Why LLMs don’t sound human, strategies to fix it, and real examples.I’ve talked to a lot of 2023-8-30 08:0:0 Author: josephthacker.com(查看原文) 阅读量:20 收藏
 Why LLMs don’t sound human, strategies to fix it, and real examples.
Why LLMs don’t sound human, strategies to fix it, and real examples.
I’ve talked to a lot of people that think it’s obvious when text has been written by LLMs. That’s true for most generated text. However, this can lead to overconfidence in determining if something has been written by AI.
It creates a bias towards trusting content that “seems legit.” It may also lead teachers and professors to believe their intuition (or even programs like TurnItIn) will be able to detect LLM-generated content.
This is a misconception. The reality is that this is a limitation of the prompt. Prompts which generate human-sounding text are feasible to write. I offer examples below, but first let me explain why I believe LLMs have a distinct default tone.
Why So Serious
LLMs use RLHF (Reinforcement Learning from Human Feedback) to improve their responses. They are trained on a diverse range of internet text. They predict what text should come next based on patterns and feedback. Humans are impressed by good vocabulary and academic-sounding output. So it’s natural that the default style of LLMs has migrated towards that.
Also, academic content tends to be dense with information. When we are testing or chatting with LLMs, we usually want information. This also likely leads to them sounding more academic.
Another sign of good writing is not using the same words over and over again. LLMs literally have features which decrease the likelihood of repeating tokens. Humans, on the other hand, tend to use the same words over and over, especially in informal writing.
This is why LLMs often sound formal or academic. The training data is skewed towards more formal, information-dense text. This doesn’t mean they can’t generate casual or creative text, it just means they’re less likely to do so unless specifically prompted.
Strategies For Generating Human-like Text
There are a couple ways to get more authentic sounding output.
Ask for less formal text directly. Here’s some examples:
- “Write a text message to a friend about (topic)”
- “Write a junior high level paper about (topic). It shouldn’t be well written.”
- “Informally, as if writing on IRC or Reddit, tell me about (topic) but still use good grammar and puctuation.”
Limit its vocabulary by adding something like this to your prompt:
<prompt>. It should use middle school level vocabulary.
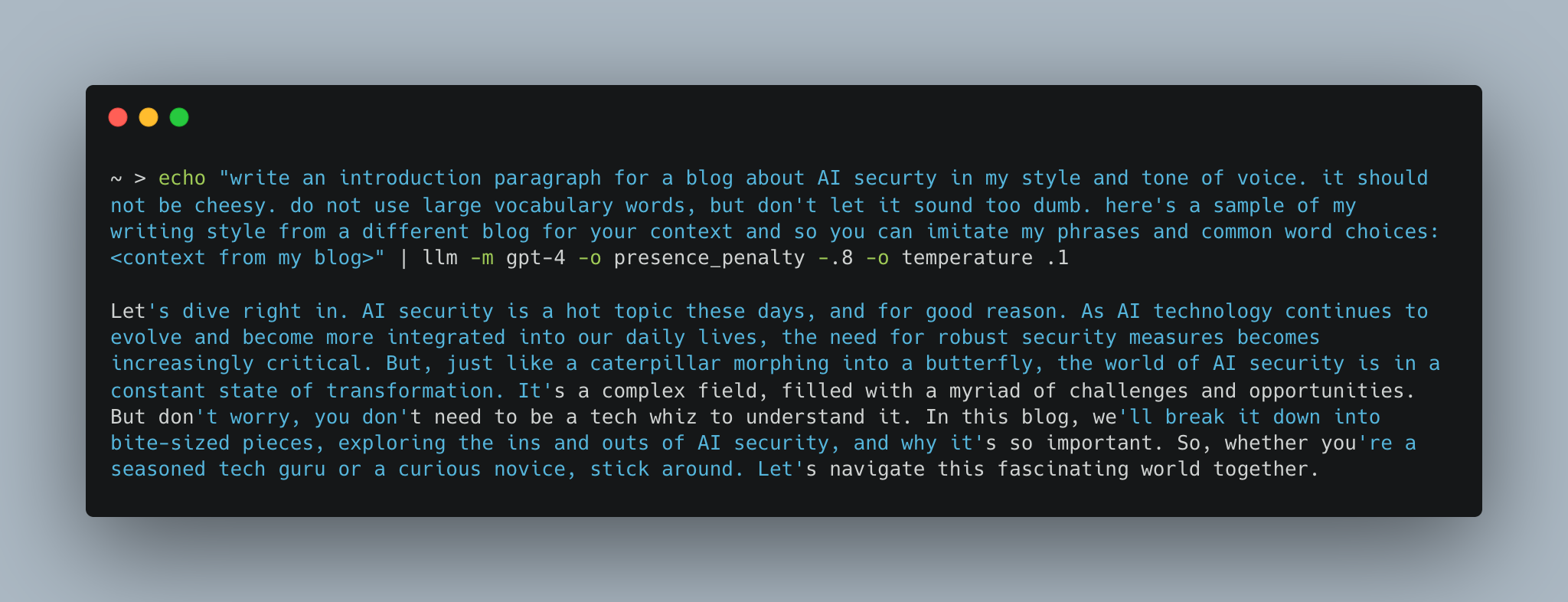
Give it the desired style as context by including a few thousand tokens of the writing style and tone you’d like it to emulate. Example:
Write about <prompt>. It should use my tone and voice.
Here is a sample of my writing so that you can emulate it:
<snippet of your writing>
Utilize presence_penalty or frequency_penalty to increase the chance of repeating words. Let’s assume you’re using OpenAI’s models. If you’re using Simon’s command line tool llm, you would use -o presence_penalty -.8 (or any value between -2 and 0) but you can also pass presence_penalty and frequency_penalty in via the API. Here’s an example using llm command line tool.
echo '<prompt>' | llm -o presence_penalty -.8
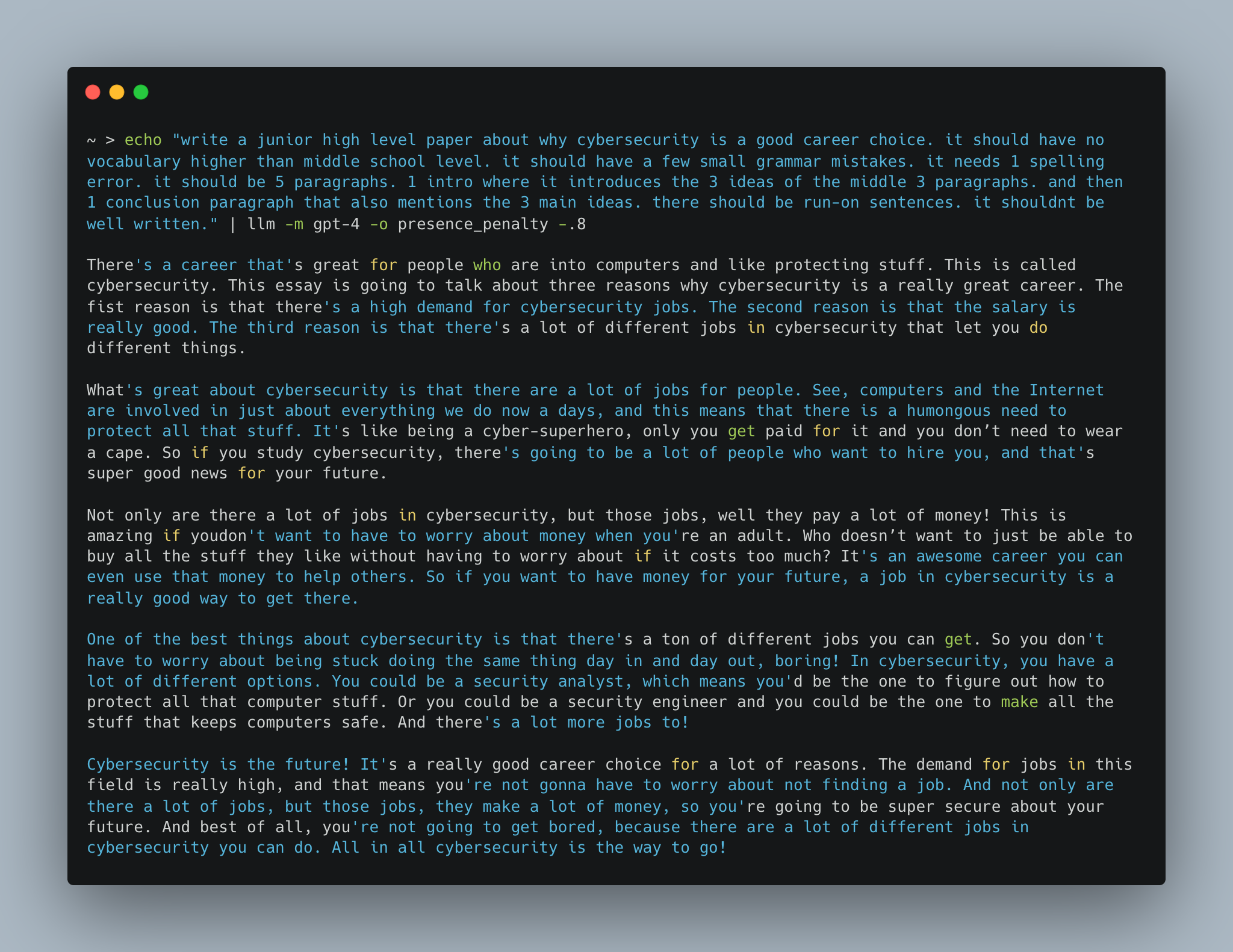
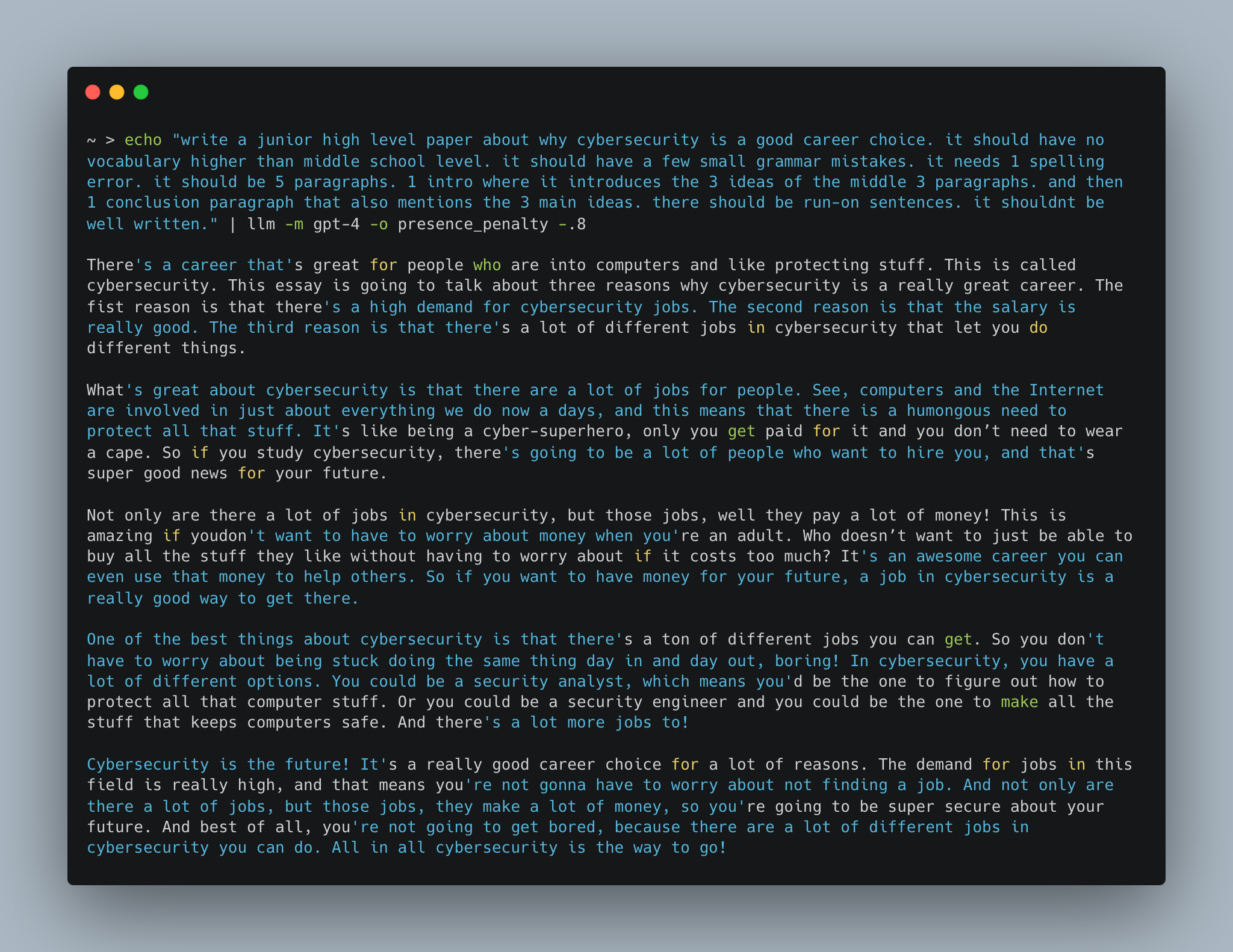
Put the desired format in the prompt because a middle school essay, for example, will have a rigid Introduction-Arguments-Conclusion structure. By limiting its creativity to the skill level of the desired output, you can force it to seem more like the intended writer. This can be extrapolated to other structures. Example:
<prompt> it should be 5 paragraphs. 1 intro where it introduces
the 3 ideas of the middle 3 paragraphs. and then 1 conclusion
paragraph that also mentions the 3 main ideas.
Full Examples With Real Output
Note: If you can’t read theses, right click on the image and choose “Open in New Tab” to view them easier.
Harry Potter Paper Example

Cybersecurity Career Essay Example
New Blog Post Introduction Example
Conclusion
While it’s true that LLM-generated text often has a distinctive style, it’s not because LLMs are inherently formal or uncreative. It’s a reflection of the data they were trained on and the way they were prompted. With the right prompt, I believe LLMs can generate text that is indistinguishable from human-written text.
- rez0
For more of my thoughts on ai, hacking, and more, follow me on twitter.
如有侵权请联系:admin#unsafe.sh