2022-1-19 08:0:0 Author: github.security.telekom.com(查看原文) 阅读量:3 收藏
In order to improve and harden our group’s critical telco-infrastructure, Deutsche Telekom Security GmbH provides a red team to simulate real world attack scenarios. While our red team also offers its capabilities for external customers, our main focus is improving our internal security by simulating state of the art attacks.
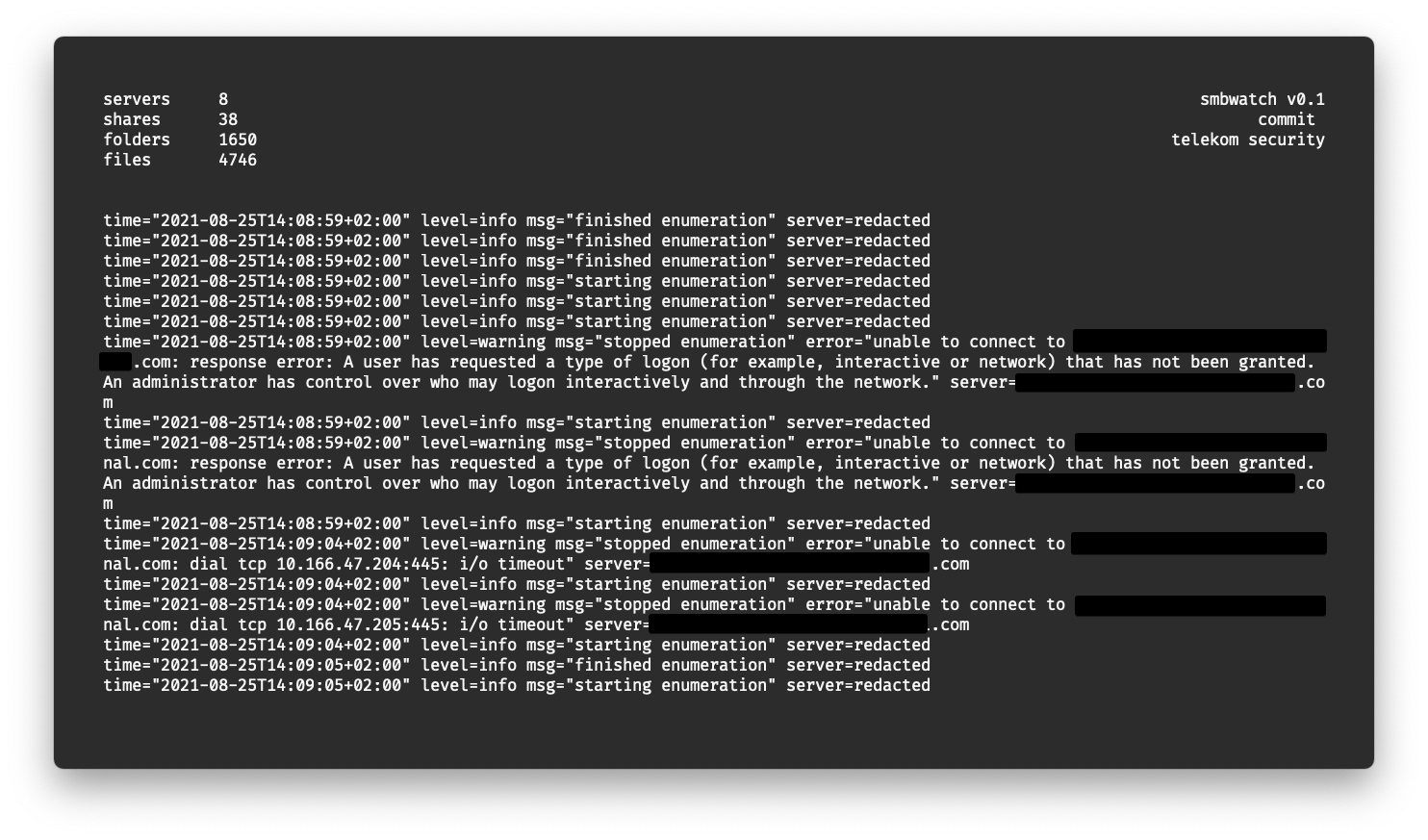
Some weeks ago we had a deeper look at Deutsche Telekom AG’s internal network, looking at a not-really-sophisticated attack vector: SMB shares. Over time, our network of fileservers has grown more and more to a huge list of shares, folders and files.
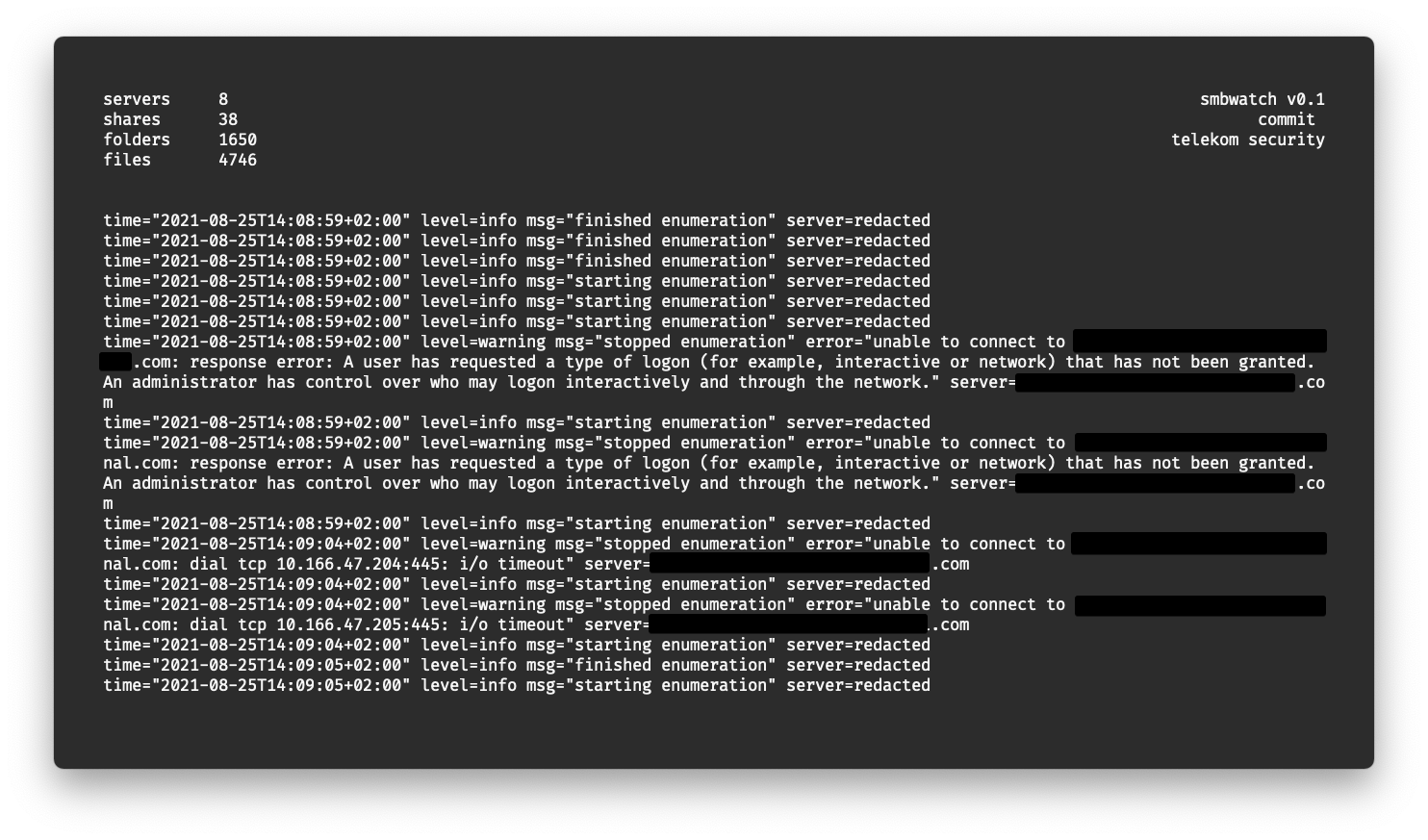
Some years ago we manually looked at promising targets and already found some interesting server backups. This time however, we decided to take a slightly more automated approach, using our own crawler to recursively index every folder and file we could find. To do this, we queried our internal LDAP server to get a list of all (SMB) servers, then concurrently indexed all files from it. The results were written to a sqlite database to ease querying and filtering.
The tool we wrote for this task is called smbwatch, which we just published
on github. smbwatch was written from scratch with concurrency in mind,
allowing to crawl multiple servers recursively at once. This was the only
viable option for us, having a huge network of shares and deep folder
structures. Some additional features which swmbwatch offers are:
- Query list of all servers from LDAP with
-ldap* - or enumerate a single share with
-server - Concurrency for fast retrieval, max. one connection per server
- Scans can be resumed (indexed shares are skipped)
- All shares, folders and files are persisted to a sqlite db
- Exclude specific shares by name
- Metrics and logs are shown in a TUI during scan
smbwatch is written in Go and compiled to a single binary, which also comes
in handy during other red team assessments to be run in a target network. Just
keep in mind that this will generate a lot of traffic.
Locating gems hidden deep in our fileservers
Playing with the final sqlite database revealed shocking data, distributed all over our network. We found complete server backups, (private) keys, configuration files, databases, emails, sourcecode, password lists (?!), and a lof of other interesting stuff. Simple SQL queries for size, extensions or keywords in the filename already resulted in a huge amount of files to look at. More data than we could even look into with the limited resources we had.
Adjusting our internal security process to prevent further leaks
So what did we learn from this? Our blue team did a thorough investigation of all shares and findings. A contact person for each of them was reached to clean up sensitive data and making the share only (internally) accessible if it is really needed (need-to-know). Additionally, an automated process was established, with the objective to close shares remotely. This may result in problems, but at least the responsible team will notice that there is a problem (the hard way).
We will still have a look at our shares from time to time with smbwatch and
closely monitor if the procedual changes will have a lasting effect and harden
our internal network.
smbwatch can be found here on github
Robin Verton ([email protected])
如有侵权请联系:admin#unsafe.sh