原文标题:MARBLE: Mining for Boilerplate Code to Identify API Usability Problems原文作者:Daye Nam, Amber Horv 2023-8-18 23:4:36 Author: 安全学术圈(查看原文) 阅读量:30 收藏
原文标题:MARBLE: Mining for Boilerplate Code to Identify API Usability Problems
原文作者:Daye Nam, Amber Horvath, Andrew Macvean, Brad Myers, Bogdan Vasilescu
原文链接:https://cmustrudel.github.io/papers/ase19marble.pdf
发表会议:ASE 2019
笔记作者:[email protected]安全学术圈
主编:黄诚@安全学术圈
1、研究介绍
设计易用的API对于开发人员的生产力和软件质量至关重要,但是如何设计易用的API也非常困难。由于缺乏一种大规模自动化方法来挖掘API的可用性数据,因此很难预测API的易用性障碍和真实世界使用情况。
本文重点了讨论API使用中的样板代码(Boilerplate Code),因为从一些API设计者的视角,样板代码的存在通常反映了API的具有较差的可用性。样板代码通常具有很大的重复性,通常被认为是一种冗余而又不得不写的代码,可以通过元编程等高级机制来减少对样板代码的需求。
作者针对样板代码这一问题开展了研究,总的来说包括四个方面:1)样板代码挖掘问题;2)样板代码的标识性特点;3)样板代码自动化挖掘算法;4)针对13个Java库的观察研究。
2、研究内容
2.1 认识样板代码
作者通过进行文献收集、问卷调查以及收集论坛问题和代码仓库commit作为原始材料。在这些材料的基础上作者从三个方面开展了对样板代码的研究:1)样板代码背后的设计机理;2)样板代码的存在原因;3)开发者们如何应对样板代码。
作者最终归纳了样板代码的四个特点:
Undesirable:模板代码通常带有主观的负面评价,并且将简单的实现方式复杂化; High frequency:样板代码通常在不同的上下文中多次出现,其高频属性意味着样板代码示例应该在常见的 API 代码示例中找到; Localized:这些模板代码的例子都是在单个方法或类内部紧密地排列,这使得它们更容易被识别; Little structural variation:样板代码实例通常以相似的形式出现,没有明显的结构变化。因为这些代码通常被频繁地复制粘贴,并且没有进行大的修改。
而对于样板代码存在的原因,作者则借用了代码克隆[1]中的类似概念,包括开发策略、维护效益、克服底层限制以及意外克隆。
通过对commit中的样板代码进行分析,作者发现大部分减少模板代码的方法是引入新的辅助函数或类。
2.2、样板代码挖掘
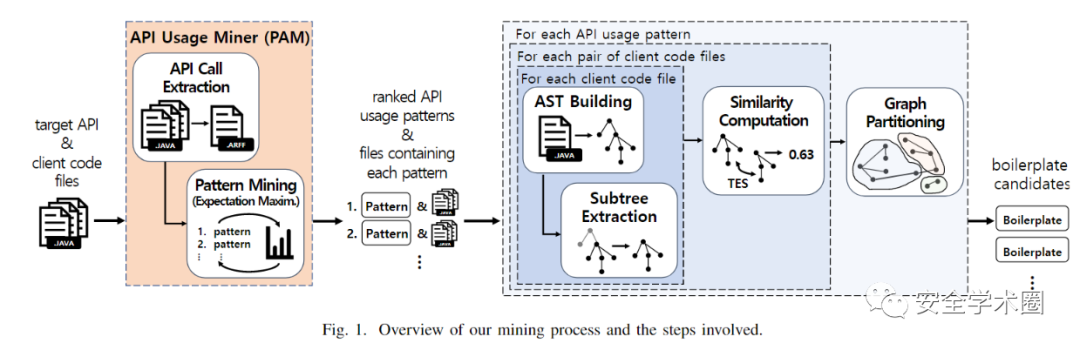
作者使用了开源的API序列挖掘工具PAM[2]对选定的13种常用API的使用模式,具体而言PAM首先对每个源代码文件进行解析,并从每个方法种提取目标API的调用序列,然后使用深度优先遍历抽象语法树的方法进行解析,同时记录每个API调用在不同方法中的频率信息,以通过期望最大算法来构建概率模型(对应样板代码的High frequency这一特点),以识别常见的API调用序列。
仅关注API的使用模式则忽略了代码中的结构信息,因此作者对包含对应API行为模式的文件首先进行文件级的抽象语法树构建(对应了样板代码的Localized这一特点),然后通过分解方法级语法子树进一步缩小样板代码的范围。
而第三步作者则通过样板代码的第三个特点(Little structural variation)来对其进行挖掘,对于包含相同API行为模式的文件首先计算了二者间的树相似度。
然后作者利用相似度构建了一个有权图,通过 Louvain 社区发现算法对具有高度相似性的样板代码进行检测。
3、个人思考
本文通过对分析样板代码的问题以小见大,在挖掘方法中充分利用了的样板代码的各种特点,层层递进。本文仅对Java生态中的样板代码进行了分析,此后还可以应用于其他语言生态。
论文作者信息
论文作者:Daye Nam 作者介绍:卡内基梅隆大学博士生,研究方向涉及软件工程、人工智能和人机交互的交叉领域,旨在改进API的可用性。 个人主页:https://dayenam.com/
参考文献
[1] ROY ChanchalK, CORDY JamesR. A Survey on Software Clone Detection Research[J]. 2007.
[2] Fowkes J, Sutton C. Parameter-Free Probabilistic API Mining Across GitHub[C]//Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. 2016: 254-265.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh