
在上篇文章里,我们从Joern入手大致介绍了CPG(Code Property Graph)的设计理念和简单逻辑
但实际上来说,如果想要更深入的了解Joern,CPG和图数据库是绕不开的一个话题。CPG作为一种代码属性图,就必须寻找一种图数据库作为载体,就像我们常用的数据和SQL数据库的关系一样。
旧版本的Joern使用的Gremlin,但后来的开发中换成了OverflowDB,在joern中也完全支持使用OverflowDB的查询语法。
但属性图本身没有什么特异性,比较常见的比如Neo4J,OrientDB或者JanesGraph都支持CPG的表现形式。
但,在这之前,我们首先需要知道,为什么是图?
在上篇文章中,我在讲了CPG的设计思路时曾经提到过一些相关的内容。
如果说CFG(control flow graphs)相比AST来说最大的特点是带有明确数据流向的流向,在数据流分析可能更有优势。
那么CPG相比CFG来说有一个很大的特点就是信息量大,而图最大的特点也在于,就是可以容纳信息量巨大的内容。
假设我们有这样一段代码
1 | a = new A() |
这里简单的几行代码,其实展示了相当复杂的依赖链,abcd几个变量中有着复杂的互相指向关系,如果用文字来表示abcd之间的关系我们可能需要拆分很多部分。
1 | a -> A() |
我甚至很难用文字的方式表达出他们之间的关系,而图在这样的场景下就变得很有优势。
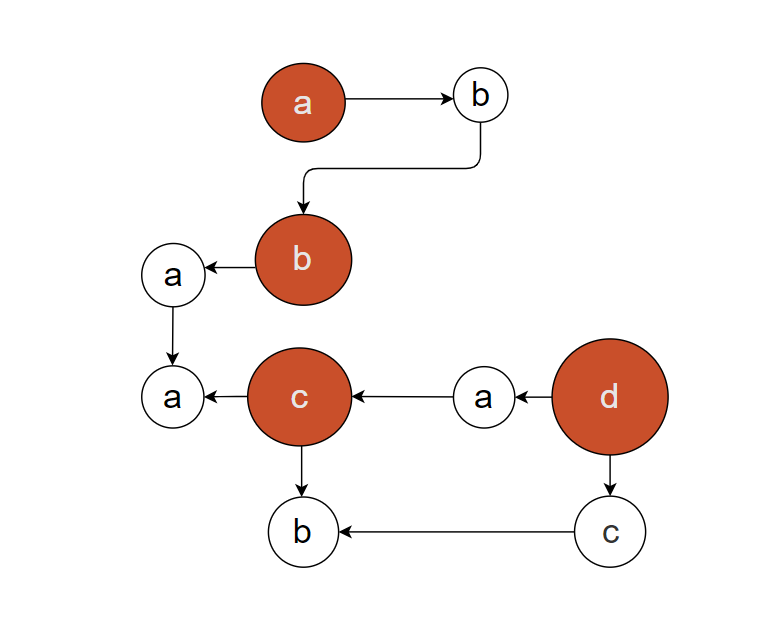
当然这只是一个粗浅的例子,但已经很明显的能感觉出来图和文字之间的差距了,图关系可以很轻松的表达出文字很难表达出来的信息量。
Joern用了CPG来储存代码的所有节点关系和属性数据,由于CPG的信息量大,所以Joern甚至提供了官方的生成AST、CFG等其他结构的接口,对于C/C++甚至支持多种自定义的结构。
- Abstract Syntax Trees (AST)
- Control Flow Graphs (CFG)
- Control Dependence Graphs (CDG)
- Data Dependence Graphs (DDG)
- Program Dependence graphs (PDG)
- Code Property Graphs (CPG14)
- Entire graph, i.e. convert to a different graph format (ALL)
在Joern的命令行你可以直接使用相应的命令生成对应的格式
1 | cpg.method($name).dotAst.l // output AST in dot format |
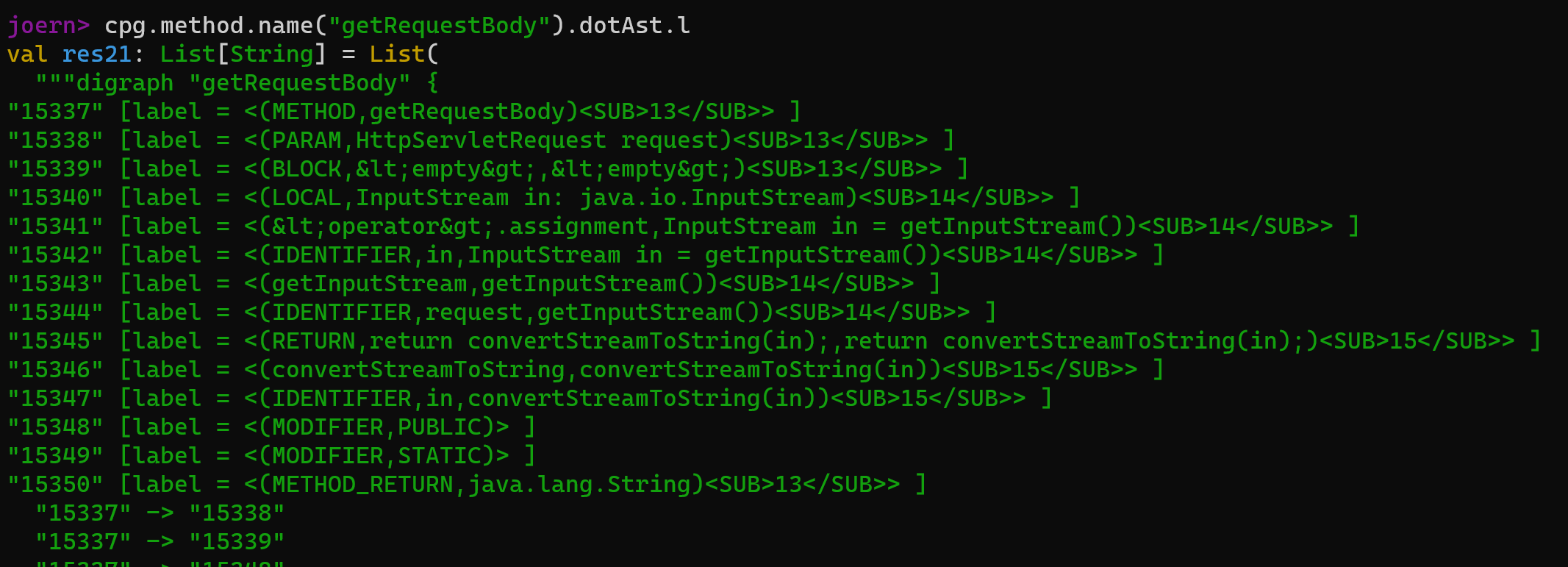
有个很有意思的是,如果你的电脑装了Graphviz,Joern还可以调用Graphviz来绘图,虽然生成的图很难看。
安装Graphviz之后我们可以通过命令来绘图
1 | cpg.method($name).plotDotAst // plot AST |
说实话,不太实用,但是很方便
相比Graphviz这种仅仅用来临时展示图的应用来说,Neo4J则是标准而且非常成熟的图数据库,不但性能强,而且还实用。
你可以在官网下载免费的neo4j,其中包括服务端和客户端版本,服务端版本启动后会默认跑到7474端口上。
Neo4j使用的查询语言叫做Cypher,这是一种声明式的图查询语言,我个人觉得Cypher其实算是比较反人类的一种语言,具体的语法可以看对应的文档。
简单来讲Cypher中对应SQL的语句关系有几个比较特别的,首先就是MATCH和where。
1 |
|
MATCH和where在两种查询语句中是类似的功能,其中的区别就是MATCH匹配的是图中节点之间的关系。Cypher语法比较强调节点之间的关系,比如-就是无方向关系,->就是有方向关系。
1 | match |
其他的比如创建节点、删除节点、创建关系、搜索匹配的节点以及关系等等就不赘述了,算是比较符合理解的语言逻辑。
而相对于普通的数据库来说,图数据库有着可能是一种优势的特性,就是可以直接通过Neo4j的浏览器直接操作图内容以及结构。
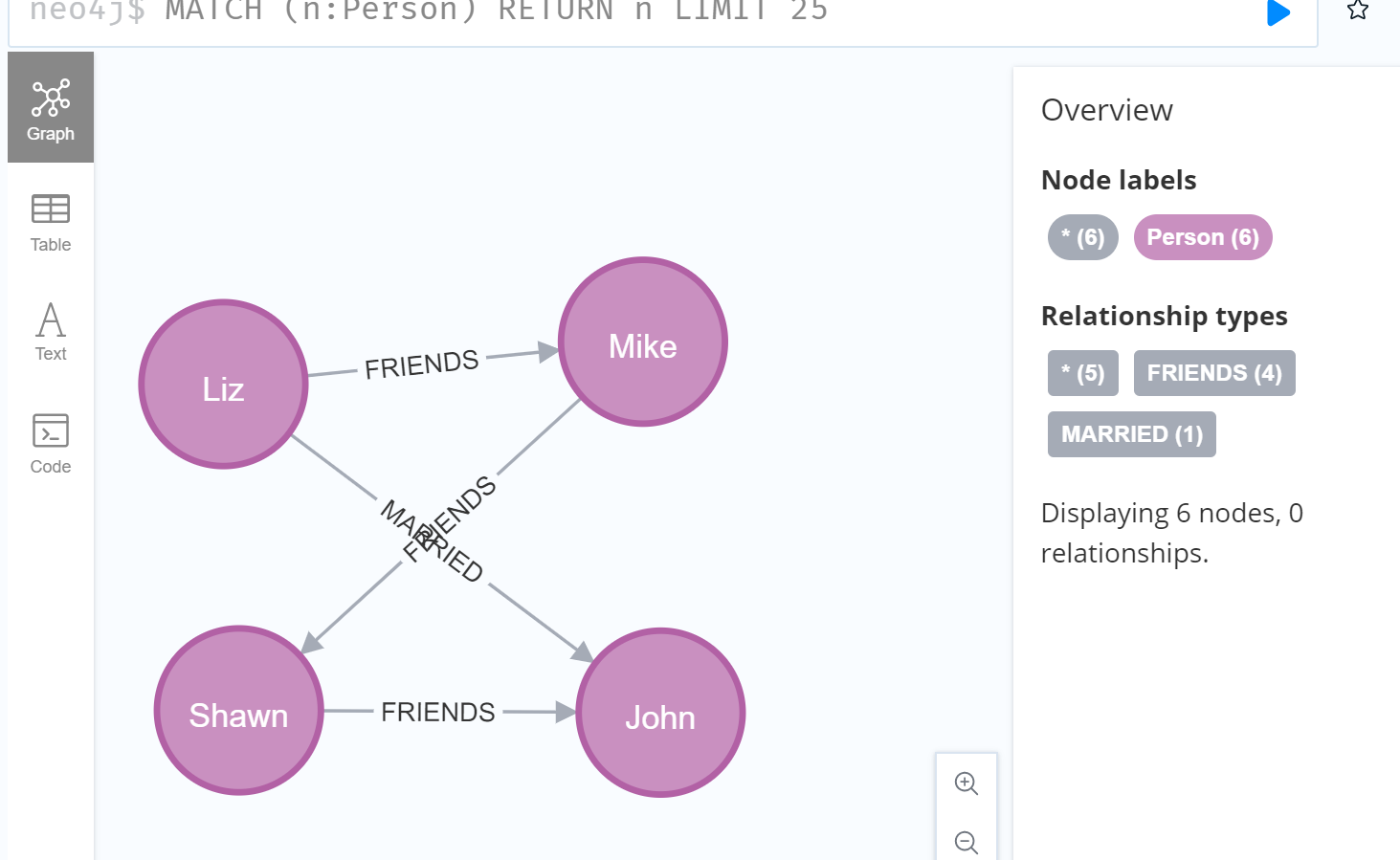
直接用鼠标点击各个节点查看对应的属性以及它们之间的关系,并且可以直接拖动他们。
点击节点下面的按钮,可以直接查看到节点连接到的其他节点,很方便也很直观。
前面说了,Joern使用了自己做的OverflowDBl来作为图数据库存储CPG,但CPG本身没有什么特异性,也就意味着他可以在任意一种图数据库上导入。
而Joern本身是自带了这个功能的,就是joern-export。它支持你导出Joern的CPG到neo4j , graphml, graphson 和 graphviz dot。
1 | ./joern-export --repr=all --format=neo4jcsv |
要使用joern-export导出数据的话,需要指定CPG的位置,这个东西会存在Joern目录下的workspace当中,并且需要指定output,默认是./out。
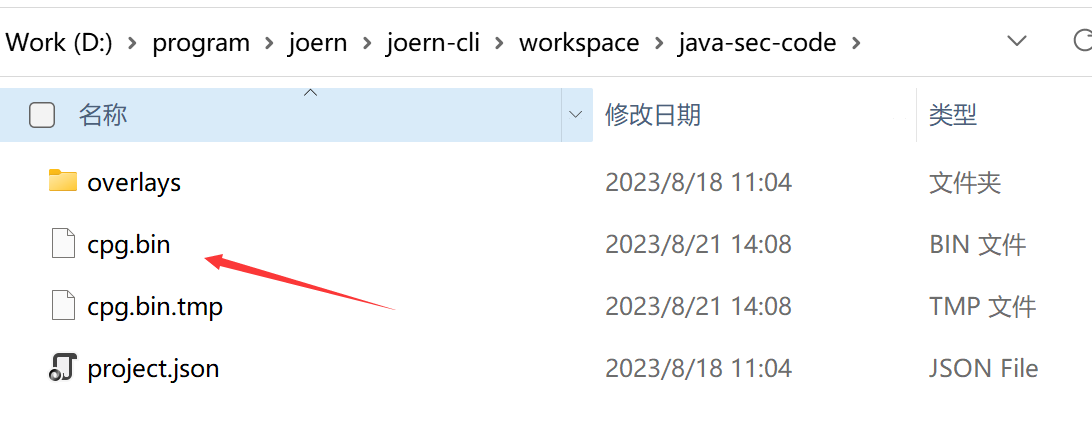

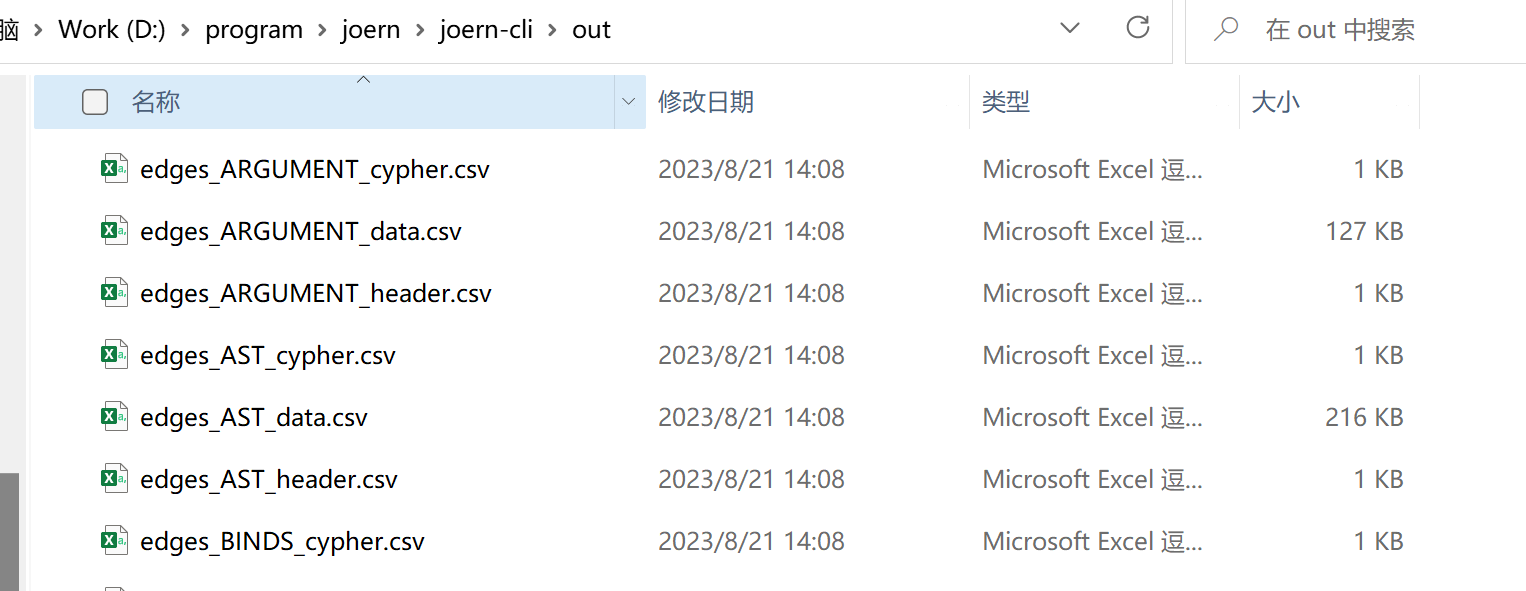
然后我们可以想办法把这些csv文件导入到Neo4j当中。当然你可以用一些自己的方式导入,但joern的这个图还挺麻烦的,主要是neo4j导入复杂结构数据需要指定好各种csv文件的关联。
但joern当然也给出了导入的办法,在生成文件的时候会给出一个导入命令的范例,照着范例就可以搞定了。
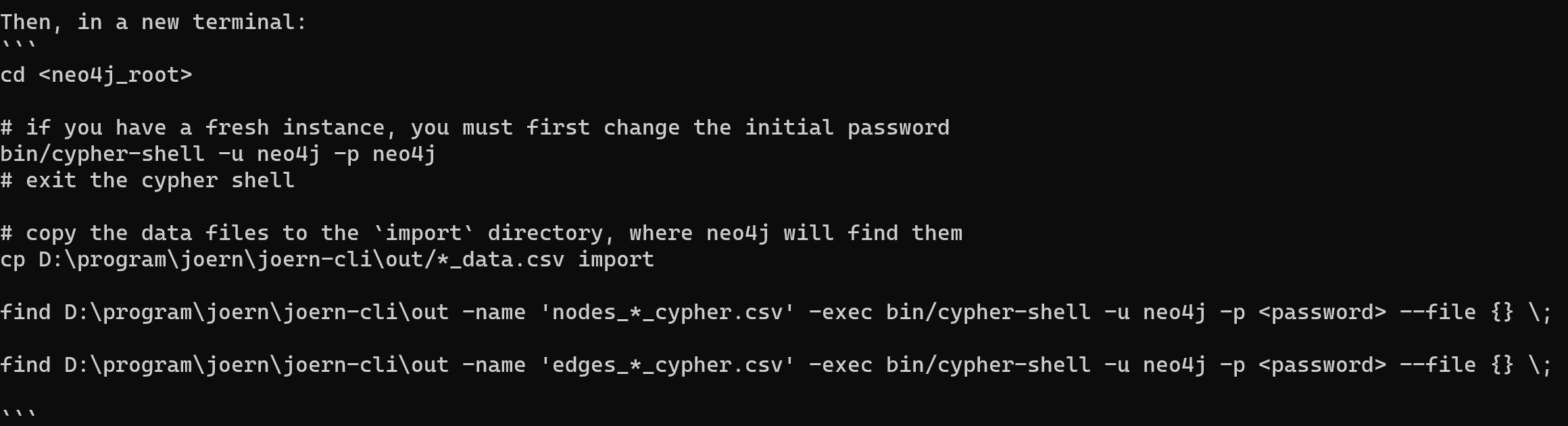
首先joern导入数据是有限制的,只能导入import目录下的文件,这个import文件一般会在对应链接的server目录下面,如果你使用的是neo4j的desltop浏览器,那么你可以直接打开对应的import目录,并把文件复制过去。
除了文件以外,还有就是这个/bin/cypher-shell的位置,这个脚本就在对应链接目录的bin下
然后构造对应的find命令生成执行导入即可,其实它的原理也比较简单,就是依次执行*_cypher.csv文件中的命令,然后导入header和data。

最终导入的数据就是这样的
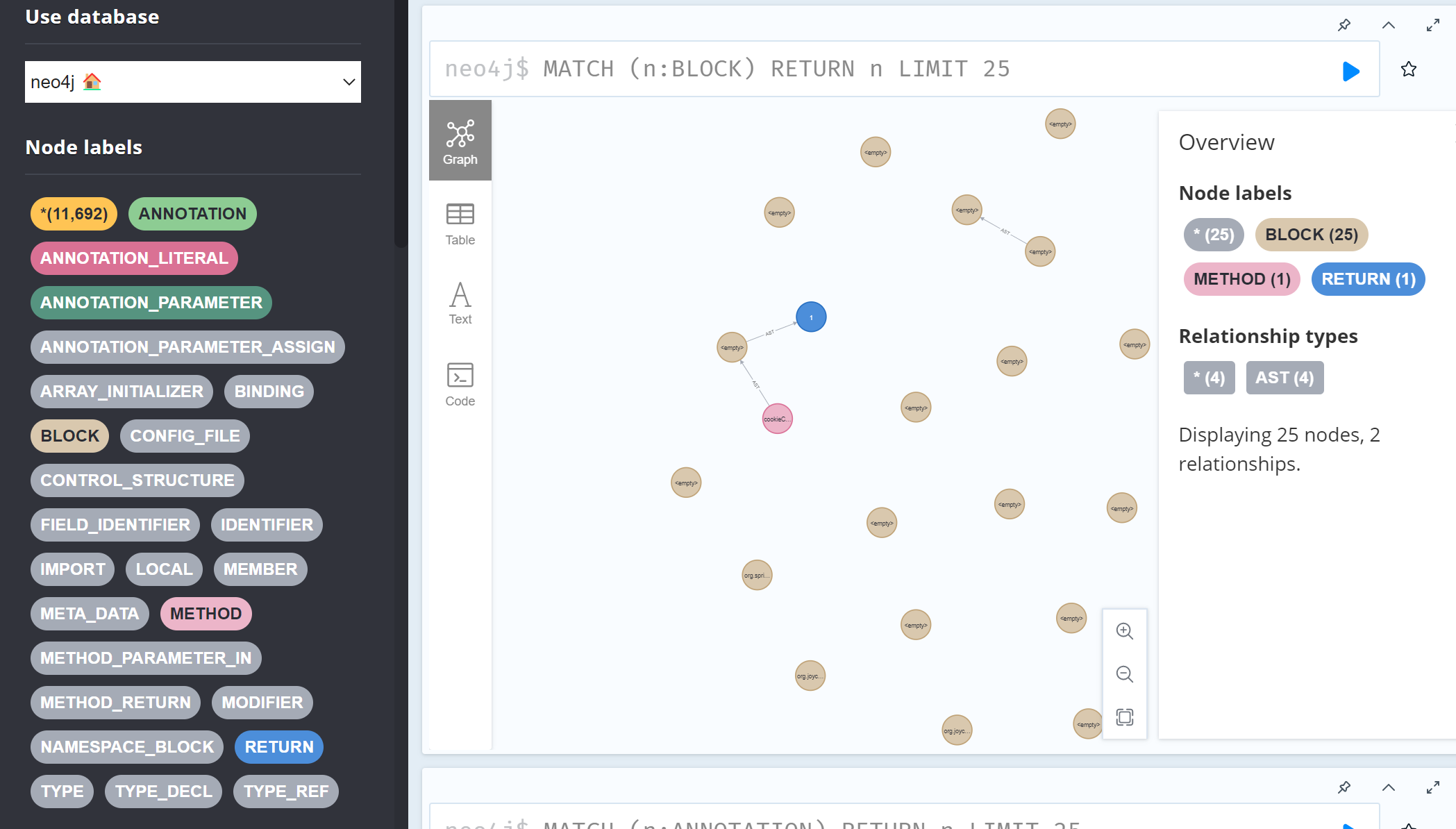
当我们把CPG导入到Neo4J上之后,理论上来说我们可以用cypher来完成我们在Joern中做的所有工作。
这里还是拿上篇文章中用到的RCE代码来举例子。
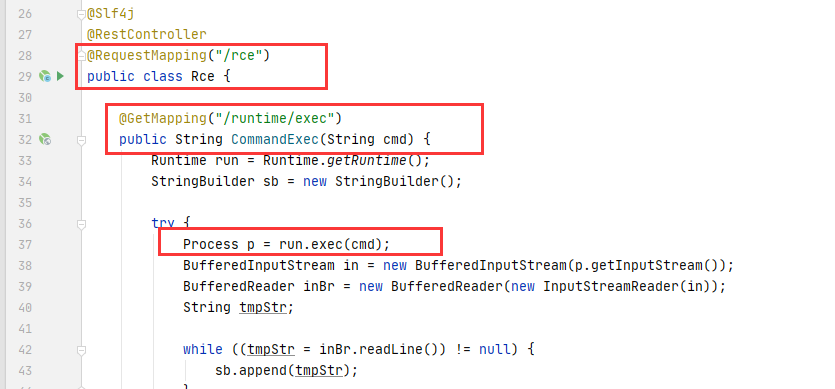
对应Joern的语句为
1 | def source = cpg.method.where(_.annotation.name(".*Mapping")).parameter |
首先匹配注解节点满足.*Mapping的
1 | MATCH (n:ANNOTATION) where n.NAME=~".*Mapping" RETURN n LIMIT 25 |
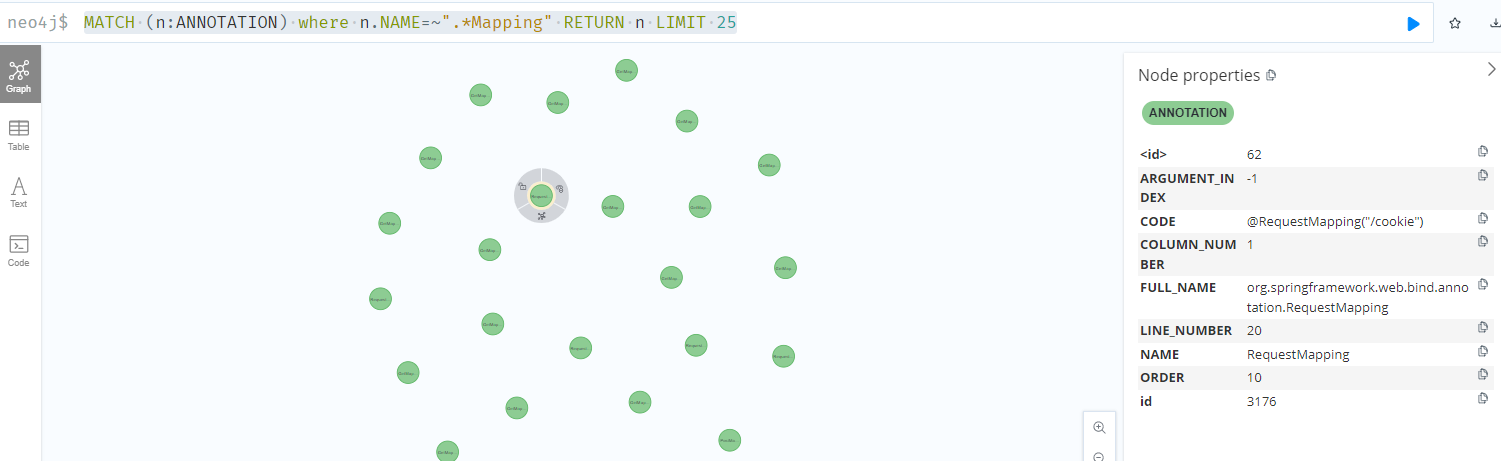
然后找这些对应节点关联的方法
1 | MATCH (m:METHOD)-[:AST]->(n:ANNOTATION) where n.NAME=~".*Mapping" RETURN n LIMIT 25 |

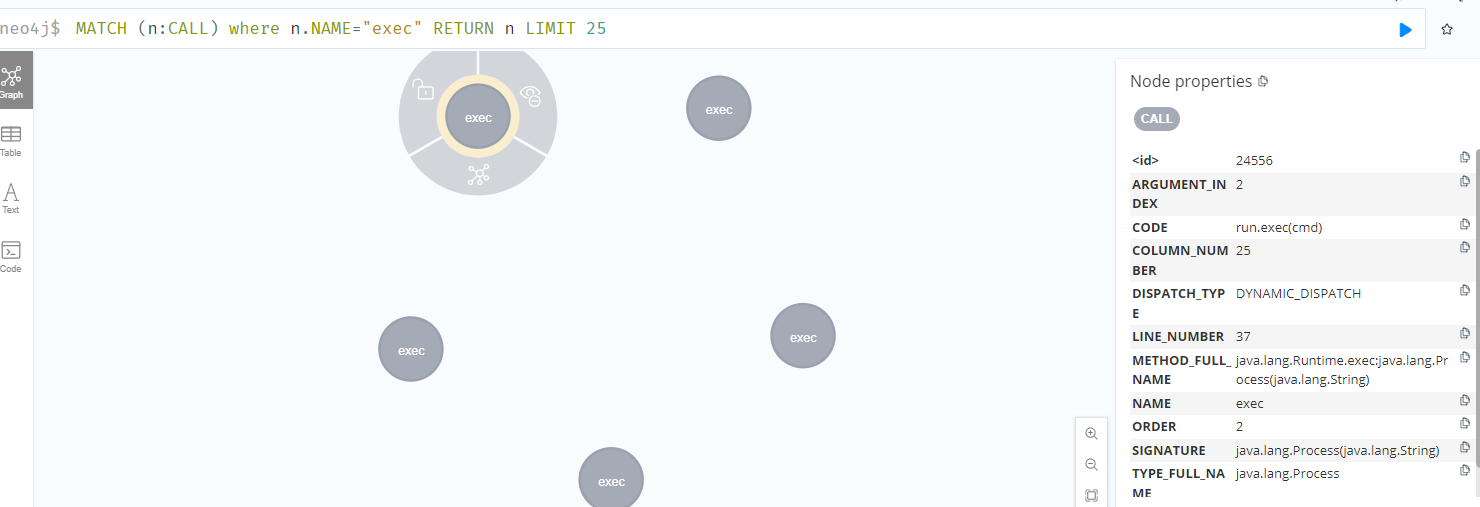
然后找一下对应调用exec方法的节点
1 | MATCH (n:CALL) where n.NAME="exec" RETURN n LIMIT 25 |
然后我们把两个节点连接起来,并查找最短路径,这里的[*..10]表示最长不超过10个关系
1 | MATCH (p1:METHOD)-[:AST]->(n:ANNOTATION),(p2:CALL),p=shortestpath((p1)-[*..10]-(p2)) where n.NAME=~".*Mapping" and p2.NAME="exec" RETURN p LIMIT 25 |
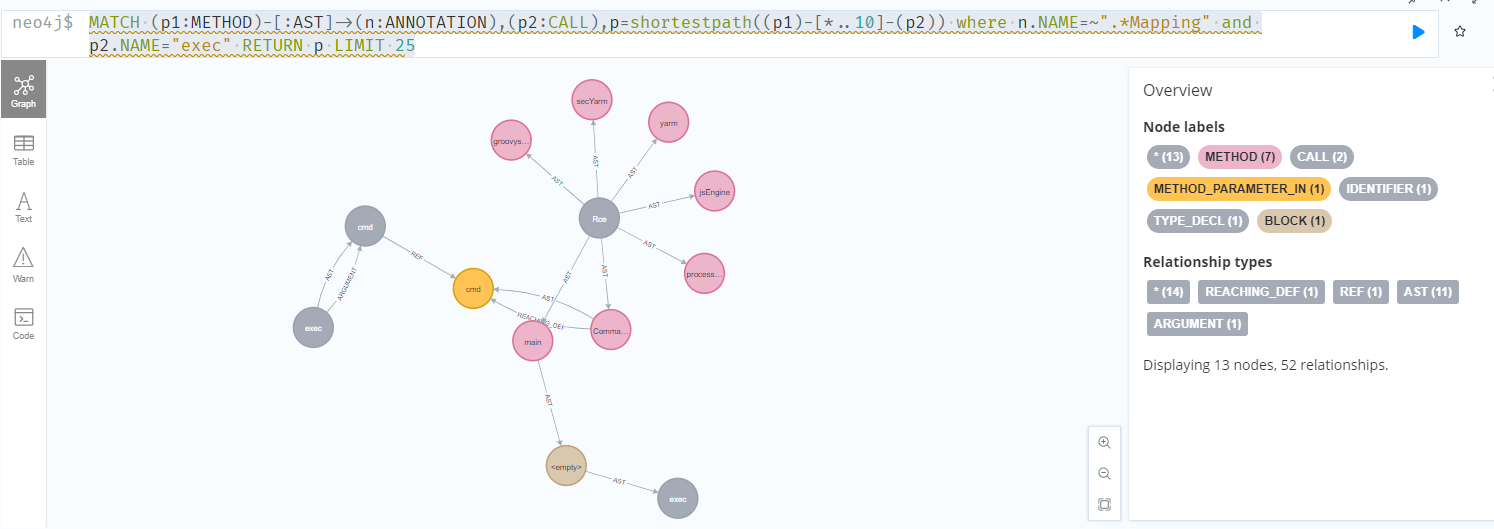
这里范例算是比较简单的,所以用这个还算比较简单的语句就可以查询到结果,正好对应漏洞利用链。