2023-8-31 11:51:0 Author: reusablesec.blogspot.com(查看原文) 阅读量:5 收藏

I want to know1
and understand1
But I will not1
-- Hashes cracked from the KoreLogic CMIYC 2023 competition
In the previous two posts on the CMIYC competition [Part 1, Part 2], I had focused on how to integrate data science tools into your password cracking workflow and showed how to crack passwords on limited hardware (E.g. my laptop without using a GPU). Of course it's better to have some firepower to crack hashes! One of the hurdles to overcome is I don't have a lot of firepower at my disposal. Despite being super interested (OK, obsessed) about password cracking, I've never invested in a dedicated cracking rig. Still, when I do get serious about cracking passwords I turn to Hashcat and GPU based attacks to do the heavy lifting even if I only have a single NVIDIA GeForce GTX 1070 GPU. That's still significantly faster than trying to run CPU only attacks.
To that end, let's talk about how to leverage Hashcat when competing in these competitions. Full disclaimer: I'm going to go full spoiler in how I'm approaching my cracking. At this point, I've been running cracking sessions way longer than the competition would have lasted if I had competed. Also, I've been on the various Discord and Twitter conversations about the contest this year and know how the hashes were generated. Heck, KoreLogic even posted themselves how they created the challenges [Full Spoiler Link]. So I'm not going to even pretend that this post represents how I would have done. Instead I want to focus on "given what we know, how can someone use Hashcat to crack those hashes".
Using Hashcat and John the Ripper Together
One issue that pops up a lot for me when using both John the Ripper and Hashcat to crack hashes, is that while their file formats are *mostly* the same, they are not directly compatible. This goes for how these tools expect hashes to be formatted when loading them up, and their .pot file formats they save their cracked passwords to.
The hash format in particular has been a long source of annoyance for me, and writing this blog post inspired me to finally submit a github issue about it to the hashcat repo. The long story short is that John the Ripper uses hash type identifies that Hashcat doesn't recognize. For example, here is a raw-md5 hash (from the CMIYC2023 contest) that John the Ripper can load:
- jithakur:$dynamic_0$38bb03886dd4fbda5a780f0617847e4c
And here is the same hash format that Hashcat expects:
- jithakur:38bb03886dd4fbda5a780f0617847e4c
Side note, while you can have usernames in your hash lists, Hashcat won't load the hashes unless you include the "--username" flag on the command line telling Hashcat to strip/ignore those usernames. E.g.:
- hashcat --username -a 0 -m 0 hashfile.txt dictionary.txt
What this really means is that to support both John the Ripper and Hashcat, I now have two sets of hash lists and two sets of pot files. It would be nice to incorporate some scripts in my Juypter Notebook to sync up both of the pot files between them so I'm not cracking the same hashed password twice. Given that's a rabbit hole which would totally side-track any hash cracking, I'm going to push that project off for another day. For now I'm just going to use Hashcat, and I modified my Notebook to support the Hashcat file formats, (mostly by copying and pasting the JtR code into another cell and then making small modifications). Once again, this is one of the super-powers of using Jupyter notebooks. I can load up my JtR cracked hashes, then write and load up my Hashcat plaintexts, and perform analysis on both in a very short period of time. It's not pretty but it works.
Running Basic Hashcat Attacks
The commands to run Hashcat are very different than those to run John the Ripper. There's pros and cons to both methods. File autocomplete works much better with Hashcat's command line and Hashcat does directory inclusion (such as use all wordlists in a directory) better. But John the Ripper's is less position dependent, has a ton of super powerful features for different attack modes on the command line, and quite honestly I'm just used to it more.
The basic command line for hashcat is:
- hashcat -a ATTACK_TYPE -m HASH_TYPE HASH_LIST [ATTACK_OPTIONS]
So for a standard wordlist + rules attack you can run
- hashcat -a 0 -m 0 uncracked_hashes.txt ../../wordlists/Alter-Hacker_Sorted-Cleaned.txt -r ../../repos/hashcat/rules/d3ad0ne.rule
To break this down:
- -a 0: The attack mode. In this case, wordlist + rules. Also supports stdin input if a wordlist is not specified
- -m 0: The hash type to crack. In this case it is targeting Raw-MD5 hashes
- uncracked_hashes.txt: The list containing all the hashes I want to crack. Hashcat will load everything that looks like a MD5 hash from it.
- ./../wordlists/Alter-Hacker_Sorted-Cleaned.txt: A common password cracking dictionary/wordlist.
- It's one of the bigger wordlists that is not based on pure cracked hashes which isn't 100% filled with junk. It used to be pretty easy to find online. But now that I'm looking for it again most of the links have dried up.
- Side note: It used to be hosted on KoreLogic's dictionary list available here. Also, I forgot they hosted a ton of wordlists. I need to check them out again to see if they are helpful in this competition. (Spoiler, these dictionaries were not that helpful).
- -r ../../repos/hashcat/rules/d3ad0ne.rule: The mangling rules. d3ad0ne.rule is a pretty decent set to use if you can make a lot of guesses
Running variations of the above attack using standard large dictionaries and a few other hashcat rules cracked a few more MD5 passwords but not many....
One cool feature of Hashcat is that you can specify a directory instead of a wordlist though. So you can use the following command to run a quick set of mangling rules against all of your dictionaries:
- hashcat -a 0 -m 0 uncracked_hashes.txt ../../wordlists/ -r ../../repos/hashcat/rules/best66.rule
When running these attacks, the hashes.org-20202 wordlist did the best. It's a super effective wordlist to use in general and can be obtained from hashmob [link]. Side note, I'm not using Hashmob's own cracked wordlists for this blog post since I'm pretty sure the contest hashes were uploaded to them.
Given the limited success of these attacks (a few raw-MD5 cracks aren't going to give a lot of points). There's really three paths that I can take.
- I can analyze the cracks and try to construct custom attacks.
- THIS IS THE BEST OPTION.
- I can run my existing wordlists but have Hashcat auto-generate rules for me
- I can start brute-forcing key-spaces with smart masks and Markov attacks.
Side note: Options #2 and #3 are generally the ones picked on real dumps as the individual passwords are only loosely related to each other. Also password crackers (at least me) are lazy.
Going with the lazy options first, let's dive in on how to run them. To auto-generate rules you can use the --generate-rules=X option where X is the number of rules to generate. For example:
- hashcat -a 0 -m 0 --debug-mode=5 --debug-file debug.txt --generate-rules=1000000 uncracked_hashes.txt ../../wordlists/hashes.org-2020.txt
When you do this, and I can't stress this enough, enable --debug-mode=5. Also log that info to file using the --debug-file debug.txt option. This will output both the rule that successfully cracks as password as well as the plain-text word. Don't get lazy, and do not skip this option. In fact, you probably should be running that for all your password cracking sessions.
Now you may be asking yourself, why "--debug-mode=5"? It's because the debug info will append itself to the debug-file (vs. overwrite it) and you'll be running a lot of cracking sessions. Going back and remembering which dictionary created which cracked password is super helpful. You want all that info. Why throw that info away with a lower debugging option?

Long story short, if you don't know what to do, a default option can be to generate rules for a dictionary you've had some success with, log the results, and then turn the successful rules into a contest specific ruleset to use with other dictionaries.
But what if your input dictionaries are the problem? That's where brute-forcing small key lengths can be helpful using masks.
Cracking Contest Hashes with Hashcat Masks
I'll admit, I started to go into a long, long diversion about the mechanics behind Hashcat's Masks and Markov optimizations. I really hate calling what Hashcat does a Markov attack and there's a ton of optimizations that Hashcat developers can make to it. But that's totally besides the point if you are trying to crack passwords RIGHT NOW. So I'll save that side tangent for a different post and instead focus on cracking these contest hashes.
Masks are one area where having more computational power makes a huge difference. They let serious cracking rigs just chew through keyspace without requiring much skill or ability from their operators. Contest organizers know this and tend to create passwords that are resistant to un-optimized mask attacks. This means going through the entire key-space for 5/6/7/8 passwords is unlikely to be very successful.
- (Not recommended): hashcat -a 3 -m 0 hash_list.txt ?a?a?a?a?a?a?a
As an example of that, I left Hashcat running for a couple of hours brute forcing all ASCII passwords of length 1 through 7 for the raw-MD5 hashes. I didn't crack a single new hash that wasn't caught by earlier runs I had performed with John the Ripper. Going back to my Jupyter Notebook I decided to display password cracks by length, and then also the number of ASCII only (aka no Cyrillic) password cracked by length.

You probably don't have the GPU power to brute force 8-9 character passwords during the contest, and you certainly don't have that for the high value hashes that are worth a lot of points Therefore to be successful in a contest with Hashcat Masks you need to tailor them to find gaps in base-words or mangling-rules that you have already identified. I talked about this earlier with the attacks I ran using John the Ripper in Part 2 of these write-ups. For example, if you were looking to find more base-words for Sales passwords where many of them started with '2023' and ended with a special character, then you could try something like:
- hashcat -a 3 -m 0 -1 ?l?u -2 cmiyc_sales_end.hcchr uncracked_hashes.txt 2023?1?l?l?l?l?l?l?2
There's a lot going on in the above command. Let's break this command down by parts:
- hashcat -a 3 -m 0
- The standard hashcat command targeting raw-md5 hashes (-m 0), and using mask mode (-a 3)
- -1 ?l?u
- I'm setting a custom mask character set here that includes two built in character sets [?l = all lowercase letters, and ?u = ALL UPPERCASE LETTERS]
- In the actual mask you can refer to this custom character set as ?1 (that's the number 1)
- You can specify up to 4 custom characters sets for your mask mode [1 - 4]. This is a hard limit. I wish you could do more actually, but that's how Hashcat is programmed.
- -2 cmiyc_sales_end.hcchr
- Rather than type out the characters for the mask on the command line, you can also save them to a *.hcchr file and read them in.
- This is super helpful when you are targeting special characters that just don't play well on the command line and you don't want to mess with escaping them. For example '!,$.
- The format for .hcchr files is just all the characters you want to target on the first line. E.g.:
- !,$
- uncracked_hashes.txt
- Once again, just the hash-list of the hashes you are targeting
- 2023?1?l?l?l?l?l?l?2
- The actual mask to run. Breaking it down further
- 2023: Simply starts every guess with the string "2023"
- ?1: Use the first custom character set. I know, it's hard to see the difference between the number 1 and the letter l. The above uses the number one. In this case it tries all lower and uppercase letters.
- ?l?l?l?l?l?l: Try 6 lower case characters
- ?2: Try the second custom character set. This appends common special characters I found when cracking other sales passwords.
That's great, but what if you want to try 5 lower case characters vs. 6. Running these attacks by hand is a pain so it's nice to queue up a bunch of mask attacks at once using a save mask file (e.g. a .hcmask file). Unfortunately, the format is a bit different so let's look at how we can do that next. First, here is the hashcat command line to run a .hcmask file:
- hashcat -a 3 -m 0 uncracked_hashes.txt sales.hcmask
You'll notice that all the mask info has been removed from the command line and instead I'm calling an external sales.hcmask file. Let's take a look at what's in that file:
- ?l?u,!\,$,2023?1?l?l?l?2
- ?l?u,!\,$,2023?1?l?l?l?l?2
- ?l?u,!\,$,2023?1?l?l?l?l?l?2
- ?l?u,!\,$,2023?1?l?l?l?l?l?l?2
- ?l?u,!\,$,2022?1?l?l?l?2
- ?l?u,!\,$,2022?1?l?l?l?l?2
- ?l?u,!\,$,2022?1?l?l?l?l?l?2
- ?l?u,!\,$,2022?1?l?l?l?l?l?l?2
Breaking this file format down:
- Each line defines a single mask to run. Lines starting with '#' are comments.
- Each line will be run in order. Generally it helps to put the quick masks first so if you decide to cancel the job you have a better idea of how much key-space you checked.
- I know, I didn't follow my own advice in this example...
- Each line must define any custom character sets, and unlike with the command line you can't define them in external files.
- Each custom character set (up to 4) are specified by putting a comma ',' after them.
- In the above example this means the 2 custom character sets are:
- ?l?u
- !\,$
- For the second custom character set I wanted to include a comma, which is a problem because it's a deliminator. So I needed to escape it with a backslash. Aka: '\,'
- You can read more about the hcmask file format here.
With all of that, I managed to identify a couple more base words to use targeting sales passwords. This in turn allowed me to target higher value hashes easier. The same can be done by targeting known words to find the mangling rules. E.g.:
- ?d?s,2022Sales?1?1?1
Yes you can also do that with a wordlist and mangling rules, but if you only have a couple of words you want to check it can sometimes be easier to do that with Masks instead. Now if you have a lot of words you want to try, then you can look into Hashcat's "-a 6" (Wordlist + Mask) and "-a 7" (Mask + Wordlist) attack modes. John the Ripper doesn't have this specifically because *cough cough* its rule preprocessor supports masks already in its normal mangling rules. But these attack modes can be very helpful if you are using Hashcat.
One thing you'll notice though with the hybrid -a [6/7] attacks is that you can't mangle or apply masks to both sides of a guess at the same time. Also, unlike with standard wordlist modes (-a 0) you can not pipe a wordlist in to -a [6/7] modes via stdin. This is a problem. The whole reason you are using Masks is probably because you don't know what mangling rules have been applied to the base-word.
The key then is to create custom word-lists that contain one side of the mangling rules. I'd recommend picking the "shorter" of the mangling rules to limit how much you write to disk. This is super annoying, but it works. So for example if you want to append 2022 and 2023 to a word and then append a mask attack you could do something like first creating a word-list containing all the words with 2022 and 2023 appended to them (this only doubles the size of the original input dictionary). In this case I'm accomplishing this by using Hashcat's rules and saving the results to disk. To do that, and the run the resulting full Mask attack, you can use the following commands:
Rule file: append_year.rule (Capitalize word and prepend 2022 and 2023).
- c^2^2^0^2
- c^3^2^0^2
Generate wordlist command:
- hashcat -a 0 --stdout ./sales_words.txt -r append_year.rule
Now that we have a wordlist containing words like 2023Sales, run the mask hybrid attack:
- hashcat -a 6 -m 0 -1 ?l?u uncracked_hashes.txt ./sales_words.txt '?1?1?1
Is all of this a pain? Absolutely! But it can be very effective so it's usually worth creating these temporary wordlists for your attacks and then combine them with masks.
Hashcat Association Attacks (Getting Big Points with BCrypt)
As mentioned earlier, the whole reason to try different "spray and pray" attacks against fast hashes is to crack enough to identify how the passwords were created and develop highly targeted attacks against expensive and high value hashes like BCrypt. The mangling rule that received the most post-contest conversation among all of the teams was that several users' passwords were their creation time (found in their metadata) converted to Unix epoch timestamps.

Creating a wordlist of all the various timestamps is certainly one way to go, but what we really want to do is crack bcrypt hashes. This is a perfect opportunity to talk about association (-a 9) attacks in Hashcat. Association attacks take one word per hash and target that hash with it. The word in association attacks can be combined with rules as well. This is a huge improvement when targeting a large number of salted hashes where you may have some idea what the plaintext for each account might be.
To perform an association attack you need to create a hashlist of the hashes you want to target, and then have a 1 to 1 mapping to a wordlist you want to target those hashes with. So for example you might have two files:
HashList.txt:
- user1:$2a$:<rest of the hash here>
- user2:$2a$:<rest of the hash here>
- user3:$2a$:<rest of the hash here>
Wordlist.txt:
- Word1
- Word2
- Word3
For this particular challenge I created the wordlists + uncracked bcrypt hashlist using the following python script in Jupyter Notebook:

Next, let's run some attacks. First, let's just do a quick naïve attack using (-a 0) and the timestamps as a normal wordlist.

Running this attack for an hour and a half isn't the end of the world. But this is a contest. You are a busy hacker. You have hashes to crack and other wordlists to run. Let's try Hashcat's association attack. Here is the command I ran:
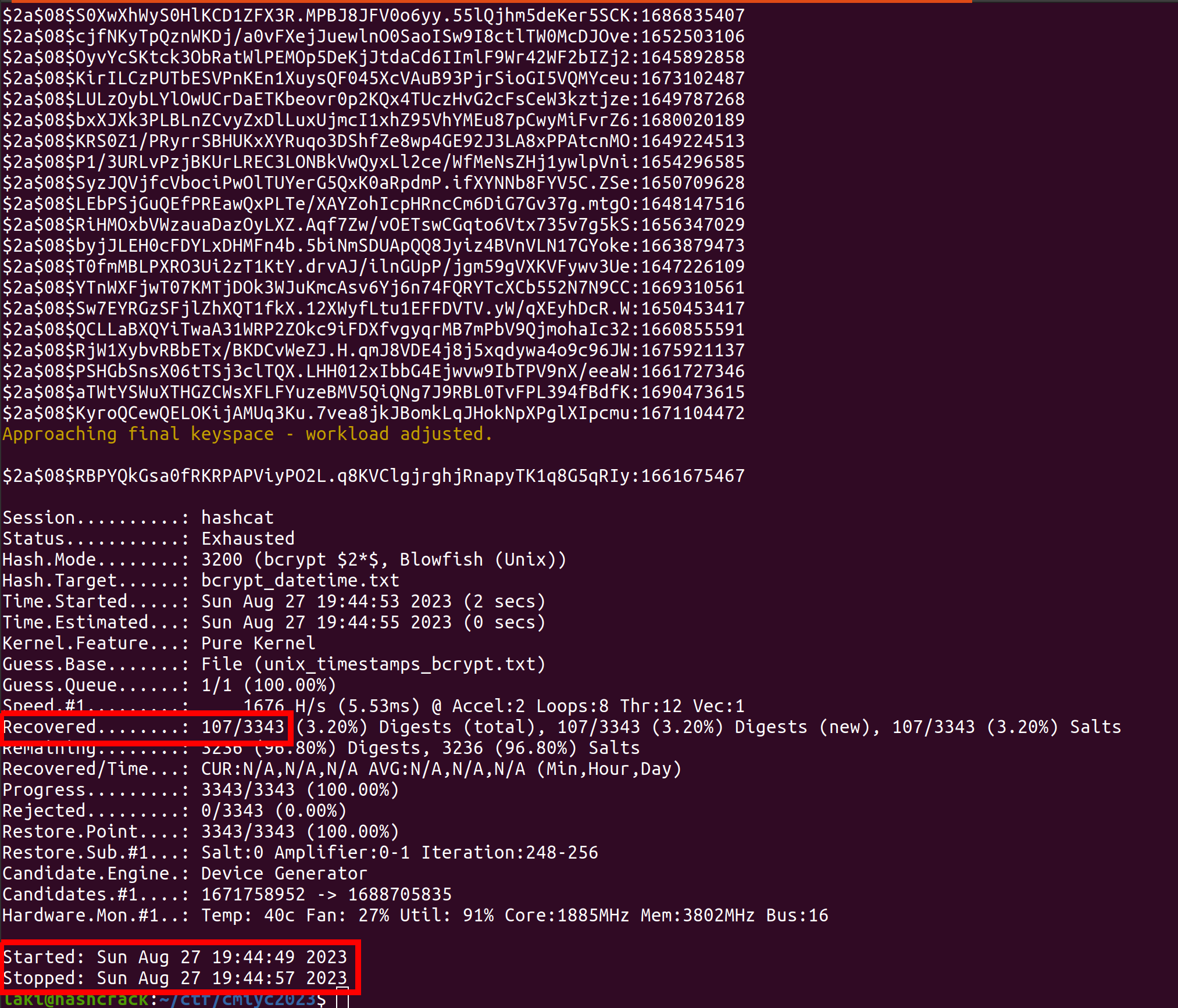
- hashcat -o cmiyc2023_hc.potfile -a 9 -m 3200 bcrypt_datetime.txt unix_timestamps_bcrypt.txt
ONE IMPORTANT THING TO KNOW: By default '-a 9' mode will not save to your standard .potfile. So if you want to capture these hashes you MUST specify a potfile on the command line using the '-o FILENAME' option. I learned this fact the hard way when none of my cracks were showing up. I asked some Hashcat developers about this and they said there's still some "weirdness" with '-a 9' mode. For example, it will "recrack" hashes you have already cracked and post duplicates cracks/plaintexts to your potfile. So if you are running this attack it is probably good to run it on a new potfile vs. your global one, and then merge the new cracks back into your main potfile after the fact.
And here's the results:

Over 100 Bcrypt hashes cracked in a couple of seconds! That's super fun. As some backstory, association attacks are amazing if you have known passwords for users. Aka you obtained passwords from a different password dump and you are attacking the fact that users re-use password between multiple sites. Leveraging association attacks, you can run common mangling attacks against those known passwords to crack computationally expensive hashes for a subset of users.
Cracking Multi-Words With Hashcat
The next area to focus on is multi-words and phrases. Korelogic gave out a hint during the contest that several of the Engineering passwords were created from phrases taken from sci-fi books and movies, with the number '1' appended on the end [Link]. This can be seen in some of the cracks I made earlier:

Going back to the hash breakdown by department, Engineering is also a huge department to target:

The approach here then is to crack as many hashes as possible with fast hashing algorithms to try and figure out the source materials. Then we need to target high-value hashes in the engineering department using phrases from those source materials. Basically dumb, untargeted attacks first, then smart attacks later. Let's start with those dumb untargeted attacks!
At a high level this looks like a Correct Hose Battery Staple problem. To target that, let's try all the common English words in two and three word phrases and add the number '1' to the end. For a dictionary we can use the following corpus which contains various word-lists of 10k English words sorted in probability order [Link]. The first really "just get it to work" option I selected was to write a quick python program that loops through the word-list and outputs possible phrases while appending the number 1 to them. I then used the fact that if you do not specify a dictionary, Hashcat's '-a 0' mode will read in words from stdin. So I can run my attack using the following command:
- (Editor note: This option is bad. Keep reading for a better one) python3 word_combinator.py | hashcat -a 0 -m 0 uncracked_hashes.txt
This wasn't pretty, but it did crack a number of hashes. Still, my guess generation was super slow as it is running a slow python script and then pipes those guesses into hashcat (piping guesses is also slow). Raw-MD5 is fast to compute. Basically this option wastes a lot of time and limits the key-spaces I can search. How about we speed this up using Hashcat's combinator attack?
Hashcat's combinator attack '-a 1' allows you to combine two dictionaries together to target multi-word passwords. For example, let's assume you have the following two word-lists
dic1.txt
- fluffy
- scary
- cuddly
dic2.txt
- cat
- bat
- rat
If you run the following command:
- hashcat --stdout -a 1 dict1.txt dict2.txt
You'll get the following output:
- fluffycat
- fluffybat
- fluffyrat
- scarycat
- scarybat
- scaryrat
- cuddlycat
- cuddlybat
- cuddlyrat
You can also apply one (AND ONLY ONE) rule to each dictionary if you want using the '-j' (applied to left word list) and '-k' (applied to right word list). So for example if you use the following command:
- hashcat --stdout -a 1 -j '$ ' -k '$1' dict1.txt dict2.txt
It'll create the following guesses
- fluffy cat1
- fluffy bat1
- fluffy rat1
- <you get the idea>
As reference the '$' rule appends a character to the end of a guess. So '$ ' appends a space, and '$1' appends a '1'. I think you might see where this is going....
The problem is, this works great for two word phrases. But what about three and four word phrases? I wish I knew of a better solution, but the short answer is I hope your cracking system has some free hard-drive space! You can only use combinator with two input dictionaries, and you can't pipe in guesses into hashcat if you are using '-a 9' mode. The fastest option then is to create a word-list of all two word phrases. If you don't want to write a custom program to do this, you can always use hashcat and pipe the guesses to a file. For example:
- hashcat --stdout -a 1 -j '$ ' english_words.txt english_words.txt > two_wordst.txt
Then to try three words you can run
- hashcat -m 0 -a 1 -j '$ ' -k'$1 ' uncracked_hashes.txt two_words.txt english_words.txt
To try four words you can simply run
- hashcat -m 0 -a 1 -j '$ ' -k'$1 ' uncracked_hashes.txt two_words.txt two_words.txt
Side note, I also has success by capitalizing the first letter by changing the -j rule to:
- -j'c$ '
This attack yielded a ton of cracks. Looking through them I started trying to find "unique" and "odd" phrases to try and figure out where the source material came from. This is because while the above attack works great against fast hashes like raw-md5, they will not scale against slow hashes like Bcrypt. We need to further optimize our attacks. Given that, here is a subsection of my cracked passwords:

Most of these phrases were spectacularly unhelpful. But some of them stood out such as 'watch your food'. Running a quick google search on that + the "scifi" highlighted Project Hail Mary [link]. That was a book I loved and hated in equal parts so it brought up a number of mixed feelings, but it certainly seems like a good candidate. The challenge is that the book isn't in the public commons. Still, let's try and create a dictionary of quotes copied from that article.
Next step was to create a janky Python program that would output all 2, 3, and 4 word phrases from the book paragraphs I had found. I know janky Python programs are slow, but so is cracking Bcrypt hashes. In this case it is better to minimize the number of guesses I make vs. focusing on how fast those guesses are generated.

Side note: I apologize for putting this as a screenshot. I really wish Google's blogger had a code insert option...
Running this through hashcat again yielded a new cracked hash!

That's also a pretty unusual phrase, so I have high confidence that Project Hail Mary is one of the sources for the plain-texts. Let's try this against the bcrypt hashes!!!!!
Annnnd nothing cracked.......
This was disappointing, but it's probably because I was only using two paragraphs from the book. I need to find a better source to grab quotes from.
Let me take a step back and say, this workflow loop is one of the keys to this contest. If the cracked fast hashes (raw-md5, raw-sha1, etc) are any indication, around 1/3rd of the high value hashes are phrases taken from books and movies.
Key workflow for CMIYC 2023:
- Find the source material for passphrases by analyzing your cracks against fast hashes
- Create input dictionaries by scraping webpages of book and movie quotes and screenplays
- Run those input dictionaries against the slow high-value hashes.
- Repeat
The problem for me is that workflow is manually intensive, time consuming, and quite frankly boring as hell. During a competition it can be fun to get that dopamine hit as you crack new bcrypt hashes. After the contest, I'm simply wasting time while running up my power bill. So the question is, can I automate this at all? My power bill will still be high, but at least then I can watch new episodes of Asohka vs. staring at my computer screen! How about I train my PCFG guess generator on cracked passphrases and let it crunch away at generating guesses? I mean, it worked for the Hashcat team! [Link].
There's various ways to create the training set, but given how Korelogic generated these passwords, and the plain-text values I was seeing, I just threw everything that had a 'space' into a training file using the following command line:
- cat cmiyc2023_.potfile | grep ' ' | awk -F ':' '{print $2}' > passphrase_cracked.txt
I know, I could have done the word-list generation much better as a short python script in my Jupyter Notebook, but I got places to be and Starwars episodes to watch! Now that I had a good training set, I then trained a PCFG grammar on it using the following command:
- python3 ../../repos/pcfg_cracker/trainer.py -c 1 -r CMICY23_Passphrase -t passphrase_cracked.txt
I set coverage (-c) to be 1 so the PCFG guesser will not generate any brute force (OMEN) guesses. I then gave this attack a test run against raw-sha256 hashes using the following command:
- python3 ../../repos/pcfg_cracker/pcfg_guesser.py -r CMICY23_Passphrase | hashcat -m 1400 -a 0 uncracked_hashes.txt
And.... Yup this looks promising:

Let's see how it does with Bcrypt using the following command:
- python3 ../../repos/pcfg_cracker/pcfg_guesser.py -r CMICY23_Passphrase | hashcat -m 3200 -a 0 uncracked_hashes.txt

Success! Limited Success!
There is still a ton of optimization I could do. You'll notice I haven't re-added / merged my potfiles in from the previous cracking of the Unix Epoch timestamp hashes. I also am targeting all of the Bcrypt hashes vs. just the ones in the engineering department. By reducing the target hashes I could easily double the speed of plain-text guesses I am making against the target hash list. I also don't want to give the false impression that this is the best attack method for these hashes. It's not. You would be much more successful by trying to find the source material and creating custom word-lists from that. What this attack workflow has going for it though is it is one of the most automatable options. You can let this run while trying to figure out better methods. Or... you can go do something else besides crack passwords. Call you parents maybe? I'm sure they would appreciate it!
I think this is a good spot to end this blog post. Looking back at it, I somehow managed to cover every attack mode in Hashcat. There's still more techniques to dig into, and there's a ton of uncracked hashes left in this contest. But I might leave that for a future post. If you have any tips, suggestions, or comments, feel free to leave them in the comments. Good luck, and I hope to see everyone at CMIYC 2024! Also thanks once again to the KoreLogic team for putting together such a great contest!
如有侵权请联系:admin#unsafe.sh