看到群友分享的帖子:https://blogs.jpcert.or.jp/en/2023/08/maldocinpdf.html。原文展示了一个样本,可以在pdf中嵌入一个恶意的doc文档,并可以正常执行其中的宏代码,文章只展示了这个样本,并没有详细说明是为什么,这就引发了我的兴趣,决定探究一番。
在说正事之前,我还需要再补充点基础知识,为什么伪装了文件类型会有助于免杀呢?这就需要说一下杀毒引擎的工作过程了,一般一个杀软收到一个文件之后会进行如下几个步骤:
如果文件格式都识别错误了,那么后续的格式解析特征提取肯定是错的,所以就直接免杀了。
拿到文件后,先file一下,可以看到file识别的文件格式确实是pdf:
PDF document, version 1.7, 1 pages (zip deflate encoded)但是与普通文件不同的是这里多了一个 1 pages (zip deflate encoded)接下来用文本编辑器打开:
看起来pdf该有的东西也是有的,只不过pdf格式是不合法的,我用010editor 和 pdf阅读器都不能正常打开此文件。
文章中说 olevba可以识别到此文件中的ole,那我们就试一下:
可以直接获取到启动的vba代码,仔细看输出的日志,可以发现其实olevba是把此文件当做mhtml处理了:
mhtml又是个啥,万能群友发给我一个资料:https://blog.csdn.net/cssxn/article/details/88128741
这个mhtml牛的地方在于,他是个文本文件,还可以执行宏代码,那我也按照帖子的方法制作一个。
看到文件头是:
但是我在样本中并没有搜到这个头呀?既然没有那olevba是怎么识别的呢?
读一下olevba的源代码:
原来只需要mime这个字符串就可以,找一下源样本文件。
样本为了防止被识别这里故意对文件头进行了混淆,还能被word软件识别大概率是因为mhtml文件的容错率是比较高的,这点改动不影响
接下来问题来了,恶意的VBA存储在这个文件的什么位置呢?既然olevba可以识别,那我们可以直接看源码:
try:
if PYTHON2:
mhtml = email.message_from_string(stripped_data)
else:
# on Python 3, need to use message_from_bytes instead:
mhtml = email.message_from_bytes(stripped_data)
finally:
email.feedparser.headerRE = oldHeaderRE
# find all the attached files:
for part in mhtml.walk():
content_type = part.get_content_type() # always returns a value
fname = part.get_filename(None) # returns None if it fails
# TODO: get content-location if no filename
log.debug('MHTML part: filename=%r, content-type=%r' % (fname, content_type))
part_data = part.get_payload(decode=True)
# VBA macros are stored in a binary file named "editdata.mso".
# the data content is an OLE container for the VBA project, compressed
# using the ActiveMime/MSO format (zlib-compressed), and Base64 encoded.
# decompress the zlib data starting at offset 0x32, which is the OLE container:
# check ActiveMime header:
if isinstance(part_data, bytes) and is_mso_file(part_data):
log.debug('Found ActiveMime header, decompressing MSO container')
try:
ole_data = mso_file_extract(part_data)可以看到这里使用 email 库来解析文件内容,如果解码出来的内容是 mso_file文件,就进入到解析ole格式的解析流程。
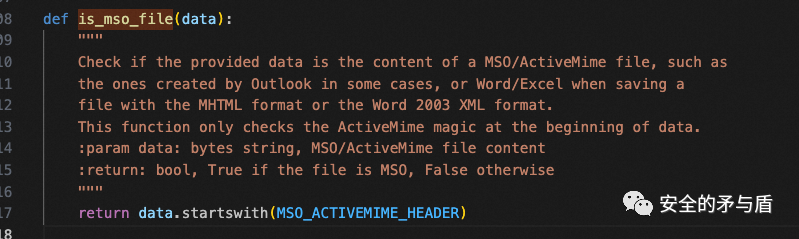
is_mso_file函数是判断解码出来的内容是否是ActiveMime开头的:
我们找到文件对应的位置,发现是一片狼藉:
里面包含很多空格和换行,显然是无法被base64解码的,那是怎么回事呢?继续跟踪 email库的get_payload代码:
发现在解码之前会经过很多的容错处理,其中就包括删除空格和换行,所以可以明确了,样本就是利用这里的容错机制进行混淆以绕过检测。手工去除换行和空格,发现对应的字符刚好就是 QWN0aXZlTWltZQAA
我最简单的想法是直接在一个pdf文件后面填充一个 mhtml文件,然后把后缀修改为pdf,看看可以不。
结果证明不行...也就是说他这个pdf肯定是特殊构造的,刚才输出的 1 pages (zip deflate encoded)可能是有用的,那我把原样本的pdf部分直接复制到我的mhtml文件中,发现可以了。
对PDF文件格式不是太了解,并不清楚pdf是怎么构造的,相关的样本可以在星球下载,也欢迎大家加入星球参与讨论。
咨询微信
如有侵权请联系:admin#unsafe.sh