
2022-8-22 13:16:0 Author: reusablesec.blogspot.com(查看原文) 阅读量:6 收藏
“We do not learn from experience... we learn from reflecting on experience.”
-- John Dewey
Introduction:
KoreLogic's Crack Me if You Can (CMIYC) is one of the oldest as most established password cracking competitions. Held every year at Defcon, it serves as a great way to pull together password enthusiasts from all over the world and provides a shared use-case that drives password cracking tool development throughout the rest of the year.
This year I competed as a street team and managed to finish in 12th place:

Now that I've had a week to look back on things, there certainly are strategies where I could have done better. The first is with my cracking setup. I had two systems I used. My primary cracking system was still my laptop running an Ubuntu VM utilizing WSL on a Windows 11 install. My secondary system was the computer I described setting up in this blog post.
Primary Laptop:
CPU: i7-8640U CPU
RAM: 16 GB
Storage: 500GB SSD
Desktop Computer:
CPU: Intel i5-7600k, 1 processor; 4 cores
I really didn't do a good job of splitting my work between both these systems and making sure that my limited GPU was always working. For example, I had a bad habit of running JtR sessions on my desktop computer. Long story short, one week later I have a lot of ideas for future projects to improve my cracking skills, and I'm super excited to start working on them, which is the real benefit of competing in contests like this. Rather than go through a blow for blow recount of the contest, I'll instead try to highlight a couple of tips and lessons I learned along the way.
Core Contest Techniques:
Before diving into this write-up, I HIGHLY recommend reading my previous write-up for the CrackTheCon contest which is available here.
I'm going to skip most of the techniques covered there, but I will say they all applied to the KoreLogic contest as well. It really surprised me how much I referred back to that article when I was competing in this contest.
Contest Overview:
At a high level the contest consisted of cracking a variety of encrypted files, each of which would have individual hashes to crack. For the street teams, the password to crack the encrypted files were fairly simple, so the real challenge there was getting your tooling setup properly to handle those files.
Once the encrypted files were cracked, the unencrypted files could be opened up to reveal a set of very quick to compute hashes. As someone who doesn't have a lot of compute resources to throw at the problem, I really appreciated the fact that the hashes were so fast! Cracking these hashes was all about trying to figure out the base words used to construct them, as well as the mangling rules that were applied. One thing I will say is that the selection of mangling rules Korelogic picked made "loopback" style attacks significantly less effective than the CrackTheCon contest. Don't get me wrong, loopback attacks were still very powerful! But as a player I really needed to analyze the passwords and figure out the underlying mangling rules vs. using loopback as a crutch.
Long story short, I thought that KoreLogic outdid themselves when it came to creating a fun challenge. I thought the contest had a good difficulty scaling to make it approachable to a wide variety of players while still providing areas of growth and frustration to more experienced players.
Tip #1: Make use of John the Ripper *2John utilities to crack encrypted files
Password cracking programs don't need to use the entire encrypted file. Just think about it; Would you really want to try to have you cracking program parse a 100 GiB file every time it makes a guess? What cracking programs really need is a "hash" to make a guess against. To extract that "hash", and to save it in a format that password cracking programs can utilize, John the Ripper comes with a large selection of helper programs in the /john/run/ directory which are identifiable by the '2john' suffix. You can see this below:

The main challenge is to figure out which helper program you want to use. For example, here is me running pdf2john to extract the password hash from the list23-ThisYearsWorst.pdf challenge:

Rather than having it print out to your screen, I'd recommend piping the output of this into a file which you would then load in as the target hash file for your cracking program. One important thing: If you are cracking multiple encrypted files at once, you can store all of these hashes in the same file, just like with any other John the Ripper hash format. Many of these hashes are also supported by Hashcat too, so once you extract them using the 2john helper utilities, don't feel like you have to stick to using John the Ripper to crack the hashes.
Tip #2: Make sure you compile John the Ripper with all the optional libraries to enable cracking encrypted files.
One downside about the flexibility that John the Ripper provides by being able to compile and run it on just about anything, is that it will gladly compile without certain features and cracking modes being enabled if you don't have the correct libraries present when building it. This can be very hard to diagnose after the fact beyond a "For some reason JtR doesn't seem to recognize a particular hash type" style errors.
This happened to me in the previous CrackTheCon contest where I couldn't get John the Ripper to crack an encrypted Zip file. Luckily for this contest I realized what was going on and was able to fix it, but I really need to update my JtR install instructions here with the new information.
That being said, here are all the additional libraries I needed to have before running './configure' to build John the Ripper (with Ubuntu 18) to enable support for cracking encrypted files used during the CMIYC contest:
sudo apt-get install libz-dev, bzip2, yasm libgmp-dev libpcap-dev libnss3-dev libkrb5-dev pkg-config libbz2-dev zlib1g-dev libcompress-raw-lzma-perl
Most of these libraries were specifically for cracking the 7zip and zip files. The perl library was for being able to successfully run 7zip2john.pl.
What this process really highlighted for me is that I really should create an Ansible Playbook to configure a system to run John the Ripper. Going back through all my write-ups in the past to figure out the different dependencies is no fun, and causes a lot of problems when I accidently miss one of them. Unless I get distracted, watch this space as I'll probably end up posting about that Ansible playbook here, and posting it to github.
Tip #3: Save your John the Ripper rules in an external file
Let's face it, John the Ripper's default config file has grown way too large and unwieldy to effectively edit during a password cracking competition. Instead, I highly recommend including your custom rules in an external file to make it easier to quickly find the rules you want to edit or modify. Another advantage of this approach is if you upgrade your copy of John the Ripper, and the config file changes, your old rules will still be saved.
The first step to do this is to include a link in your john.conf file to your custom .conf file by inserting the line:
.include <FILENAME_OF_YOUR_CONFIG_FILE>
Here is a snapshot of my john.conf file I used for this contest:

And here is a subset of the rules in my custom "cmiyc.conf" file for targeting challenge 20 hashes:
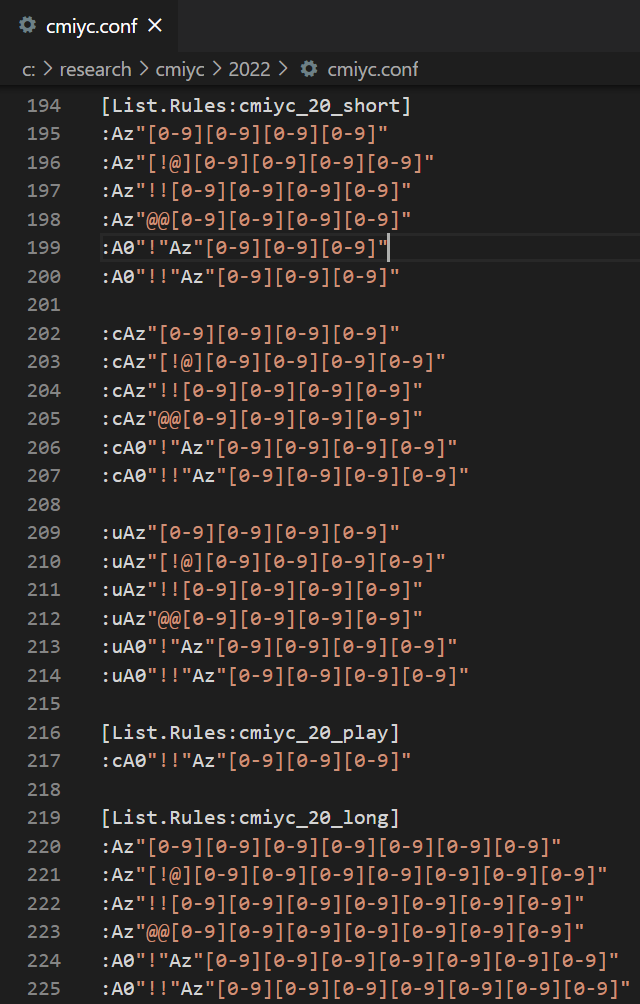
You'll notice I still have individual rule sets in my custom configuration. This way I can perform quick cracking runs to figure out new rules, (or pipe the output to other John sessions. See Tip #4), and then have longer runs to perform on new dictionary words that I later identify.
Tip #4: Use the --stdout and --pipe options to combine multiple cracking rules
In the screenshot above of my rules for targeting challenge 20, you'll see similar blocks of rules where the only different is the first mangling rule, (either nothing, 'c', or 'u'). 'c' stands for Capitalizing and 'u' stands for UPPERCASE. The proper way to handle this would be to leverage John the Ripper's rule preprocessor to try combinations of different rules. The rule preprocessor is one of those killer features that JtR has but Hashcat doesn't. For example you can try multiple rule types, (such as capitalization and uppercasing), by including them between brackets []. For example:
[cu]
Here is a screenshot of that in action:

Still, there are times when you have a larger set of rules you quickly want to apply one or more additional mangling rules to. One of the easier ways to to this is to pipe one instance of JtR or Hashcat into another instance of your cracking program of choice.
The format for doing this with both JtR and Hashcat is slightly different. With JtR, the base generating instance will have the '--stdout' flag in place of a hashfile. You can then pipe '|' the results into another JtR instance that has the '--pipe' flag instead of a wordlist. Note: You will want to use the '--pipe' command and not the '--stdin' command so that the rules of the second instance are applied to every word sent to it. For example:

You can also pipe guesses into Hashcat instead of John the Ripper. This is a very powerful technique because you can take advantage of John the Ripper's rule preprocessor, (or features such as its better Incremental Markov mode, or built-in Prince mode), but still have Hashcat take advantage of your GPUs when cracking hashes. All you need to do in Hashcat is not enter in a wordlist file and it will automatically accept guesses from stdin. This tends to work better if you also have a large number of mangling rules in Hashcat to help keep those GPUs of yours busy since you want to limit the amount of time transferring information from your CPU to the GPU. Aka if you can transfer a limited number of base "words" from the CPU and expand them via additional mangling rules in the GPU, you'll achieve a higher guess per second rate. Below is a screenshot of using this approach. Ignore the '--force' option as I took the screenshot on my laptop vs. my desktop which I normally run my Hashcat sessions from.

Tip #5: For password cracking competitions, perform web searches on "interesting" words
This was the piece of advice I wish I could build a time machine and send back to my past self. I really didn't do a good job of this during the contest. This is despite the fact that Saturday night I finally googled some of the words for challenge #20 and found that creating wordlists from articles discussing a high schooler hacking the Homecoming queen prom vote were extremally effective. In fact, I had the biggest jumps in my score thanks to finding those articles.
This is an area ripe for tool development. Admittedly it likely won't have much real world applications. But for contests, having a tool or process to automate the identification of sources of wordlists would be super helpful. In my head, the tool would take the following approach:
- Use the PCFG trainer to create an input wordlist of the base words in cracked passwords
- Identify words that weren't in the "top 500 English words" or in John the Ripper's "password.lst" wordlist
- Perform a google search and identify results that contained [all/most] of the words to identify possible sources of the wordlist
- Scrape the sites and build a custom dictionary.
Who knows, maybe I'll get motivated and have this done before next year's CMIYC?
Tip #6: Use Linux's 'alias' command to make your commands shorter
I'll admit I don't always do this, (for example see all of the screenshots above), but rather than type the full path for John the Ripper or Hashcat, you can use Linux's 'alias' command to link to them. For example:
alias john=/mnt/c/github/JohnTheRipper/run/john
alias hashcat=/mnt/c/tools/hashcat/hashcat.bin
With the above, now you can simply type 'john' or 'hashcat' to invoke them. Note: This works better than trying to add the John the Ripper or Hashcat directories to your command path as John the Ripper specifically gets weird when you do that. This probably won't help you crack more passwords, but it is a nice quality of life improvement, especially if you have different directories you are maintaining for contest hash lists and dictionaries.
Tip #7: Modify the PCFG's multiword detector to identify shorter words
Of course I need to make a new tip utilizing the PCFG toolset! The PCFG trainer is a really powerful tool to create input dictionaries from cracked passwords. During this contest, one thing I noticed from the passwords I was cracking was that KoreLogic added a large number of two/three letter prefixes/suffixes to the base word. For example, here is some of the mangling rules I started using.

One problem I had utilizing the PCFG trainer on these passwords was that its multiword detector enforced a minimum length five characters long for detecting base words. This was to reduce false positives. Or to put it another way, if you are parsing 60 million passwords, if you reduced the minimum base-word length to three characters, everything would look like a multiword!
The difference during a competition is that your training list is not 60 million passwords long (unless you are doing really, really well!). Therefore it was helpful for me to modify my code to detect multiwords that were only three characters in length. I eventually plan on releasing a patch to the PCFG toolset to make this a command line option, but until then you can make the changes yourself here in the code:

Conclusion:
As I continue to reflect on this contest, I'll probably keep adding to the list of tips above. Even as I write this conclusion other ideas are popping into my head (such as using the online version of Microsoft OneNote to pass documentation and commands between different computers). But I want to conclude by saying I hope these blog posts are helpful, and that I really wanted to thank the KoreLogic team once again for running an amazing contest.
如有侵权请联系:admin#unsafe.sh