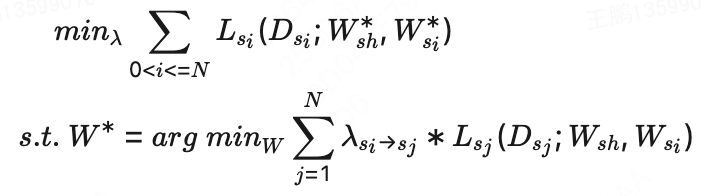
1 引言
美团到家Demand-Side Platform(下文简称DSP)平台,主要负责在美团外部媒体上进行商品或者物料的推荐和投放,并不断优化转化效果。随着业务的不断发展与扩大,DSP对接的外部渠道越来越丰富、展示形式越来越多样,物料展示场景的差异性愈发明显(如开屏、插屏、信息流、弹窗等)。
例如,用户在午餐时间更容易点击【某推荐渠道下】【某App】【开屏展示位】的快餐类商家的物料而不是【信息流展示位】的啤酒烧烤类商家物料。场景间差异的背后本质上是用户意图和需求的差异,因此模型需要对越来越多的场景进行定制化建设,以适配不同场景下用户的个性化需求。
业界经典的Mixture-of-Experts架构(MoE,如MMoE、PLE、STAR[1]等)能一定程度上适配不同场景下用户的个性化需求。这种架构将多个Experts的输出结果通过一个门控网络进行权重分配和组合,以得到最终的预测结果。早期,我们基于MoE架构提出了使用物料推荐渠道进行场景划分的多场景建模方案。然而,随着业务的不断壮大,场景间的差异越来越大、场景数量也越来越丰富,这版模型难以适应业务发展,不能很好地解决DSP背景下存在的以下两个问题:
- 负迁移现象:以推荐渠道为例,由于不同推荐渠道的流量在用户分布、行为习惯、物料展示形式等方面存在差异,其曝光数、点击率也不在同一个数量级(如下图1所示,不同渠道间点击率相差十分显著),数据呈现典型的“长尾”现象。如果使用推荐渠道进行多场景建模的依据,一方面模型会更倾向于学习到头部渠道的信息,对于尾部渠道会存在学习不充分的问题,另一方面尾部渠道的数据也会给头部渠道的学习带来“噪声”,导致出现负迁移。
- 数据稀疏难以收敛:DSP会在外部不同媒体上进行物料展示,而用户在访问外部媒体时,其所处的时空背景、上下文信息、不同App以及物料展示位等信息共同构成了当前的场景,这样的场景在十万的量级,每个场景的数据又十分稀疏,导致模型难以在每个场景上得到充分的训练。
在面对此类建模任务时,业界现有的方法是在不同场景间进行知识迁移。例如,SAML[2]模型采用辅助网络来学习场景的共享知识并迁移至各场景的独有网络;ADIN[3]和SASS[4]模型使用门控单元以一种细粒度的方式来选择和融合全局信息到单场景信息中。然而,在DSP背景中复杂多变的流量背景下,场景差异性导致了场景数量的急剧增长,现有方法无法在巨量稀疏场景下有效。
因此,在本文中我们提出了DSP背景下的自适应场景建模方案(AdaScene, Adaptive Scenario Model),同时从知识迁移和场景聚合两个角度进行建模。AdaScene通过控制知识迁移的程度来最大化不同场景共性信息的利用,并使用稀疏专家聚合的方式利用门控网络自动选择专家组成场景表征,缓解了负迁移现象;同时,我们利用损失函数梯度指导场景聚合,将巨大的推荐场景空间约束到有限范围内,缓解了数据稀疏问题,并实现了自适应场景建模方案。

2 自适应场景建模
在本节开始前,我们先介绍多场景模型的建模方式。多场景模型采用输入层 Embedding + 混合专家(Mixture-of-Experts, MoE)的建模范式,其中输入信息包括了用户侧、商家侧以及场景上下文特征。多场景模型的损失由各场景的损失聚合而成,其损失函数形式如下:

其中,$K$为场景数量,$α_i$为各场景的损失权重值。
我们提出的AdaScene自适应场景模型主要包含以下2个部分:场景知识迁移(Knowledge Transfer)模块以及场景聚合(Scene Aggregation)模块,其模型结构如下图2所示。场景知识迁移模块自适应地控制不同场景间的知识共享程度,并通过稀疏专家网络自动选择 K 个专家构成自适应场景表征。场景聚合模块通过离线预先自动化衡量所有场景间损失函数梯度的相似度,继而通过最大化场景相似度来指导场景的聚合。

该模型结构的整体损失函数如以下公式所示:

其中,$\alpha_{k}$为每个场景组的损失函数所对应的系数,$G_k$为第$k$个场景组下的的场景数量,$G$为某种场景组的划分方式。
下面,我们分别介绍自适应场景知识迁移和场景聚合的建模方案。
2.1 自适应场景知识迁移
在多场景建模中,场景定义方式决定了场景专家的学习样本,很大程度上影响着模型对场景的拟合能力,但无论采用哪种场景定义方式,不同场景间用户分布都存在重叠,用户行为模式也会有相似性。
为提升不同场景间共性的捕捉能力,我们从场景特征和场景专家两个维度探索场景知识迁移的方法,在以物料推荐渠道×App×展示形态作为多场景建模Base模型的基础上,构建了如下图3所示的自适应场景知识迁移模型(Adaptive Knowledge Transfer Network, AKTN)。该模型建立了场景共享参数与私有参数的知识迁移桥梁,能够自适应地控制知识迁移的程度、缓解负迁移现象。

- 场景特征适配:通过Squeeze-and-Excitation Network[5]构建场景适应层(Scene Adaption Layer),其结构可表示为$F_{SE}= FC( ReLU( FC(x)))$,其中$FC$表示全连接层,$ReLU$为激活函数。由于不同场景对原始特征的关注程度存在较大差异,该层能够根据不同场景的信息生成原始特征的权重,并利用这些权重对输入特征进行相应的变换,实现场景特定的个性化输入表征,提高模型的场景信息捕捉能力。
- 场景知识迁移:使用GRU门控单元构建场景知识迁移层(Scene Transfer Layer)。GRU门控单元通过场景上下文信息对来自全局场景专家和当前场景专家的信息流动进行控制,筛选出符合当前场景的有用信息;并且,该结构能以层级方式进行堆叠,不断对场景输出进行修正。
场景特征适配在输入层根据场景信息对不同特征进行权重适配,筛选出当前场景下模型最关注的特征;场景知识迁移在隐层专家网络中进行知识迁移,控制共享专家中共性信息向场景独有信息的流动,使得场景共性信息得以传递。
这两种知识迁移方式互为补充、相辅相成,共同提升多场景模型的预估能力。我们对比了不同模块的实验效果,具体结果如下表1所示。可以看出,引入场景知识迁移和特征权重优化在头部、尾部渠道都能带来一定提升,其中尾部小流量场景上(见下表1子场景2、3)有更为明显的提升,可见场景知识迁移缓解了场景之间的负迁移现象。

相关研究和实践表明[6][7][8],稀疏专家网络对于提高计算效率和增强模型效果非常有用。因此,我们在AKTN模型的基础上,在专家层进一步优化多场景模型。具体的,我们将场景知识迁移层替换为自动化稀疏专家选择方法,通过门控网络从大规模专家中选取与当前场景最相关的$K$个构成自适应场景表征,其选择过程如下图4所示:

在实践中,我们通过使用可微门控网络对专家进行有效组合,以避免不相关任务之间的负迁移现象。同时大规模专家网络的引入扩大了多场景模型的选择空间,更好地支持了门控网络的选择。考虑到多场景下的海量流量和复杂场景特征,在业界调研的基础上对稀疏专家门控网络进行了探索。
具体而言,我们对以下稀疏门控方法进行了实践:
- 方法一:通过$KL$散度衡量子场景与各专家之间的相似度,以此选择与当前场景最匹配的$k$个专家。在实现方式上,使用场景*专家的二维矩阵计算相似性,并通过$KL$散度选择出最适合的$k$个专家。
- 方法二:每个子场景配备一个专家选择门控网络,$m$个场景则有$m$个门控网络。对于每个场景的门控网络,配备$k$个单专家选择器[9],每个单专家选择器负责从$n$个专家中选择一个作为当前场景的专家($n$为Experts个数)。在实践中,为提高训练效率,我们对单专家选择器中权重较小的值进行截断,保证每个单专家选择器仅选择一个专家。
在离线实验中,我们以物料推荐渠道 * 展示形态作为场景定义,对上述稀疏门控方法进行了尝试,离线效果如下表2所示:

可以看出,基于软共享机制的专家聚合方法能够更好地通过所激活的相同专家网络对各场景之间的知识进行共享。相较于常见的以截断方式为主的门控网络,使用二进制编码的方式使得其在不损失其他专家网络信息的同时,能够更好地收敛到目标专家数量,同时其可微性使得其在以梯度为基础的优化算法中训练更加稳定。
同时,为了验证稀疏门控网络能否有效区分不同场景并捕捉到场景间差异性,我们使用$n$=16个专家中选择$K$=7个的例子,对验证集中不同场景下各专家的利用率、选择专家的平均权重进行了可视化分析(如图5-图7所示),实验结果表明该方法能够有效地选择出不同的专家对场景进行表达。
例如,图6中KP_1更多地选择第5个专家,而KP_2更倾向于选择第15个专家。并且,不同场景对各专家的使用率以及选择专家的平均权重也有着明显的差异性,表明该方法能够捕捉到细分场景下流量的差异性并进行差异化的表达。



实验证明,在通过大规模专家网络对每个场景进行建模的同时,基于软共享机制的专家聚合方法能够更好地通过所激活的相同专家网络对各场景之间的知识进行共享。 同时,为了进一步探索Experts个数对模型性能的影响,我们在方法二的基础上通过调整专家个数和topK比例设计了多组对比实验,实验结果如下表3所示:

从实验数据可以看出,大规模的Experts结构会带来正向的离线收益;并且随着选取专家个数比例的增加(表3横轴),模型整体的表现效果也有上升的趋势。
2.2 自适应场景聚合
理想情况下,一条请求(流量)可以看作一个独立的场景。但如引言所述,随着DSP业务持续发展,不同的物料展示渠道、形式、位置等持续增加,每个场景的数据十分稀疏,我们无法对每个细分场景进行有效训练。因此,我们需要对各个推荐场景进行聚类、合并。我们使用场景聚合的方法对此问题进行求解,通过衡量所有场景间的相似度,并最大化该相似度来指导场景的聚合,解决了数据稀疏导致难以收敛的问题。具体的,我们将该问题表示为:

其中$G$表示某种分组方式,$f_{s_i}$为场景$s_i$在分组$G_k$内与其他场景的总体相似度。在将$N$个场景聚合成$K$个场景组的过程中,我们需要找到使得场景间整体相似度最大的分组方式$G^{\ast}$。
因此,我们在2.1节场景知识迁移模型的基础上,增加了场景聚合部分,提出了基于Two-Stage策略进行训练的场景聚合模型:
- Stage 1:基于相似度衡量方法对各场景的相似度进行归纳,并以最大化分组场景的相似度为目标找到各场景的最优聚合方式(如Scene1与Scene 4可聚合为场景组合Scene Group SGA);
- Stage 2:基于Stage 1得到的场景聚合方式,以交叉熵损失为目标函数最小化各场景下的交叉熵损失。
其中,Stage 2与2.1节中所述一致,本节主要针对Stage 1进行阐述。我们认为,一个有效的场景聚合方法应该能自适应地应对流量变化的趋势,能够发现场景之间的内在联系并依据当前流量特点自动适配聚合方法。我们首先想到的是从规则出发,将人工先验知识作为场景聚合的依据,按照推荐渠道、展示形式以及两者叉乘的方式进行了相应迭代。然而这类场景聚合方式需要可靠的人工经验来支撑,且在应对海量流量时不能迅速捕捉到其中的变化。
因此,我们对场景之间关系的建模方法进行了相关的探索。首先,我们通过离线训练时场景之间的表征迁移和组合训练来评估场景之间的影响,但这种方式存在组合空间巨大、训练耗时较长的问题,效率较低。
在多任务的相关研究中[10][11][12][13],使用梯度信息对任务之间的关系进行建模是一种有效的方法。类似的在多场景模型中,能够根据各场景损失函数的梯度信息对场景间的相似度进行建模,因此我们采用多专家网络并基于梯度信息自动化地对场景之间的相似度进行求解,模型示意如下图8所示:

基于上述思路,我们对场景之间的关系建模方法进行了以下尝试:
1. Gradient Regulation
基于梯度信息能够对场景信息进行潜在表示这一认知,我们在损失函数中加入各场景损失函数关于专家层梯度距离的正则项,整体的损失函数如下所示,该正则项的系数$\lambda_{s_i,s_j}$表示场景之间的相似度,$dist$为常见的评估梯度之间距离的方法,比如$l_1$,$l_2$距离。

2. Lookahead Strategy

3. Meta Weights
Lookahead Strategy该方法对场景间的关系进行了显式建模,但是这种根据损失函数的变化计算场景相关系数的策略存在着训练不稳定、波动较大的现象,无法像Gradient Regulation这一方法对场景相似度进行求解。


我们以推荐渠道和展示形式(是否开屏)的多场景模型作为Base,对上述3种方法做了探索。为了提高训练效率,我们在设计 Stage 1 模型时做了以下优化:

我们对每个方法的GAUC进行了比较,实验效果如下表4所示。相较于人工规则,基于梯度的场景聚合方法都能带来效果的明显提升,表明损失函数梯度能在一定程度上表示场景之间的相似性,并指导多场景进行聚合。

为了更全面的展现场景聚合对于模型预估效果的影响,我们选取Meta Weights进行分组数量的调优实验,具体的实验结果如下表5所示。可以发现:随着分组数的增大,GAUC提升也越大,此时各场景间的负迁移效应减弱;但分组超过一定数量时,场景间总体的相似度减小,GAUC呈下降趋势。

此外,我们对Meta Weigts方法中部分场景间的关系进行了可视化分析,分析结果如下图9所示。以场景作为坐标轴,图中的每个方格表示各场景间的相似度,颜色的深浅表示渠道间的相似程度大小。

从图中可以发现,以渠道和展示形式为粒度的细分场景下,该方法能够学习到不同场景间的相关性,例如A渠道下的信息流(s16)与其他场景的相关性较低,会将其作为独立的场景进行预估,而B渠道下的开屏展示(s9)与C渠道开屏展示(s8)相关性较高,会将其聚合为一个场景进行预估,同时该相似度矩阵不是对称的,这也说明各场景间相互的影响存在着差异。
3 总结与展望
通过多场景学习的探索和实践,我们深入挖掘了推荐模型在不同场景下的建模能力,并分别从场景知识迁移、场景聚合方向进行了尝试和优化,这些尝试提供了更好的理解和解释推荐模型对不同类型流量和场景的应对能力。然而,这只是多场景学习研究的开始,后续我们会探索并迭代以下方向:
- 更好的场景划分方式:当前多场景的划分主要还是依据渠道(渠道*展示形态)作为流量的划分方式,未来会在媒体、展示位、媒体*时间等维度上进行更详细地探索;
- 端到端的流量聚合方式:在进行流量聚合时,使用了Two-Stage的策略进行聚合。然而,这种方式不能充分地利用流量数据中相关的信息。因此,需要探索端到端的流量场景聚合方案将更直接和有效地提高推荐模型的能力。
结合多场景学习,在未来的研究中将不断探索新的方法和技术,以提高推荐模型对不同场景和流量类型的建模能力,创造更好的用户体验以及商业价值。
4 作者简介
王驰、森杰、树立、文帅、尹华、肖雄等,均来自美团到家事业群/到家研发平台。
5 参考文献
- [1] STAR:Sheng, Xiang-Rong, et al. “One model to serve all: Star topology adaptive recommender for multi-domain ctr prediction.” Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021.
- [2] SAML:Chen, Yuting, et al. “Scenario-aware and Mutual-based approach for Multi-scenario Recommendation in E-Commerce.” 2020 International Conference on Data Mining Workshops (ICDMW). IEEE, 2020.
- [3] ADIN:Jiang, Yuchen, et al. “Adaptive Domain Interest Network for Multi-domain Recommendation.” Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
- [4]SASS:Zhang, Yuanliang, et al. “Scenario-Adaptive and Self-Supervised Model for Multi-Scenario Personalized Recommendation.” Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
- [5] Squeeze-and-Excitation:Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- [6] 美团外卖推荐情境化智能流量分发的实践与探索
- [7] PaLM:https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
- [8] GLaM:https://proceedings.mlr.press/v162/du22c.html
- [9] 单专家选择器:https://arxiv.org/abs/2106.03760
- [10] HOA:https://proceedings.mlr.press/v119/standley20a.html
- [11] Gradient Affinity:https://proceedings.neurips.cc/paper/2021/hash/e77910ebb93b511588557806310f78f1-Abstract.html
- [12] SRDML:https://dl.acm.org/doi/abs/10.1145/3534678.3539442
- [13] Auto-Lambda:https://arxiv.org/abs/2202.03091
- [14] MAML:https://arxiv.org/abs/1703.03400
如有侵权请联系:admin#unsafe.sh