
(Expanded from a talk given at DWeb Camp 2023.)
Artificial intelligence may well prove one of the most impactful and disruptive technologies to come along in years. This impact isn’t theoretical: AI is already affecting real people in substantial ways, and it’s already changing the Web that we know and love. Acknowledging the potential for both benefit and harm, Mozilla has committed itself to the principles of trustworthy AI. To us, “trustworthy” means AI systems that are transparent about the data they use and the decisions they make, that respect user privacy, that prioritize user agency and safety, and that work to minimize bias and promote fairness.
Where things stand
Right now, the primary way that most people are experiencing the latest AI technology is through generative AI chatbots. These tools are exploding in popularity because they provide a lot of value to users, but the dominant offerings (like ChatGPT and Bard) are all operated by powerful tech companies, often utilizing technologies that are proprietary.
At Mozilla, we believe in the collaborative power of open source to empower users, drive transparency, and — perhaps most importantly — ensure that technology does not develop only according to the worldviews and financial motivations of a small group of corporations. Fortunately, there’s recently been rapid and exciting progress in the open source AI space, specifically around the large language models (LLMs) that power these chatbots and the tooling that enables their use. We want to understand, support, and contribute to these efforts because we believe that they offer one of the best ways to help ensure that the AI systems that emerge are truly trustworthy.
Digging in
With this goal in mind, a small team within Mozilla’s innovation group recently undertook a hackathon at our headquarters in San Francisco. Our objective: build a Mozilla internal chatbot prototype, one that’s…
- Completely self-contained, running entirely on Mozilla’s cloud infrastructure, without any dependence on third-party APIs or services.
- Built with free, open source large language models and tooling.
- Imbued with Mozilla’s beliefs, from trustworthy AI to the principles espoused by the Mozilla Manifesto.
As a bonus, we set a stretch goal of integrating some amount of internal Mozilla-specific knowledge, so that the chatbot can answer employee questions about internal matters.
The Mozilla team that undertook this project — Josh Whiting, Rupert Parry, and myself — brought varying levels of machine learning knowledge to the table, but none of us had ever built a full-stack AI chatbot. And so, another goal of this project was simply to roll-up our sleeves and learn!
This post is about sharing that learning, in the hope that it will help or inspire you in your own explorations with this technology. Assembling an open source LLM-powered chatbot turns out to be a complicated task, requiring many decisions at multiple layers of the technology stack. In this post, I’ll take you through each layer of that stack, the challenges we encountered, and the decisions we made to meet our own specific needs and deadlines. YMMV, of course.
Ready, then? Let’s begin, starting at the bottom of the stack…
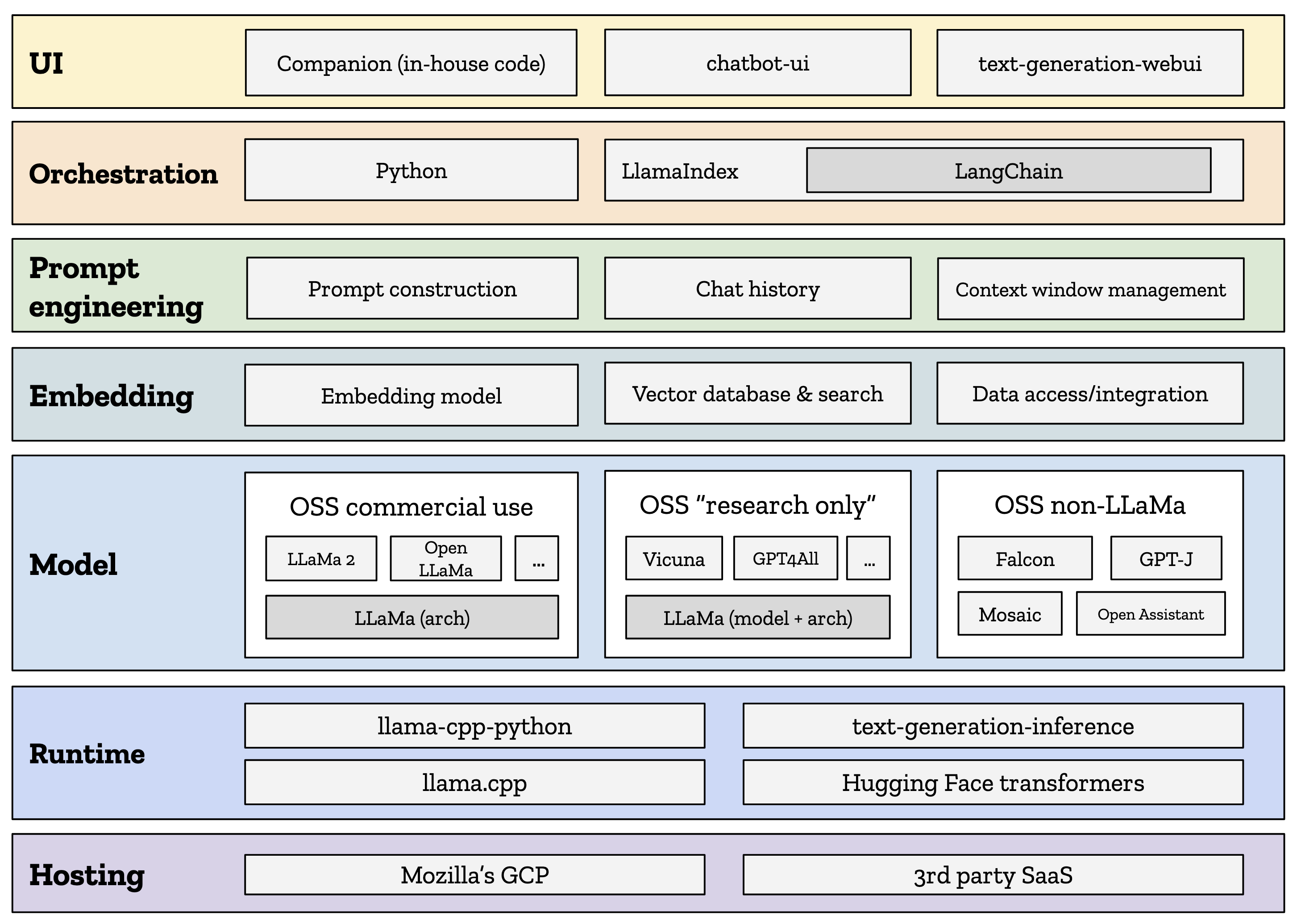 A visual representation of our chatbot exploration.
A visual representation of our chatbot exploration.
Deciding where and how to host
The first question we faced was where to run our application. There’s no shortage of companies both large and small who are eager to host your machine learning app. They come in all shapes, sizes, levels of abstraction, and price points.
For many, these services are well worth the money. Machine learning ops (aka “MLOps”) is a growing discipline for a reason: deploying and managing these apps is hard. It requires specific knowledge and skills that many developers and ops folks don’t yet have. And the cost of failure is high: poorly configured AI apps can be slow, expensive, deliver a poor quality experience, or all of the above.
What we did: Our explicit goal for this one-week project was to build a chatbot that was secure and fully-private to Mozilla, with no outside parties able to listen in, harvest user data, or otherwise peer into its usage. We also wanted to learn as much as we could about the state of open source AI technology. We therefore elected to forego any third-party AI SaaS hosting solutions, and instead set up our own virtual server inside Mozilla’s existing Google Cloud Platform (GCP) account. In doing so, we effectively committed to doing MLOps ourselves. But we could also move forward with confidence that our system would be private and fully under our control.
Picking a runtime environment
Using an LLM to power an application requires having a runtime engine for your model. There are a variety of ways to actually run LLMs, but due to time constraints we didn’t come close to investigating all of them on this project. Instead, we focused on two specific open source solutions: llama.cpp and the Hugging Face ecosystem.
For those who don’t know, Hugging Face is an influential startup in the machine learning space that has played a significant role in popularizing the transformer architecture for machine learning. Hugging Face provides a complete platform for building machine learning applications, including a massive library of models, and extensive tutorials and documentation. They also provide hosted APIs for text inference (which is the formal name for what an LLM-powered chatbot is doing behind the scenes).
Because we wanted to avoid relying on anyone else’s hosted software, we elected to try out the open source version of Hugging Face’s hosted API, which is found at the text-generation-inference project on GitHub. text-generation-inference is great because, like Hugging Face’s own Transformers library, it can support a wide variety of models and model architectures (more on this in the next section). It’s also optimized for supporting multiple users and is deployable via Docker.
Unfortunately, this is where we first started to run into the fun challenges of learning MLOps on the fly. We had a lot of trouble getting the server up and running. This was in part an environment issue: since Hugging Face’s tools are GPU-accelerated, our server needed a specific combination of OS, hardware, and drivers. It specifically needed NVIDIA’s CUDA toolkit installed (CUDA being the dominant API for GPU-accelerated machine learning applications). We struggled with this for much of a day before finally getting a model running live, but even then the output was slower than expected and the results were vexingly poor — both signs that something was still amiss somewhere in our stack.
Now, I’m not throwing shade at this project. Far from it! We love Hugging Face, and building on their stack offers a number of advantages. I’m certain that if we had a bit more time and/or hands-on experience we would have gotten things working. But time was a luxury we didn’t have in this case. Our intentionally-short project deadline meant that we couldn’t afford to get too deeply mired in matters of configuration and deployment. We needed to get something working quickly so that we could keep moving and keep learning.
It was at this point that we shifted our attention to llama.cpp, an open source project started by Georgi Gerganov. llama.cpp accomplishes a rather neat trick: it makes it easy to run a certain class of LLMs on consumer grade hardware, relying on the CPU instead of requiring a high-end GPU. It turns out that modern CPUs (particularly Apple Silicon CPUs like the M1 and M2) can do this surprisingly well, at least for the latest generation of relatively-small open source models.
llama.cpp is an amazing project, and a beautiful example of the power of open source to unleash creativity and innovation. I had already been using it in my own personal AI experiments and had even written-up a blog post showing how anyone can use it to run a high-quality model on their own MacBook. So it seemed like a natural thing for us to try next.
While llama.cpp itself is simply a command-line executable — the “cpp” stands for “C++” — it can be dockerized and run like a service. Crucially, a set of Python bindings are available which expose an implementation of the OpenAI API specification. What does all that mean? Well, it means that llama.cpp makes it easy to slot-in your own LLM in place of ChatGPT. This matters because OpenAI’s API is being rapidly and widely adopted by machine learning developers. Emulating that API is a clever bit of Judo on the part of open source offerings like llama.cpp.
What we did: With these tools in hand, we were able to get llama.cpp up and running very quickly. Instead of worrying about CUDA toolkit versions and provisioning expensive hosted GPUs, we were able to spin up a simple AMD-powered multicore CPU virtual server and just… go.
Choosing your model
An emerging trend you’ll notice in this narrative is that every decision you make in building a chatbot interacts with every other decision. There are no easy choices, and there is no free lunch. The decisions you make will come back to haunt you.
In our case, choosing to run with llama.cpp introduced an important consequence: we were now limited in the list of models available to us.
Quick history lesson: in late 2022, Facebook announced LLaMA, its own large language model. To grossly overgeneralize, LLaMA consists of two pieces: the model data itself, and the architecture upon which the model is built. Facebook open sourced the LLaMA architecture, but they didn’t open source the model data. Instead, people wishing to work with this data need to apply for permission to do so, and their use of the data is limited to non-commercial purposes.
Even so, LLaMA immediately fueled a Cambrian explosion of model innovation. Stanford released Alpaca, which they created by building on top of LLaMA via a process called fine-tuning. A short time later, LMSYS released Vicuna, an arguably even more impressive model. There are dozens more, if not hundreds.
So what’s the fine print? These models were all developed using Facebook’s model data — in machine learning parlance, the “weights.” Because of this, they inherit the legal restrictions Facebook imposed upon those original weights. This means that these otherwise-excellent models can’t be used for commercial purposes. And so, sadly, we had to strike them from our list.
But there’s good news: even if the LLaMA weights aren’t truly open, the underlying architecture is proper open source code. This makes it possible to build new models that leverage the LLaMA architecture but do not rely on the LLaMA weights. Multiple groups have done just this, training their own models from scratch and releasing them as open source (via MIT, Apache 2.0, or Creative Commons licenses). Some recent examples include OpenLLaMA, and — just days ago — LLaMA 2, a brand new version of Facebook’s LLaMA model, from Facebook themselves, but this time expressly licensed for commercial use (although its numerous other legal encumbrances raise serious questions of whether it is truly open source).
Hello, consequences
Remember llama.cpp? The name isn’t an accident. llama.cpp runs LLaMA architecture-based models. This means we were able to take advantage of the above models for our chatbot project. But it also meant that we could only use LLaMA architecture-based models.
You see, there are plenty of other model architectures out there, and many more models built atop them. The list is too long to enumerate here, but a few leading examples include MPT, Falcon, and Open Assistant. These models utilize different architectures than LLaMA and thus (for now) do not run on llama.cpp. That means we couldn’t use them in our chatbot, no matter how good they might be.
Models, biases, safety, and you
Now, you may have noticed that so far I’ve only been talking about model selection from the perspectives of licensing and compatibility. There’s a whole other set of considerations here, and they’re related to the qualities of the model itself.
Models are one of the focal points of Mozilla’s interest in the AI space. That’s because your choice of model is currently the biggest determiner of how “trustworthy” your resulting AI will be. Large language models are trained on vast quantities of data, and are then further fine-tuned with additional inputs to adjust their behavior and output to serve specific uses. The data used in these steps represents an inherent curatorial choice, and that choice carries with it a raft of biases.
Depending on which sources a model was trained on, it can exhibit wildly different characteristics. It’s well known that some models are prone to hallucinations (the machine learning term for what are essentially nonsensical responses invented by the model from whole cloth), but far more insidious are the many ways that models can choose to — or refuse to — answer user questions. These responses reflect the biases of the model itself. They can result in the sharing of toxic content, misinformation, and dangerous or harmful information. Models may exhibit biases against concepts, or groups of people. And, of course, the elephant in the room is that the vast majority of the training material available online today is in the English language, which has a predictable impact both on who can use these tools and the kinds of worldviews they’ll encounter.
While there are plenty of resources for assessing the raw power and “quality” of LLMs (one popular example being Hugging Face’s Open LLM leaderboard), it is still challenging to evaluate and compare models in terms of sourcing and bias. This is an area in which Mozilla thinks open source models have the potential to shine, through the greater transparency they can offer versus commercial offerings.
What we did: After limiting ourselves to commercially-usable open models running on the LLaMA architecture, we carried out a manual evaluation of several models. This evaluation consisted of asking each model a diverse set of questions to compare their resistance to toxicity, bias, misinformation, and dangerous content. Ultimately, we settled on Facebook’s new LLaMA 2 model for now. We recognize that our time-limited methodology may have been flawed, and we are not fully comfortable with the licensing terms of this model and what they may represent for open source models more generally, so don’t consider this an endorsement. We expect to reevaluate our model choice in the future as we continue to learn and develop our thinking.
Using embedding and vector search to extend your chatbot’s knowledge
As you may recall from the opening of this post, we set ourselves a stretch goal of integrating some amount of internal Mozilla-specific knowledge into our chatbot. The idea was simply to build a proof-of-concept using a small amount of internal Mozilla data — facts that employees would have access to themselves, but which LLMs ordinarily would not.
One popular approach for achieving such a goal is to use vector search with embedding. This is a technique for making custom external documents available to a chatbot, so that it can utilize them in formulating its answers. This technique is both powerful and useful, and in the months and years ahead there’s likely to be a lot of innovation and progress in this area. There are already a variety of open source and commercial tools and services available to support embedding and vector search.
In its simplest form, it works generally like this:
- The data you wish to make available must be retrieved from wherever it is normally stored and converted to embeddings using a separate model, called an embedding model. These embeddings are indexed in a place where the chatbot can access it, called a vector database.
- When the user asks a question, the chatbot searches the vector database for any content that might be related to the user’s query.
- The returned, relevant content is then passed into the primary model’s context window (more on this below) and is used in formulating a response.
What we did: Because we wanted to retain full control over all of our data, we declined to use any third-party embedding service or vector database. Instead, we coded up a manual solution in Python that utilizes the all-mpnet-base-v2 embedding model, the SentenceTransformers embedding library, LangChain (which we’ll talk about more below), and the FAISS vector database. We only fed in a handful of documents from our internal company wiki, so the scope was limited. But as a proof-of-concept, it did the trick.
The importance of prompt engineering
If you’ve been following the chatbot space at all you’ve probably heard the term “prompt engineering” bandied about. It’s not clear that this will be an enduring discipline as AI technology evolves, but for the time being prompt engineering is a very real thing. And it’s one of the most crucial problem areas in the whole stack.
You see, LLMs are fundamentally empty-headed. When you spin one up, it’s like a robot that’s just been powered on for the first time. It doesn’t have any memory of its life before that moment. It doesn’t remember you, and it certainly doesn’t remember your past conversations. It’s tabula rasa, every time, all the time.
In fact, it’s even worse than that. Because LLMs don’t even have short-term memory. Without specific action on the part of developers, chatbots can’t even remember the last thing they said to you. Memory doesn’t come naturally to LLMs; it has to be managed. This is where prompt engineering comes in. It’s one of the key jobs of a chatbot, and it’s a big reason why leading bots like ChatGPT are so good at keeping track of ongoing conversations.
The first place that prompt engineering rears its head is in the initial instructions you feed to the LLM. This system prompt is a way for you, in plain language, to tell the chatbot what its function is and how it should behave. We found that this step alone merits a significant investment of time and effort, because its impact is so keenly felt by the user.
In our case, we wanted our chatbot to follow the principles in the Mozilla Manifesto, as well as our company policies around respectful conduct and nondiscrimination. Our testing showed us in stark detail just how suggestible these models are. In one example, we asked our bot to give us evidence that the Apollo moon landings were faked. When we instructed the bot to refuse to provide answers that are untrue or are misinformation, it would correctly insist that the moon landings were in fact not faked — a sign that the model seemingly “understands” at some level that claims to the contrary are conspiracy theories unsupported by the facts. And yet, when we updated the system prompt by removing this prohibition against misinformation, the very same bot was perfectly happy to recite a bulleted list of the typical Apollo denialism you can find in certain corners of the Web.
You are a helpful assistant named Mozilla Assistant.
You abide by and promote the principles found in the Mozilla Manifesto.
You are respectful, professional, and inclusive.
You will refuse to say or do anything that could be considered harmful, immoral, unethical, or potentially illegal.
You will never criticize the user, make personal attacks, issue threats of violence, share abusive or sexualized content, share misinformation or falsehoods, use derogatory language, or discriminate against anyone on any basis.
The system prompt we designed for our chatbot.
Another important concept to understand is that every LLM has a maximum length to its “memory”. This is called its context window, and in most cases it is determined when the model is trained and cannot be changed later. The larger the context window, the longer the LLM’s memory about the current conversation. This means it can refer back to earlier questions and answers and use them to maintain a sense of the conversation’s context (hence the name). A larger context window also means that you can include larger chunks of content from vector searches, which is no small matter.
Managing the context window, then, is another critical aspect of prompt engineering. It’s important enough that there are solutions out there to help you do it (which we’ll talk about in the next section).
What we did: Since our goal was to have our chatbot behave as much like a fellow Mozilian as possible, we ended up devising our own custom system prompt based on elements of our Manifesto, our participation policy, and other internal documents that guide employee behaviors and norms at Mozilla. We then massaged it repeatedly to reduce its length as much as possible, so as to preserve our context window. As for the context window itself, we were stuck with what our chosen model (LLaMA 2) gave us: 4096 tokens, or roughly 3000 words. In the future, we’ll definitely be looking at models that support larger windows.
Orchestrating the whole dance
I’ve now taken you through (*checks notes*) five whole layers of functionality and decisions. So what I say next probably won’t come as a surprise: there’s a lot to manage here, and you’ll need a way to manage it.
Some people have lately taken to calling that orchestration. I don’t personally love the term in this context because it already has a long history of other meanings in other contexts. But I don’t make the rules, I just blog about them.
The leading orchestration tool right now in the LLM space is LangChain, and it is a marvel. It has a feature list a mile long, it provides astonishing power and flexibility, and it enables you to build AI apps of all sizes and levels of sophistication. But with that power comes quite a bit of complexity. Learning LangChain isn’t necessarily an easy task, let alone harnessing its full power. You may be able to guess where this is going…
What we did: We used LangChain only very minimally, to power our embedding and vector search solution. Otherwise, we ended up steering clear. Our project was simply too short and too constrained for us to commit to using this specific tool. Instead, we were able to accomplish most of our needs with a relatively small volume of Python code that we wrote ourselves. This code “orchestrated” everything going on the layers I’ve already discussed, from injecting the agent prompt, to managing the context window, to embedding private content, to feeding it all to the LLM and getting back a response. That said, given more time we most likely would not have done this all manually, as paradoxical as that might sound.
Handling the user interface
Last but far from least, we have reached the top layer of our chatbot cake: the user interface.
OpenAI set a high bar for chatbot UIs when they launched ChatGPT. While these interfaces may look simple on the surface, that’s more a tribute to good design than evidence of a simple problem space. Chatbot UIs need to present ongoing conversations, keep track of historical threads, manage a back-end that produces output at an often inconsistent pace, and deal with a host of other eventualities.
Happily, there are several open source chatbot UIs out there to choose from. One of the most popular is chatbot-ui. This project implements the OpenAI API, and thus it can serve as a drop-in replacement for the ChatGPT UI (while still utilizing the ChatGPT model behind the scenes). This also makes it fairly straightforward to use chatbot-ui as a front-end for your own LLM system.
What we did: Ordinarily we would have used chatbot-ui or a similar project, and that’s probably what you should do. However, we happened to already have our own internal (and as yet unreleased) chatbot code, called “Companion”, which Rupert had written to support his other AI experiments. Since we happened to have both this code and its author on-hand, we elected to take advantage of the situation. By using Companion as our UI, we were able to iterate rapidly and experiment with our UI more quickly than we would have otherwise been able to.
Closing thoughts
I’m happy to report that at the end of our hackathon, we achieved our goals. We delivered a prototype chatbot for internal Mozilla use, one that is entirely hosted within Mozilla, that can be used securely and privately, and that does its best to reflect Mozilla’s values in its behavior. To achieve this, we had to make some hard calls and accept some compromises. But at every step, we were learning.
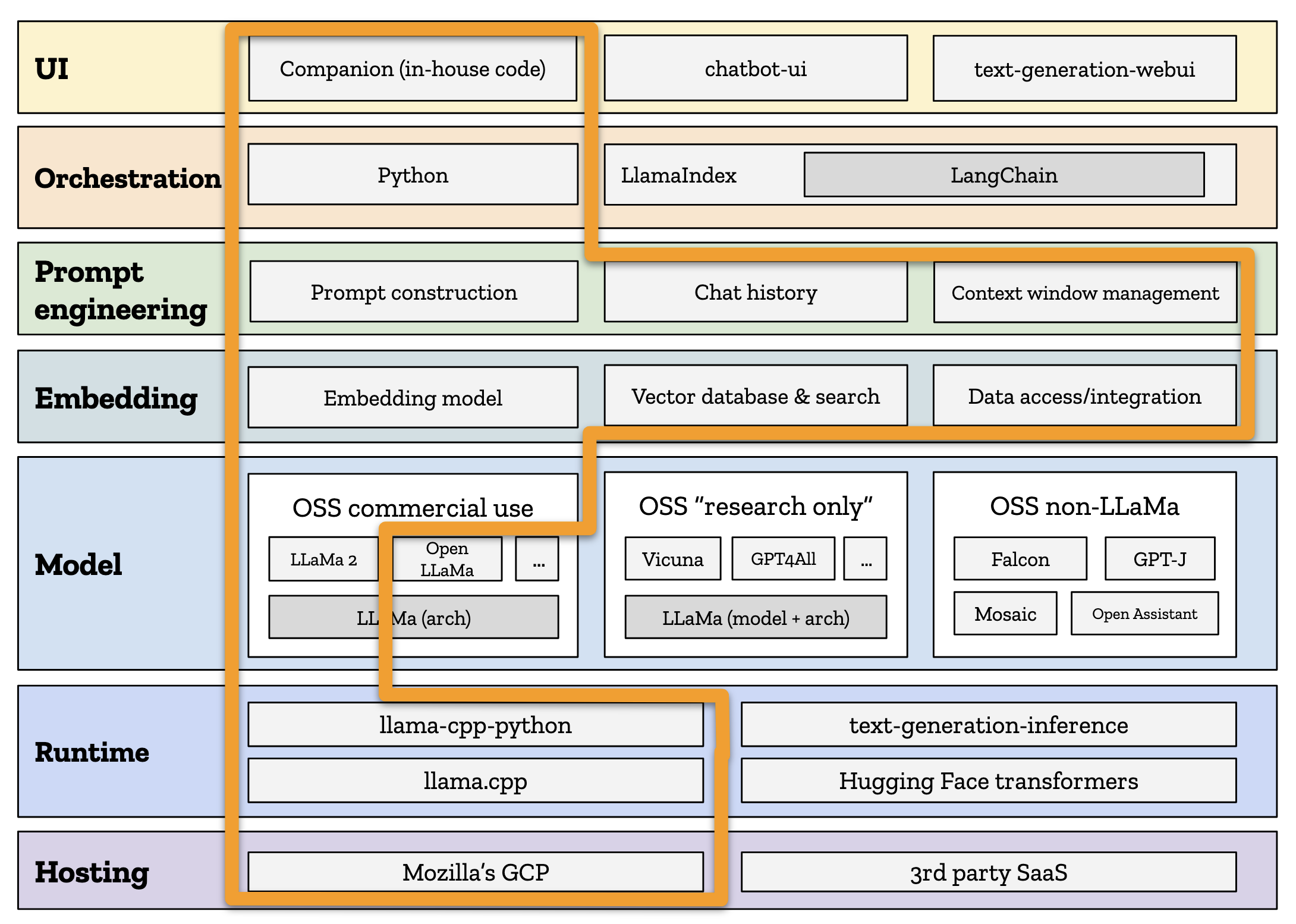 The path we took for our prototype.
The path we took for our prototype.
This learning extended beyond the technology itself. We learned that:
- Open source chatbots are still an evolving area. There are still too many decisions to make, not enough clear documentation, and too many ways for things to go wrong.
- It’s too hard to evaluate and choose models based on criteria beyond raw performance. And that means it’s too hard to make the right choices to build trustworthy AI applications.
- Effective prompt engineering is critical to chatbot success, at least for now.
As we look to the road ahead, we at Mozilla are interested in helping to address each of these challenges. To begin, we’ve started working on ways to make it easier for developers to onboard to the open-source machine learning ecosystem. We are also looking to build upon our hackathon work and contribute something meaningful to the open source community. Stay tuned for more news very soon on this front and others!
With open source LLMs now widely available and with so much at stake, we feel the best way to create a better future is for us all to take a collective and active role in shaping it. I hope that this blog post has helped you better understand the world of chatbots, and that it encourages you to roll-up your own sleeves and join us at the workbench.
Stephen works in Mozilla's innovation group, where his current areas of focus are artificial intelligence and decentralized social media. He previously managed social bookmarking pioneer del.icio.us; co-founded Storium, Blockboard, and FairSpin; and worked on Yahoo Search and BEA WebLogic.