多线程编程.列表也可以用作队列,但是它第一个元素移出以后后面的数据都需要向前移动,导致效率很低
Queue类中实现了所有需要的锁原语(这句话非常重要), Queue模块实现了三种类型队列:
- FIFO(先进先出)队列, 第一加入队列的任务, 被第一个取出
- LIFO(后进先出)队列,最后加入队列的任务, 被第一个取出(操作类似与栈, 总是从栈顶取出, 这个队列还不清楚内部的实现)
- PriorityQueue(优先级)队列, 保持队列数据有序, 最小值被先取出(在C++中我记得优先级队列是可以自己重写排序规则的, Python不知道可以吗)
==三个模块==
import Queue #类 Queue.Queue(maxsize = 0) #构造一个FIFO队列,maxsize设置队列大小的上界, 如果插入数据时, 达到上界会发生阻塞, 直到队列可以放入数据. 当maxsize小于或者等于0, 表示不限制队列的大小(默认) Queue.LifoQueue(maxsize = 0) #构造一LIFO队列,maxsize设置队列大小的上界, 如果插入数据时, 达到上界会发生阻塞, 直到队列可以放入数据. 当maxsize小于或者等于0, 表示不限制队列的大小(默认) Queue.PriorityQueue(maxsize = 0) #构造一个优先级队列,,maxsize设置队列大小的上界, 如果插入数据时, 达到上界会发生阻塞, 直到队列可以放入数据. 当maxsize小于或者等于0, 表示不限制队列的大小(默认). 优先级队列中, 最小值被最先取出 #异常 Queue.Empty #当调用非阻塞的get()获取空队列的元素时, 引发异常 Queue.Full #当调用非阻塞的put()向满队列中添加元素时, 引发异常
Queue
import queue q=queue.Queue()#创建Queue Queue.empty() #如果队列为空, 返回True(注意队列为空时, 并不能保证调用put()不会阻塞); 队列不空返回False(不空时, 不能保证调用get()不会阻塞) Queue.full() #如果队列为满, 返回True(不能保证调用get()不会阻塞), 如果队列不满, 返回False(并不能保证调用put()不会阻塞) Queue.put(item[, block[, timeout]]) #向队列中放入元素, 如果可选参数block为True并且timeout参数为None(默认), 为阻塞型put(). 如果timeout是正数, 会阻塞timeout时间并引发Queue.Full异常. 如果block为False为非阻塞put Queue.put_nowait(item) #等价于put(itme, False) Queue.get([block[, timeout]]) #移除列队元素并将元素返回, block = True为阻塞函数, block = False为非阻塞函数. 可能返回Queue.Empty异常 Queue.get_nowait() #等价于get(False) Queue.task_done() #在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号 Queue.join() #实际上意味着等到队列为空,再执行别的操作
线程安全 lock
线程安全是指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成
由于线程的执行会随时发生切换,造成不可预料的结果,出现线程不安全
用法1:try-finally模式
import threading lock = threading.Lock() lock.acquire() try: do something finally: lock.release()
用法2:with模式
import threading lock = threading.Lock() with lock: do something
线程不安全的代码:
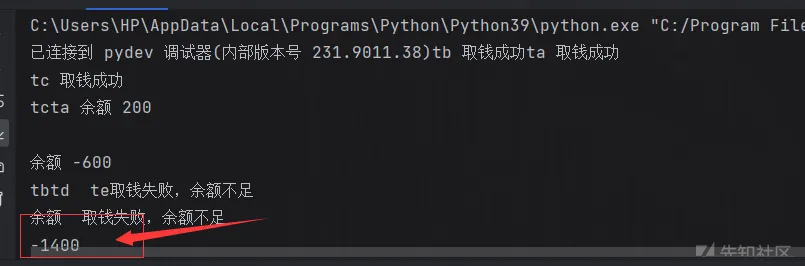
多线程并发的时候可能出现余额扣到负数的情况
import threading class Account: def __init__(self, balance): self.balance = balance def draw(acc, amount): if acc.balance >= amount: print(threading.current_thread().name, "取钱成功") acc.balance -= amount print(threading.current_thread().name, "余额", acc.balance) else: print(threading.current_thread().name, "取钱失败,余额不足") if __name__ == "__main__": account = Account(1000) ta = threading.Thread(name="ta", target=draw, args=(account, 800)) tb = threading.Thread(name="tb", target=draw, args=(account, 800)) tc = threading.Thread(name="tc", target=draw, args=(account, 800)) td = threading.Thread(name="td", target=draw, args=(account, 800)) te = threading.Thread(name="te", target=draw, args=(account, 800)) ta.start() tb.start() tc.start() td.start() te.start()

而在draw函数加一个sleep,则100%触发,因为sleep会阻塞线程且发生线程切换
def draw(acc, amount): if acc.balance >= amount: time.sleep(0.1) print(threading.current_thread().name, "取钱成功") acc.balance -= amount print(threading.current_thread().name, "余额", acc.balance) else: print(threading.current_thread().name, "取钱失败,余额不足")
引进lock就安全了:
import threading import time lock = threading.Lock() class Account: def __init__(self, balance): self.balance = balance def draw(acc, amount): with lock: if acc.balance >= amount: time.sleep(0.1) print(threading.current_thread().name, "取钱成功") acc.balance -= amount print(threading.current_thread().name, "余额", acc.balance) else: print(threading.current_thread().name, "取钱失败,余额不足") if __name__ == "__main__": account = Account(1000) ta = threading.Thread(name="ta", target=draw, args=(account, 800)) tb = threading.Thread(name="tb", target=draw, args=(account, 800)) tc = threading.Thread(name="tc", target=draw, args=(account, 800)) td = threading.Thread(name="td", target=draw, args=(account, 800)) te = threading.Thread(name="te", target=draw, args=(account, 800)) ta.start() tb.start() tc.start() td.start() te.start()
线程池 threadpoolexecutor
线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor,其中 ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池。
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
如果使用线程池/进程池来管理并发编程,那么只要将相应的 task 函数提交给线程池/进程池,剩下的事情就由线程池/进程池来搞定。
用法
==Exectuor 提供了如下常用方法==:
- submit(fn, args, **kwargs):将 fn 函数提交给线程池。args 代表传给 fn 函数的参数,*kwargs 代表以关键字参数的形式为 fn 函数传入参数。
- map(func, iterables, timeout=None, chunksize=1):该函数类似于全局函数 map(func, iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。
- shutdown(wait=True):关闭线程池。
==Future 提供了如下方法==:(也就是submit打头,ThreadPoolExecutor.submit()方法将返回一个future对象)
cancel():取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。
cancelled():返回 Future 代表的线程任务是否被成功取消。
running():如果该 Future 代表的线程任务正在执行、不可被取消,该方法返回 True。
done():如果该 Funture 代表的线程任务被成功取消或执行完成,则该方法返回 True。
==result==(timeout=None):获取该 Future 代表的线程任务最后返回的结果。如果 Future 代表的线程任务还未完成,该方法将会阻塞当前线程,其中 timeout 参数指定最多阻塞多少秒。
exception(timeout=None):获取该 Future 代表的线程任务所引发的异常。如果该任务成功完成,没有异常,则该方法返回 None。
add_done_callback(fn):为该 Future 代表的线程任务注册一个“回调函数”,当该任务成功完成时,程序会自动触发该 fn 函数。
as_completed()方法用于将线程池返回的future对象按照线程完成的顺序排列,不加也可以,不加则返回的顺序为按线程创建顺序返回。with语句将自动关闭线程池,也就是自动执行shutdown方法。
在用完一个线程池后,应该调用该线程池的
shutdown()方法,该方法将启动线程池的关闭序列。调用shutdown()方法后的线程池不再接收新任务,但会将以前所有的已提交任务执行完成。当线程池中的所有任务都执行完成后,该线程池中的所有线程都会死亡。
步骤
- 调用 ThreadPoolExecutor 类的构造器创建一个线程池。
- 定义一个普通函数作为线程任务。
- 调用 ThreadPoolExecutor 对象的 submit() 方法来提交线程任务。
- 当不想提交任何任务时,调用 ThreadPoolExecutor 对象的 shutdown() 方法来关闭线程池。
map 和 submit对比
- 易用性
map()方法比较容易使用,它的参数是一个==可迭代对象==(如列表)和一个函数,函数将被应用于可迭代对象中的每个元素,然后返回一个生成器对象,生成器对象可以逐个访问结果。submit()方法的使用要稍微复杂一点,需要单独执行每个线程执行任务,并使用Future对象来管理和访问结果。
- 控制方法
使用map()方法时,线程的数量是由线程池中的工作线程数量决定的。如果你想要更细粒度的控制,可以使用submit()方法,使用max_workers参数来指定线程池的大小,使用shutdown()方法来关闭线程池。
- 访问方法
使用map()方法时,无法访问单独的线程和它们的结果,只能访问生成器对象中的一个接一个的结果。使用submit()方法时,可以访问每个线程的状态,可以使用Future对象的方法来检查和访问线程结果。例如,可以使用done()方法来检查线程是否完成,使用result()方法来访问线程的返回值,使用exception()方法来访问线程的异常。
总的来说,map()方法更简单易用,并且适用于处理一组数据集。submit()方法更加灵活,允许你更好地控制线程池,并且可以访问单个线程状态和结果。
线程池原理 好处
新建线程需要分配资源、终止线程需要回收资源,如果可以重用线程,则可以减去新建/终止的开销

- 提升性能:减去了大量新建、终止线程的开销,重用了线程资源
- 适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短
- 防御功能:能有效避免系统因为创建线程过多,从而导致系统负荷过大相应变慢等问题
- 代码优势:使用线程池的语法比自己新建线程执行线程更加简洁
使用方法示例
ThreadPoolExecutor()构造参数:
max_workers设置线程池中最多能同时运行的线程数目。thread_name_prefix线程名字前缀initializer在每个工作线程启动之前,执行初始化函数,如果没有指定,默认为None。initargs传递给初始化函数的参数元组,如果没有指定,默认为空元组()。
from concurrent.futures import ThreadPoolExecutor,as_completed # 用法1:map函数,注意map的结果和入参顺序是对应的 with ThreadPoolExecutor() as pool: results = pool.map(func_name,args) for result in results: print(result) # 用法2:future模式,更强大,注意如果用as_completed顺序是线程执行完成的顺序 with ThreadPoolExecutor() as pool: futures = [pool.submit(func_name,args) for args in urls] # 2.1用法 for future in futures: print(future.result()) # 2.2用法 for future in as_completed(futures): print(future.result())
代码示例
from concurrent.futures import ThreadPoolExecutor import time # 参数times用来模拟网络请求的时间 def get_html(times): time.sleep(times) print("get page {}s finished".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) # 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞 task1 = executor.submit(get_html, (3)) task2 = executor.submit(get_html, (2)) # done方法用于判定某个任务是否完成 print(task1.done()) # cancel方法用于取消某个任务,该任务没有放入线程池中才能取消成功 print(task2.cancel()) time.sleep(4) print(task1.done()) # result方法可以获取task的执行结果 print(task1.result()) # 执行结果 # False # 表明task1未执行完成 # False # 表明task2取消失败,因为已经放入了线程池中 # get page 2s finished # get page 3s finished # True # 由于在get page 3s finished之后才打印,所以此时task1必然完成了 # 3 # 得到task1的任务返回值
web服务使用线程池加速
1)threaded : 多线程支持,默认为False,即不开启多线程;
2)processes:进程数量,默认为1.
ps:多进程或多线程只能选择一个,不能同时开启
使用示例:
app.run(host=myaddr,port=myport,debug=False,threaded=True) ### threaded开启以后 不需要等队列 threaded=True #或者 #app.run(host=myaddr,port=myport,debug=False,processes=3) ### processes=N 进程数量,默认为1个
flask加速
from flask import Flask from time import sleep from concurrent.futures import ThreadPoolExecutor # DOCS https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ThreadPoolExecutor executor = ThreadPoolExecutor(2) app = Flask(__name__) @app.route('/jobs') def run_jobs(): # 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞 executor.submit(long_task, 'hello', 123) return 'long task running.' def long_task(arg1, arg2): print("args: %s %s!" % (arg1, arg2)) sleep(5) print("Task is done!") if __name__ == '__main__': app.run()
有了多线程为什么还要有多进程?
如果是CPU密集型计算,多线程反而会降低速度(多线程只占用一个处理机,它能实现CPU运算和IO同时运行,也就是一个线程进入IO后能直接转入下一个线程的执行,但是也因为它只占用一个处理机,同一时刻只能有一个线程进行CPU运算)
多进程知识梳理

对于CPU密集型计算的运行时间对比

web服务使用进程池
和线程池类似,注意的地方就是flask使用进程池要傲娇一些
if __name__ == "__main__": process_pool = ProcessPoolExecutor() app.run()
单线程爬虫的执行路径

协程:在单线程内实现并发
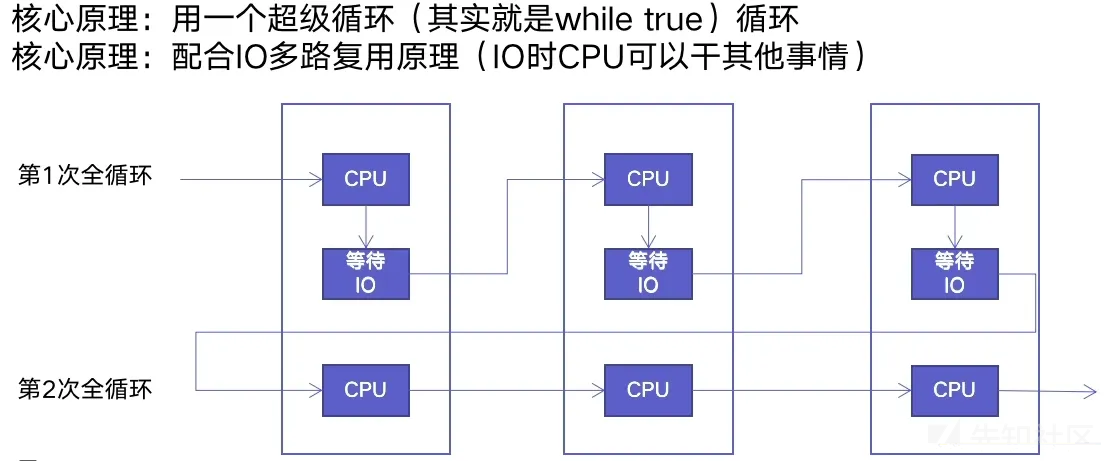
异步IO库:asyncio
import asyncio #获取事件循环 loop = asyncio.get_event_loop() #定义协程 async def myfunc(url): await get_url(url) #创建task列表 tasks = [loop.create_task(myfunc(url)) for url in urls] #执行爬虫事件列表 loop.run_until_complete(asyncio.wait(tasks))
==注意:==
要用在异步IO编程中,依赖的库必须支持异步IO特性
爬虫引用中:requests 不支持异步需要用aiohttp
如有侵权请联系:admin#unsafe.sh