
By applying well-known fuzzing techniques to a popular target, I found several bugs that in total yielded over $200K in bounties. In this article I will demonstrate how powerful fuzzing can be when applied to software which has not yet faced sufficient testing.
If you’re here just for the bug disclosures, see Part 2, though I encourage you all, even those who have not yet tried their hand at fuzzing, to read through this.
A few friends and I ran a little Discord server (now a Matrix space) which in which we discussed security and vulnerability research techniques. One of the things we have running in the server is a bot which posts every single CVE as they come out. And, yeah, I read a lot of them.
One day, the bot posted something that caught my eye:
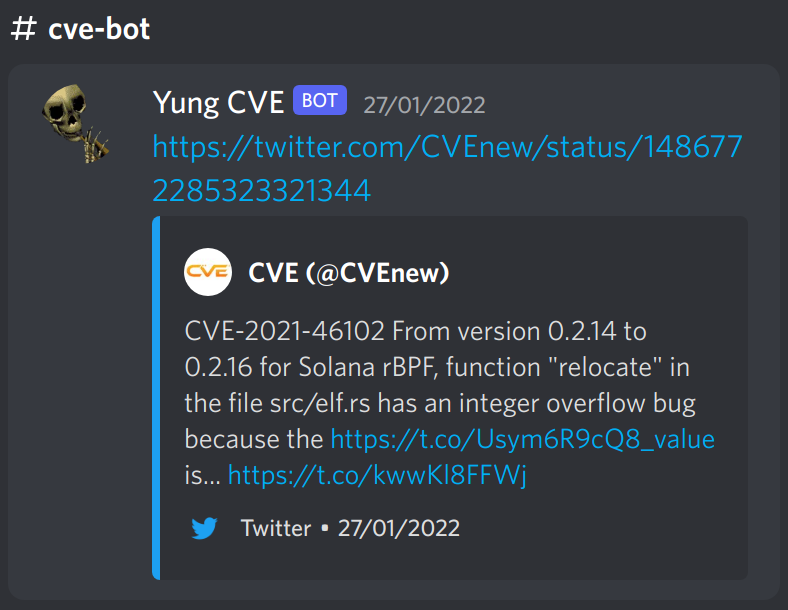

This marks the beginning of our timeline: January 28th. I had noticed this CVE in particular for two reasons:
- it was BPF, which I find to be an absurdly cool concept as it’s used in the Linux kernel (a JIT compiler in the kernel!!! what!!!)
- it was a JIT compiler written in Rust
This CVE showed up almost immediately after I had developed some relatively intensive fuzzing for some of my own Rust software (specifically, a crate for verifying sokoban solutions where I had observed similar issues and thought “that looks familiar”).
Knowing what I had learned from my experience fuzzing my own software and that bugs in Rust programs could be quite easily found with the combo of cargo fuzz and arbitrary, I thought: “hey, why not?”.
Solana, as several of you likely know, “is a decentralized blockchain built to enable scalable, user-friendly apps for the world”. They primarily are known for their cryptocurrency, SOL, but also are a blockchain which operates really any form of smart contract.
rBPF in particular is a self-described “Rust virtual machine and JIT compiler for eBPF programs”. Notably, it implements both an interpreter and a JIT compiler for BPF programs. In other words: two different implementations of the same program, which theoretically exhibited the same behaviour when executed.
I was lucky enough to both take a software testing course in university and to have been part of a research group doing fuzzing (admittedly, we were fuzzing hardware, not software, but the concepts translate). A concept that I had hung onto in particular is the idea of test oracles – a way to distinguish what is “correct” behaviour and what is not in a design under test.
In particular, something that stood out to me about the presence of both an interpreter and a JIT compiler in rBPF is that we, in effect, had a perfect pseudo-oracle; as Wikipedia puts it:
a separately written program which can take the same input as the program or system under test so that their outputs may be compared to understand if there might be a problem to investigate.
Those of you who have more experience in fuzzing will recognise this concept as differential fuzzing, but I think we can often overlook that differential fuzzing is just another face of a pseudo-oracle.
In this particular case, we can execute the interpreter, one implementation of rBPF, and then execute the JIT compiled version, another implementation, with the same inputs (i.e., memory state, entrypoint, code, etc.) and see if their outputs are different. If they are, one of them must necessarily be incorrect per the description of the rBPF crate: two implementations of exactly the same behaviour.
To start off, let’s try to throw a bunch of inputs at it without really tuning to anything in particular. This allows us to sanity check that our basic fuzzing implementation actually works as we expect.
The dumb fuzzer
First, we need to figure out how to execute the interpreter. Thankfully, there are several examples of this readily available in a variety of tests. I referenced the test_interpreter_and_jit macro present in ubpf_execution.rs as the basis for how my so-called “dumb” fuzzer executes.
I’ve provided a sequence of components you can look at one chunk at a time before moving onto the whole fuzzer. Just click on the dropdowns to view the code relevant to that step. You don’t necessarily need to to understand the point of this post.
Step 1: Defining our inputs
We must define our inputs such that it’s actually useful for our fuzzer. Thankfully, arbitrary makes it near trivial to derive an input from raw bytes.
#[derive(arbitrary::Arbitrary, Debug)]
struct DumbFuzzData {
template: ConfigTemplate,
prog: Vec<u8>,
mem: Vec<u8>,
}
If you want to see the definition of ConfigTemplate, you can check it out in common.rs, but all you need to know is that its purpose is to test the interpreter under a variety of different execution configurations. It’s not particularly important to understand the fundamental bits of the fuzzer.
Step 2: Setting up the VM
Setting up the fuzz target and the VM comes next. This will allow us to not only execute our test, but later to actually check if the behaviour is correct.
fuzz_target!(|data: DumbFuzzData| {
let prog = data.prog;
let config = data.template.into();
if check(&prog, &config).is_err() {
// verify please
return;
}
let mut mem = data.mem;
let registry = SyscallRegistry::default();
let mut bpf_functions = BTreeMap::new();
register_bpf_function(&config, &mut bpf_functions, ®istry, 0, "entrypoint").unwrap();
let executable = Executable::<UserError, TestInstructionMeter>::from_text_bytes(
&prog,
None,
config,
SyscallRegistry::default(),
bpf_functions,
)
.unwrap();
let mem_region = MemoryRegion::new_writable(&mut mem, ebpf::MM_INPUT_START);
let mut vm =
EbpfVm::<UserError, TestInstructionMeter>::new(&executable, &mut [], vec![mem_region]).unwrap();
// TODO in step 3
});
You can find the details for how fuzz_target works from the Rust Fuzz Book which goes over how it works in higher detail than would be appropriate here.
Step 3: Executing our input and comparing output
In this step, we just execute the VM with our provided input. In future iterations, we’ll compare the output of interpreter vs JIT, but in this version, we’re just executing the interpreter to see if we can induce crashes.
fuzz_target!(|data: DumbFuzzData| {
// see step 2 for this bit
drop(black_box(vm.execute_program_interpreted(
&mut TestInstructionMeter { remaining: 1024 },
)));
});
I use black_box here but I’m not entirely convinced that it’s necessary. I added it to ensure that the result of the interpreted program’s execution isn’t simply discarded and thus the execution marked unnecessary, but I’m fairly certain it wouldn’t be regardless.
Note that we are not checking for if the execution failed here. If the BPF program fails: we don’t care! We only care if the VM crashes for any reason.
Step 4: Put it together
Below is the final code for the fuzzer, including all of the bits I didn’t show above for concision.
#![feature(bench_black_box)]
#![no_main]
use std::collections::BTreeMap;
use std::hint::black_box;
use libfuzzer_sys::fuzz_target;
use solana_rbpf::{
ebpf,
elf::{register_bpf_function, Executable},
memory_region::MemoryRegion,
user_error::UserError,
verifier::check,
vm::{EbpfVm, SyscallRegistry, TestInstructionMeter},
};
use crate::common::ConfigTemplate;
mod common;
#[derive(arbitrary::Arbitrary, Debug)]
struct DumbFuzzData {
template: ConfigTemplate,
prog: Vec<u8>,
mem: Vec<u8>,
}
fuzz_target!(|data: DumbFuzzData| {
let prog = data.prog;
let config = data.template.into();
if check(&prog, &config).is_err() {
// verify please
return;
}
let mut mem = data.mem;
let registry = SyscallRegistry::default();
let mut bpf_functions = BTreeMap::new();
register_bpf_function(&config, &mut bpf_functions, ®istry, 0, "entrypoint").unwrap();
let executable = Executable::<UserError, TestInstructionMeter>::from_text_bytes(
&prog,
None,
config,
SyscallRegistry::default(),
bpf_functions,
)
.unwrap();
let mem_region = MemoryRegion::new_writable(&mut mem, ebpf::MM_INPUT_START);
let mut vm =
EbpfVm::<UserError, TestInstructionMeter>::new(&executable, &mut [], vec![mem_region]).unwrap();
drop(black_box(vm.execute_program_interpreted(
&mut TestInstructionMeter { remaining: 1024 },
)));
});
Theoretically, an up-to-date version is available in the rBPF repo.
Evaluation
$ cargo +nightly fuzz run dumb -- -max_total_time=300
... snip ...
#2902510 REDUCE cov: 1092 ft: 2147 corp: 724/58Kb lim: 4096 exec/s: 9675 rss: 355Mb L: 134/3126 MS: 3 ChangeBit-InsertByte-PersAutoDict- DE: "\x07\xff\xff3"-
#2902537 REDUCE cov: 1092 ft: 2147 corp: 724/58Kb lim: 4096 exec/s: 9675 rss: 355Mb L: 60/3126 MS: 2 ChangeBinInt-EraseBytes-
#2905608 REDUCE cov: 1092 ft: 2147 corp: 724/58Kb lim: 4096 exec/s: 9685 rss: 355Mb L: 101/3126 MS: 1 EraseBytes-
#2905770 NEW cov: 1092 ft: 2155 corp: 725/58Kb lim: 4096 exec/s: 9685 rss: 355Mb L: 61/3126 MS: 2 ShuffleBytes-CrossOver-
#2906805 DONE cov: 1092 ft: 2155 corp: 725/58Kb lim: 4096 exec/s: 9657 rss: 355Mb
Done 2906805 runs in 301 second(s)
After executing the fuzzer, we can evaluate its effectiveness at finding interesting inputs by checking its coverage after executing for a given time (note the use of the -max_total_time flag). In this case, I want to determine just how well it covers the function which handles interpreter execution. To do so, I issue the following commands:
$ cargo +nightly fuzz coverage dumb
$ rust-cov show -Xdemangler=rustfilt fuzz/target/x86_64-unknown-linux-gnu/release/dumb -instr-profile=fuzz/coverage/dumb/coverage.profdata -show-line-counts-or-regions -name=execute_program_interpreted_inner
Command output of rust-cov
If you’re not familiar with llvm coverage output, the first column is the line number, the second column is the number of times that that particular line was hit, and the third column is the code itself.
<solana_rbpf::vm::EbpfVm<solana_rbpf::user_error::UserError, solana_rbpf::vm::TestInstructionMeter>>::execute_program_interpreted_inner:
709| 763| fn execute_program_interpreted_inner(
710| 763| &mut self,
711| 763| instruction_meter: &mut I,
712| 763| initial_insn_count: u64,
713| 763| last_insn_count: &mut u64,
714| 763| ) -> ProgramResult<E> {
715| 763| // R1 points to beginning of input memory, R10 to the stack of the first frame
716| 763| let mut reg: [u64; 11] = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, self.stack.get_frame_ptr()];
717| 763| reg[1] = ebpf::MM_INPUT_START;
718| 763|
719| 763| // Loop on instructions
720| 763| let config = self.executable.get_config();
721| 763| let mut next_pc: usize = self.executable.get_entrypoint_instruction_offset()?;
^0
722| 763| let mut remaining_insn_count = initial_insn_count;
723| 136k| while (next_pc + 1) * ebpf::INSN_SIZE <= self.program.len() {
724| 135k| *last_insn_count += 1;
725| 135k| let pc = next_pc;
726| 135k| next_pc += 1;
727| 135k| let mut instruction_width = 1;
728| 135k| let mut insn = ebpf::get_insn_unchecked(self.program, pc);
729| 135k| let dst = insn.dst as usize;
730| 135k| let src = insn.src as usize;
731| 135k|
732| 135k| if config.enable_instruction_tracing {
733| 0| let mut state = [0u64; 12];
734| 0| state[0..11].copy_from_slice(®);
735| 0| state[11] = pc as u64;
736| 0| self.tracer.trace(state);
737| 135k| }
738| |
739| 135k| match insn.opc {
740| 135k| _ if dst == STACK_PTR_REG && config.dynamic_stack_frames => {
741| 361| match insn.opc {
742| 16| ebpf::SUB64_IMM => self.stack.resize_stack(-insn.imm),
743| 345| ebpf::ADD64_IMM => self.stack.resize_stack(insn.imm),
744| | _ => {
745| | #[cfg(debug_assertions)]
746| 0| unreachable!("unexpected insn on r11")
747| | }
748| | }
749| | }
750| |
751| | // BPF_LD class
752| | // Since this pointer is constant, and since we already know it (ebpf::MM_INPUT_START), do not
753| | // bother re-fetching it, just use ebpf::MM_INPUT_START already.
754| | ebpf::LD_ABS_B => {
755| 3| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(insn.imm as u32 as u64);
756| 3| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u8);
^0
757| 0| reg[0] = unsafe { *host_ptr as u64 };
758| | },
759| | ebpf::LD_ABS_H => {
760| 3| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(insn.imm as u32 as u64);
761| 3| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u16);
^0
762| 0| reg[0] = unsafe { *host_ptr as u64 };
763| | },
764| | ebpf::LD_ABS_W => {
765| 2| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(insn.imm as u32 as u64);
766| 2| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u32);
^0
767| 0| reg[0] = unsafe { *host_ptr as u64 };
768| | },
769| | ebpf::LD_ABS_DW => {
770| 4| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(insn.imm as u32 as u64);
771| 4| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u64);
^0
772| 0| reg[0] = unsafe { *host_ptr as u64 };
773| | },
774| | ebpf::LD_IND_B => {
775| 2| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(reg[src]).wrapping_add(insn.imm as u32 as u64);
776| 2| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u8);
^0
777| 0| reg[0] = unsafe { *host_ptr as u64 };
778| | },
779| | ebpf::LD_IND_H => {
780| 3| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(reg[src]).wrapping_add(insn.imm as u32 as u64);
781| 3| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u16);
^0
782| 0| reg[0] = unsafe { *host_ptr as u64 };
783| | },
784| | ebpf::LD_IND_W => {
785| 7| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(reg[src]).wrapping_add(insn.imm as u32 as u64);
786| 7| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u32);
^0
787| 0| reg[0] = unsafe { *host_ptr as u64 };
788| | },
789| | ebpf::LD_IND_DW => {
790| 3| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(reg[src]).wrapping_add(insn.imm as u32 as u64);
791| 3| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u64);
^0
792| 0| reg[0] = unsafe { *host_ptr as u64 };
793| | },
794| |
795| 0| ebpf::LD_DW_IMM => {
796| 0| ebpf::augment_lddw_unchecked(self.program, &mut insn);
797| 0| instruction_width = 2;
798| 0| next_pc += 1;
799| 0| reg[dst] = insn.imm as u64;
800| 0| },
801| |
802| | // BPF_LDX class
803| | ebpf::LD_B_REG => {
804| 18| let vm_addr = (reg[src] as i64).wrapping_add(insn.off as i64) as u64;
805| 18| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u8);
^2
806| 2| reg[dst] = unsafe { *host_ptr as u64 };
807| | },
808| | ebpf::LD_H_REG => {
809| 18| let vm_addr = (reg[src] as i64).wrapping_add(insn.off as i64) as u64;
810| 18| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u16);
^6
811| 6| reg[dst] = unsafe { *host_ptr as u64 };
812| | },
813| | ebpf::LD_W_REG => {
814| 365| let vm_addr = (reg[src] as i64).wrapping_add(insn.off as i64) as u64;
815| 365| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u32);
^348
816| 348| reg[dst] = unsafe { *host_ptr as u64 };
817| | },
818| | ebpf::LD_DW_REG => {
819| 15| let vm_addr = (reg[src] as i64).wrapping_add(insn.off as i64) as u64;
820| 15| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u64);
^5
821| 5| reg[dst] = unsafe { *host_ptr as u64 };
822| | },
823| |
824| | // BPF_ST class
825| | ebpf::ST_B_IMM => {
826| 26| let vm_addr = (reg[dst] as i64).wrapping_add( insn.off as i64) as u64;
827| 26| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u8);
^20
828| 20| unsafe { *host_ptr = insn.imm as u8 };
829| | },
830| | ebpf::ST_H_IMM => {
831| 23| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
832| 23| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u16);
^13
833| 13| unsafe { *host_ptr = insn.imm as u16 };
834| | },
835| | ebpf::ST_W_IMM => {
836| 12| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
837| 12| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u32);
^5
838| 5| unsafe { *host_ptr = insn.imm as u32 };
839| | },
840| | ebpf::ST_DW_IMM => {
841| 17| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
842| 17| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u64);
^11
843| 11| unsafe { *host_ptr = insn.imm as u64 };
844| | },
845| |
846| | // BPF_STX class
847| | ebpf::ST_B_REG => {
848| 17| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
849| 17| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u8);
^3
850| 3| unsafe { *host_ptr = reg[src] as u8 };
851| | },
852| | ebpf::ST_H_REG => {
853| 13| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
854| 13| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u16);
^3
855| 3| unsafe { *host_ptr = reg[src] as u16 };
856| | },
857| | ebpf::ST_W_REG => {
858| 19| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
859| 19| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u32);
^7
860| 7| unsafe { *host_ptr = reg[src] as u32 };
861| | },
862| | ebpf::ST_DW_REG => {
863| 8| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
864| 8| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u64);
^2
865| 2| unsafe { *host_ptr = reg[src] as u64 };
866| | },
867| |
868| | // BPF_ALU class
869| 1.06k| ebpf::ADD32_IMM => reg[dst] = (reg[dst] as i32).wrapping_add(insn.imm as i32) as u64,
870| 695| ebpf::ADD32_REG => reg[dst] = (reg[dst] as i32).wrapping_add(reg[src] as i32) as u64,
871| 710| ebpf::SUB32_IMM => reg[dst] = (reg[dst] as i32).wrapping_sub(insn.imm as i32) as u64,
872| 345| ebpf::SUB32_REG => reg[dst] = (reg[dst] as i32).wrapping_sub(reg[src] as i32) as u64,
873| 1.03k| ebpf::MUL32_IMM => reg[dst] = (reg[dst] as i32).wrapping_mul(insn.imm as i32) as u64,
874| 2.07k| ebpf::MUL32_REG => reg[dst] = (reg[dst] as i32).wrapping_mul(reg[src] as i32) as u64,
875| 1.03k| ebpf::DIV32_IMM => reg[dst] = (reg[dst] as u32 / insn.imm as u32) as u64,
876| | ebpf::DIV32_REG => {
877| 4| if reg[src] as u32 == 0 {
878| 2| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
879| 2| }
880| 2| reg[dst] = (reg[dst] as u32 / reg[src] as u32) as u64;
881| | },
882| | ebpf::SDIV32_IMM => {
883| 346| if reg[dst] as i32 == i32::MIN && insn.imm == -1 {
^0
884| 0| return Err(EbpfError::DivideOverflow(pc + ebpf::ELF_INSN_DUMP_OFFSET));
885| 346| }
886| 346| reg[dst] = (reg[dst] as i32 / insn.imm as i32) as u64;
887| | }
888| | ebpf::SDIV32_REG => {
889| 13| if reg[src] as i32 == 0 {
890| 2| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
891| 11| }
892| 11| if reg[dst] as i32 == i32::MIN && reg[src] as i32 == -1 {
^0
893| 0| return Err(EbpfError::DivideOverflow(pc + ebpf::ELF_INSN_DUMP_OFFSET));
894| 11| }
895| 11| reg[dst] = (reg[dst] as i32 / reg[src] as i32) as u64;
896| | },
897| 346| ebpf::OR32_IMM => reg[dst] = (reg[dst] as u32 | insn.imm as u32) as u64,
898| 351| ebpf::OR32_REG => reg[dst] = (reg[dst] as u32 | reg[src] as u32) as u64,
899| 345| ebpf::AND32_IMM => reg[dst] = (reg[dst] as u32 & insn.imm as u32) as u64,
900| 1.03k| ebpf::AND32_REG => reg[dst] = (reg[dst] as u32 & reg[src] as u32) as u64,
901| 0| ebpf::LSH32_IMM => reg[dst] = (reg[dst] as u32).wrapping_shl(insn.imm as u32) as u64,
902| 369| ebpf::LSH32_REG => reg[dst] = (reg[dst] as u32).wrapping_shl(reg[src] as u32) as u64,
903| 0| ebpf::RSH32_IMM => reg[dst] = (reg[dst] as u32).wrapping_shr(insn.imm as u32) as u64,
904| 346| ebpf::RSH32_REG => reg[dst] = (reg[dst] as u32).wrapping_shr(reg[src] as u32) as u64,
905| 690| ebpf::NEG32 => { reg[dst] = (reg[dst] as i32).wrapping_neg() as u64; reg[dst] &= u32::MAX as u64; },
906| 347| ebpf::MOD32_IMM => reg[dst] = (reg[dst] as u32 % insn.imm as u32) as u64,
907| | ebpf::MOD32_REG => {
908| 4| if reg[src] as u32 == 0 {
909| 2| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
910| 2| }
911| 2| reg[dst] = (reg[dst] as u32 % reg[src] as u32) as u64;
912| | },
913| 1.04k| ebpf::XOR32_IMM => reg[dst] = (reg[dst] as u32 ^ insn.imm as u32) as u64,
914| 2.74k| ebpf::XOR32_REG => reg[dst] = (reg[dst] as u32 ^ reg[src] as u32) as u64,
915| 349| ebpf::MOV32_IMM => reg[dst] = insn.imm as u32 as u64,
916| 1.03k| ebpf::MOV32_REG => reg[dst] = (reg[src] as u32) as u64,
917| 0| ebpf::ARSH32_IMM => { reg[dst] = (reg[dst] as i32).wrapping_shr(insn.imm as u32) as u64; reg[dst] &= u32::MAX as u64; },
918| 2| ebpf::ARSH32_REG => { reg[dst] = (reg[dst] as i32).wrapping_shr(reg[src] as u32) as u64; reg[dst] &= u32::MAX as u64; },
919| 0| ebpf::LE => {
920| 0| reg[dst] = match insn.imm {
921| 0| 16 => (reg[dst] as u16).to_le() as u64,
922| 0| 32 => (reg[dst] as u32).to_le() as u64,
923| 0| 64 => reg[dst].to_le(),
924| | _ => {
925| 0| return Err(EbpfError::InvalidInstruction(pc + ebpf::ELF_INSN_DUMP_OFFSET));
926| | }
927| | };
928| | },
929| 0| ebpf::BE => {
930| 0| reg[dst] = match insn.imm {
931| 0| 16 => (reg[dst] as u16).to_be() as u64,
932| 0| 32 => (reg[dst] as u32).to_be() as u64,
933| 0| 64 => reg[dst].to_be(),
934| | _ => {
935| 0| return Err(EbpfError::InvalidInstruction(pc + ebpf::ELF_INSN_DUMP_OFFSET));
936| | }
937| | };
938| | },
939| |
940| | // BPF_ALU64 class
941| 402| ebpf::ADD64_IMM => reg[dst] = reg[dst].wrapping_add(insn.imm as u64),
942| 351| ebpf::ADD64_REG => reg[dst] = reg[dst].wrapping_add(reg[src]),
943| 1.12k| ebpf::SUB64_IMM => reg[dst] = reg[dst].wrapping_sub(insn.imm as u64),
944| 721| ebpf::SUB64_REG => reg[dst] = reg[dst].wrapping_sub(reg[src]),
945| 3.06k| ebpf::MUL64_IMM => reg[dst] = reg[dst].wrapping_mul(insn.imm as u64),
946| 1.71k| ebpf::MUL64_REG => reg[dst] = reg[dst].wrapping_mul(reg[src]),
947| 1.39k| ebpf::DIV64_IMM => reg[dst] /= insn.imm as u64,
948| | ebpf::DIV64_REG => {
949| 23| if reg[src] == 0 {
950| 12| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
951| 11| }
952| 11| reg[dst] /= reg[src];
953| | },
954| | ebpf::SDIV64_IMM => {
955| 1.40k| if reg[dst] as i64 == i64::MIN && insn.imm == -1 {
^0
956| 0| return Err(EbpfError::DivideOverflow(pc + ebpf::ELF_INSN_DUMP_OFFSET));
957| 1.40k| }
958| 1.40k|
959| 1.40k| reg[dst] = (reg[dst] as i64 / insn.imm) as u64
960| | }
961| | ebpf::SDIV64_REG => {
962| 12| if reg[src] == 0 {
963| 5| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
964| 7| }
965| 7| if reg[dst] as i64 == i64::MIN && reg[src] as i64 == -1 {
^0
966| 0| return Err(EbpfError::DivideOverflow(pc + ebpf::ELF_INSN_DUMP_OFFSET));
967| 7| }
968| 7| reg[dst] = (reg[dst] as i64 / reg[src] as i64) as u64;
969| | },
970| 838| ebpf::OR64_IMM => reg[dst] |= insn.imm as u64,
971| 1.37k| ebpf::OR64_REG => reg[dst] |= reg[src],
972| 2.14k| ebpf::AND64_IMM => reg[dst] &= insn.imm as u64,
973| 4.47k| ebpf::AND64_REG => reg[dst] &= reg[src],
974| 0| ebpf::LSH64_IMM => reg[dst] = reg[dst].wrapping_shl(insn.imm as u32),
975| 1.73k| ebpf::LSH64_REG => reg[dst] = reg[dst].wrapping_shl(reg[src] as u32),
976| 0| ebpf::RSH64_IMM => reg[dst] = reg[dst].wrapping_shr(insn.imm as u32),
977| 1.03k| ebpf::RSH64_REG => reg[dst] = reg[dst].wrapping_shr(reg[src] as u32),
978| 5.59k| ebpf::NEG64 => reg[dst] = (reg[dst] as i64).wrapping_neg() as u64,
979| 2.85k| ebpf::MOD64_IMM => reg[dst] %= insn.imm as u64,
980| | ebpf::MOD64_REG => {
981| 3| if reg[src] == 0 {
982| 2| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
983| 1| }
984| 1| reg[dst] %= reg[src];
985| | },
986| 2.28k| ebpf::XOR64_IMM => reg[dst] ^= insn.imm as u64,
987| 1.41k| ebpf::XOR64_REG => reg[dst] ^= reg[src],
988| 383| ebpf::MOV64_IMM => reg[dst] = insn.imm as u64,
989| 4.24k| ebpf::MOV64_REG => reg[dst] = reg[src],
990| 0| ebpf::ARSH64_IMM => reg[dst] = (reg[dst] as i64).wrapping_shr(insn.imm as u32) as u64,
991| 357| ebpf::ARSH64_REG => reg[dst] = (reg[dst] as i64).wrapping_shr(reg[src] as u32) as u64,
992| |
993| | // BPF_JMP class
994| 4.43k| ebpf::JA => { next_pc = (next_pc as isize + insn.off as isize) as usize; },
995| 10| ebpf::JEQ_IMM => if reg[dst] == insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^0
996| 1.36k| ebpf::JEQ_REG => if reg[dst] == reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1.36k ^2
997| 4.16k| ebpf::JGT_IMM => if reg[dst] > insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1.42k ^2.74k
998| 1.73k| ebpf::JGT_REG => if reg[dst] > reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1.39k ^343
999| 343| ebpf::JGE_IMM => if reg[dst] >= insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^0
1000| 2.04k| ebpf::JGE_REG => if reg[dst] >= reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1.70k ^342
1001| 2.04k| ebpf::JLT_IMM => if reg[dst] < insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^2.04k ^1
1002| 342| ebpf::JLT_REG => if reg[dst] < reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^0
1003| 1.02k| ebpf::JLE_IMM => if reg[dst] <= insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^0
1004| 2.38k| ebpf::JLE_REG => if reg[dst] <= reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^2.38k ^1
1005| 1.76k| ebpf::JSET_IMM => if reg[dst] & insn.imm as u64 != 0 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1.42k ^347
1006| 686| ebpf::JSET_REG => if reg[dst] & reg[src] != 0 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^0
1007| 6.48k| ebpf::JNE_IMM => if reg[dst] != insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^0
1008| 2.44k| ebpf::JNE_REG => if reg[dst] != reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1.40k ^1.03k
1009| 18.1k| ebpf::JSGT_IMM => if reg[dst] as i64 > insn.imm as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^17.7k ^363
1010| 2.08k| ebpf::JSGT_REG => if reg[dst] as i64 > reg[src] as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^2.07k ^12
1011| 14.3k| ebpf::JSGE_IMM => if reg[dst] as i64 >= insn.imm as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^12.9k ^1.37k
1012| 3.45k| ebpf::JSGE_REG => if reg[dst] as i64 >= reg[src] as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^3.44k ^12
1013| 1.36k| ebpf::JSLT_IMM => if (reg[dst] as i64) < insn.imm as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1.02k ^346
1014| 2| ebpf::JSLT_REG => if (reg[dst] as i64) < reg[src] as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^0
1015| 2.05k| ebpf::JSLE_IMM => if (reg[dst] as i64) <= insn.imm as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^2.04k ^14
1016| 6.83k| ebpf::JSLE_REG => if (reg[dst] as i64) <= reg[src] as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^6.83k ^7
1017| |
1018| | ebpf::CALL_REG => {
1019| 0| let target_address = reg[insn.imm as usize];
1020| 0| reg[ebpf::FRAME_PTR_REG] =
1021| 0| self.stack.push(®[ebpf::FIRST_SCRATCH_REG..ebpf::FIRST_SCRATCH_REG + ebpf::SCRATCH_REGS], next_pc)?;
1022| 0| if target_address < self.program_vm_addr {
1023| 0| return Err(EbpfError::CallOutsideTextSegment(pc + ebpf::ELF_INSN_DUMP_OFFSET, target_address / ebpf::INSN_SIZE as u64 * ebpf::INSN_SIZE as u64));
1024| 0| }
1025| 0| next_pc = self.check_pc(pc, (target_address - self.program_vm_addr) as usize / ebpf::INSN_SIZE)?;
1026| | },
1027| |
1028| | // Do not delegate the check to the verifier, since registered functions can be
1029| | // changed after the program has been verified.
1030| | ebpf::CALL_IMM => {
1031| 22| let mut resolved = false;
1032| 22| let (syscalls, calls) = if config.static_syscalls {
1033| 22| (insn.src == 0, insn.src != 0)
1034| | } else {
1035| 0| (true, true)
1036| | };
1037| |
1038| 22| if syscalls {
1039| 2| if let Some(syscall) = self.executable.get_syscall_registry().lookup_syscall(insn.imm as u32) {
^0
1040| 0| resolved = true;
1041| 0|
1042| 0| if config.enable_instruction_meter {
1043| 0| let _ = instruction_meter.consume(*last_insn_count);
1044| 0| }
1045| 0| *last_insn_count = 0;
1046| 0| let mut result: ProgramResult<E> = Ok(0);
1047| 0| (unsafe { std::mem::transmute::<u64, SyscallFunction::<E, *mut u8>>(syscall.function) })(
1048| 0| self.syscall_context_objects[SYSCALL_CONTEXT_OBJECTS_OFFSET + syscall.context_object_slot],
1049| 0| reg[1],
1050| 0| reg[2],
1051| 0| reg[3],
1052| 0| reg[4],
1053| 0| reg[5],
1054| 0| &self.memory_mapping,
1055| 0| &mut result,
1056| 0| );
1057| 0| reg[0] = result?;
1058| 0| if config.enable_instruction_meter {
1059| 0| remaining_insn_count = instruction_meter.get_remaining();
1060| 0| }
1061| 2| }
1062| 20| }
1063| |
1064| 22| if calls {
1065| 20| if let Some(target_pc) = self.executable.lookup_bpf_function(insn.imm as u32) {
^0
1066| 0| resolved = true;
1067| |
1068| | // make BPF to BPF call
1069| 0| reg[ebpf::FRAME_PTR_REG] =
1070| 0| self.stack.push(®[ebpf::FIRST_SCRATCH_REG..ebpf::FIRST_SCRATCH_REG + ebpf::SCRATCH_REGS], next_pc)?;
1071| 0| next_pc = self.check_pc(pc, target_pc)?;
1072| 20| }
1073| 2| }
1074| |
1075| 22| if !resolved {
1076| 22| if config.disable_unresolved_symbols_at_runtime {
1077| 6| return Err(EbpfError::UnsupportedInstruction(pc + ebpf::ELF_INSN_DUMP_OFFSET));
1078| | } else {
1079| 16| self.executable.report_unresolved_symbol(pc)?;
1080| | }
1081| 0| }
1082| | }
1083| |
1084| | ebpf::EXIT => {
1085| 14| match self.stack.pop::<E>() {
1086| 0| Ok((saved_reg, frame_ptr, ptr)) => {
1087| 0| // Return from BPF to BPF call
1088| 0| reg[ebpf::FIRST_SCRATCH_REG
1089| 0| ..ebpf::FIRST_SCRATCH_REG + ebpf::SCRATCH_REGS]
1090| 0| .copy_from_slice(&saved_reg);
1091| 0| reg[ebpf::FRAME_PTR_REG] = frame_ptr;
1092| 0| next_pc = self.check_pc(pc, ptr)?;
1093| | }
1094| | _ => {
1095| 14| return Ok(reg[0]);
1096| | }
1097| | }
1098| | }
1099| 0| _ => return Err(EbpfError::UnsupportedInstruction(pc + ebpf::ELF_INSN_DUMP_OFFSET)),
1100| | }
1101| |
1102| 135k| if config.enable_instruction_meter && *last_insn_count >= remaining_insn_count {
1103| | // Use `pc + instruction_width` instead of `next_pc` here because jumps and calls don't continue at the end of this instruction
1104| 130| return Err(EbpfError::ExceededMaxInstructions(pc + instruction_width + ebpf::ELF_INSN_DUMP_OFFSET, initial_insn_count));
1105| 135k| }
1106| | }
1107| |
1108| 419| Err(EbpfError::ExecutionOverrun(
1109| 419| next_pc + ebpf::ELF_INSN_DUMP_OFFSET,
1110| 419| ))
1111| 763| }
Unfortunately, this fuzzer doesn’t seem to achieve the coverage we expect. Several instructions are missed (note the 0 coverage on some branches of the match) and there are no jumps, calls, or other control-flow-relevant instructions. This is largely because throwing random bytes at any parser just isn’t going to be effective; most things will get caught at the verification stage, and very little will actually test the program.
We must improve this before we continue or we’ll be waiting forever for our fuzzer to find useful bugs.
At this point, we’re about two hours into development.
The smart fuzzer
eBPF is a quite simple instruction set; you can read the whole definition in just a few pages. Knowing this: why don’t we constrain our input to just these instructions? This approach is commonly called “grammar-aware” fuzzing on account of the fact that the inputs are constrained to some grammar. It is very powerful as a concept, and is used to test a variety of large targets which have strict parsing rules.
To create this grammar-aware fuzzer, I inspected the helpfully-named and provided insn_builder.rs which would allow me to create instructions. Now, all I needed to do was represent all the different instructions. By cross referencing with eBPF documentation, we can represent each possible operation in a single enum. You can see the whole grammar.rs in the rBPF repo if you wish, but the two most relevant sections are provided below.
Defining the enum that represents all instructions
#[derive(arbitrary::Arbitrary, Debug, Eq, PartialEq)]
pub enum FuzzedOp {
Add(Source),
Sub(Source),
Mul(Source),
Div(Source),
BitOr(Source),
BitAnd(Source),
LeftShift(Source),
RightShift(Source),
Negate,
Modulo(Source),
BitXor(Source),
Mov(Source),
SRS(Source),
SwapBytes(Endian),
Load(MemSize),
LoadAbs(MemSize),
LoadInd(MemSize),
LoadX(MemSize),
Store(MemSize),
StoreX(MemSize),
Jump,
JumpC(Cond, Source),
Call,
Exit,
}
Translating FuzzedOps to BpfCode
pub type FuzzProgram = Vec<FuzzedInstruction>;
pub fn make_program(prog: &FuzzProgram, arch: Arch) -> BpfCode {
let mut code = BpfCode::default();
for inst in prog {
match inst.op {
FuzzedOp::Add(src) => code
.add(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Sub(src) => code
.sub(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Mul(src) => code
.mul(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Div(src) => code
.div(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::BitOr(src) => code
.bit_or(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::BitAnd(src) => code
.bit_and(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::LeftShift(src) => code
.left_shift(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::RightShift(src) => code
.right_shift(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Negate => code
.negate(arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Modulo(src) => code
.modulo(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::BitXor(src) => code
.bit_xor(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Mov(src) => code
.mov(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::SRS(src) => code
.signed_right_shift(src, arch)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::SwapBytes(endian) => code
.swap_bytes(endian)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Load(mem) => code
.load(mem)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::LoadAbs(mem) => code
.load_abs(mem)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::LoadInd(mem) => code
.load_ind(mem)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::LoadX(mem) => code
.load_x(mem)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Store(mem) => code
.store(mem)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::StoreX(mem) => code
.store_x(mem)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Jump => code
.jump_unconditional()
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::JumpC(cond, src) => code
.jump_conditional(cond, src)
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Call => code
.call()
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
FuzzedOp::Exit => code
.exit()
.set_dst(inst.dst)
.set_src(inst.src)
.set_off(inst.off)
.set_imm(inst.imm)
.push(),
};
}
code
}
You’ll see here that our generation doesn’t really care to ensure that instructions are valid, just that they’re in the right format. For example, we don’t verify registers, addresses, jump targets, etc.; we just slap it together and see if it works. This is to prevent over-specialisation, where our attempts to fuzz things only make “boring” inputs that don’t test cases that would normally be considered invalid.
Okay – let’s make a fuzzer with this. The only real difference here is that our input format is now changed to have our new FuzzProgram type instead of raw bytes:
#[derive(arbitrary::Arbitrary, Debug)]
struct FuzzData {
template: ConfigTemplate,
prog: FuzzProgram,
mem: Vec<u8>,
arch: Arch,
}
The whole fuzzer, though really it's not that different
This fuzzer expresses a particular stage in development. The differential fuzzer is significantly different in a few key aspects that will be discussed later.
#![feature(bench_black_box)]
#![no_main]
use std::collections::BTreeMap;
use std::hint::black_box;
use libfuzzer_sys::fuzz_target;
use grammar_aware::*;
use solana_rbpf::{
elf::{register_bpf_function, Executable},
insn_builder::{Arch, IntoBytes},
memory_region::MemoryRegion,
user_error::UserError,
verifier::check,
vm::{EbpfVm, SyscallRegistry, TestInstructionMeter},
};
use crate::common::ConfigTemplate;
mod common;
mod grammar_aware;
#[derive(arbitrary::Arbitrary, Debug)]
struct FuzzData {
template: ConfigTemplate,
prog: FuzzProgram,
mem: Vec<u8>,
arch: Arch,
}
fuzz_target!(|data: FuzzData| {
let prog = make_program(&data.prog, data.arch);
let config = data.template.into();
if check(prog.into_bytes(), &config).is_err() {
// verify please
return;
}
let mut mem = data.mem;
let registry = SyscallRegistry::default();
let mut bpf_functions = BTreeMap::new();
register_bpf_function(&config, &mut bpf_functions, ®istry, 0, "entrypoint").unwrap();
let executable = Executable::<UserError, TestInstructionMeter>::from_text_bytes(
prog.into_bytes(),
None,
config,
SyscallRegistry::default(),
bpf_functions,
)
.unwrap();
let mem_region = MemoryRegion::new_writable(&mem, ebpf::MM_INPUT_START);
let mut vm =
EbpfVm::<UserError, TestInstructionMeter>::new(&executable, &mut [], vec![mem_region]).unwrap();
drop(black_box(vm.execute_program_interpreted(
&mut TestInstructionMeter { remaining: 1 << 16 },
)));
});
Evaluation
Let’s see how well this version covers our target now.
$ cargo +nightly fuzz run smart -- -max_total_time=60
... snip ...
#1449846 REDUCE cov: 1730 ft: 6369 corp: 1019/168Kb lim: 4096 exec/s: 4832 rss: 358Mb L: 267/2963 MS: 1 EraseBytes-
#1450798 NEW cov: 1730 ft: 6370 corp: 1020/168Kb lim: 4096 exec/s: 4835 rss: 358Mb L: 193/2963 MS: 2 InsertByte-InsertRepeatedBytes-
#1451609 NEW cov: 1730 ft: 6371 corp: 1021/168Kb lim: 4096 exec/s: 4838 rss: 358Mb L: 108/2963 MS: 1 ChangeByte-
#1452095 NEW cov: 1730 ft: 6372 corp: 1022/169Kb lim: 4096 exec/s: 4840 rss: 358Mb L: 108/2963 MS: 1 ChangeByte-
#1452830 DONE cov: 1730 ft: 6372 corp: 1022/169Kb lim: 4096 exec/s: 4826 rss: 358Mb
Done 1452830 runs in 301 second(s)
Notice that our number of inputs tried (the number farthest left) is nearly half, but our cov and ft values are significantly higher.
Let’s evaluate that coverage a little more specifically:
$ cargo +nightly fuzz coverage smart
$ rust-cov show -Xdemangler=rustfilt fuzz/target/x86_64-unknown-linux-gnu/release/smart -instr-profile=fuzz/coverage/smart/coverage.profdata -show-line-counts-or-regions -show-instantiations -name=execute_program_interpreted_inner
Command output of rust-cov
If you’re not familiar with llvm coverage output, the first column is the line number, the second column is the number of times that that particular line was hit, and the third column is the code itself.
<solana_rbpf::vm::EbpfVm<solana_rbpf::user_error::UserError, solana_rbpf::vm::TestInstructionMeter>>::execute_program_interpreted_inner:
709| 886| fn execute_program_interpreted_inner(
710| 886| &mut self,
711| 886| instruction_meter: &mut I,
712| 886| initial_insn_count: u64,
713| 886| last_insn_count: &mut u64,
714| 886| ) -> ProgramResult<E> {
715| 886| // R1 points to beginning of input memory, R10 to the stack of the first frame
716| 886| let mut reg: [u64; 11] = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, self.stack.get_frame_ptr()];
717| 886| reg[1] = ebpf::MM_INPUT_START;
718| 886|
719| 886| // Loop on instructions
720| 886| let config = self.executable.get_config();
721| 886| let mut next_pc: usize = self.executable.get_entrypoint_instruction_offset()?;
^0
722| 886| let mut remaining_insn_count = initial_insn_count;
723| 2.16M| while (next_pc + 1) * ebpf::INSN_SIZE <= self.program.len() {
724| 2.16M| *last_insn_count += 1;
725| 2.16M| let pc = next_pc;
726| 2.16M| next_pc += 1;
727| 2.16M| let mut instruction_width = 1;
728| 2.16M| let mut insn = ebpf::get_insn_unchecked(self.program, pc);
729| 2.16M| let dst = insn.dst as usize;
730| 2.16M| let src = insn.src as usize;
731| 2.16M|
732| 2.16M| if config.enable_instruction_tracing {
733| 0| let mut state = [0u64; 12];
734| 0| state[0..11].copy_from_slice(®);
735| 0| state[11] = pc as u64;
736| 0| self.tracer.trace(state);
737| 2.16M| }
738| |
739| 2.16M| match insn.opc {
740| 2.16M| _ if dst == STACK_PTR_REG && config.dynamic_stack_frames => {
741| 6| match insn.opc {
742| 2| ebpf::SUB64_IMM => self.stack.resize_stack(-insn.imm),
743| 4| ebpf::ADD64_IMM => self.stack.resize_stack(insn.imm),
744| | _ => {
745| | #[cfg(debug_assertions)]
746| 0| unreachable!("unexpected insn on r11")
747| | }
748| | }
749| | }
750| |
751| | // BPF_LD class
752| | // Since this pointer is constant, and since we already know it (ebpf::MM_INPUT_START), do not
753| | // bother re-fetching it, just use ebpf::MM_INPUT_START already.
754| | ebpf::LD_ABS_B => {
755| 5| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(insn.imm as u32 as u64);
756| 5| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u8);
^2
757| 2| reg[0] = unsafe { *host_ptr as u64 };
758| | },
759| | ebpf::LD_ABS_H => {
760| 3| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(insn.imm as u32 as u64);
761| 3| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u16);
^1
762| 1| reg[0] = unsafe { *host_ptr as u64 };
763| | },
764| | ebpf::LD_ABS_W => {
765| 6| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(insn.imm as u32 as u64);
766| 6| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u32);
^2
767| 2| reg[0] = unsafe { *host_ptr as u64 };
768| | },
769| | ebpf::LD_ABS_DW => {
770| 4| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(insn.imm as u32 as u64);
771| 4| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u64);
^1
772| 1| reg[0] = unsafe { *host_ptr as u64 };
773| | },
774| | ebpf::LD_IND_B => {
775| 9| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(reg[src]).wrapping_add(insn.imm as u32 as u64);
776| 9| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u8);
^1
777| 1| reg[0] = unsafe { *host_ptr as u64 };
778| | },
779| | ebpf::LD_IND_H => {
780| 3| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(reg[src]).wrapping_add(insn.imm as u32 as u64);
781| 3| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u16);
^1
782| 1| reg[0] = unsafe { *host_ptr as u64 };
783| | },
784| | ebpf::LD_IND_W => {
785| 4| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(reg[src]).wrapping_add(insn.imm as u32 as u64);
786| 4| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u32);
^2
787| 2| reg[0] = unsafe { *host_ptr as u64 };
788| | },
789| | ebpf::LD_IND_DW => {
790| 2| let vm_addr = ebpf::MM_INPUT_START.wrapping_add(reg[src]).wrapping_add(insn.imm as u32 as u64);
791| 2| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u64);
^0
792| 0| reg[0] = unsafe { *host_ptr as u64 };
793| | },
794| |
795| 6| ebpf::LD_DW_IMM => {
796| 6| ebpf::augment_lddw_unchecked(self.program, &mut insn);
797| 6| instruction_width = 2;
798| 6| next_pc += 1;
799| 6| reg[dst] = insn.imm as u64;
800| 6| },
801| |
802| | // BPF_LDX class
803| | ebpf::LD_B_REG => {
804| 21| let vm_addr = (reg[src] as i64).wrapping_add(insn.off as i64) as u64;
805| 21| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u8);
^4
806| 4| reg[dst] = unsafe { *host_ptr as u64 };
807| | },
808| | ebpf::LD_H_REG => {
809| 4| let vm_addr = (reg[src] as i64).wrapping_add(insn.off as i64) as u64;
810| 4| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u16);
^1
811| 1| reg[dst] = unsafe { *host_ptr as u64 };
812| | },
813| | ebpf::LD_W_REG => {
814| 26| let vm_addr = (reg[src] as i64).wrapping_add(insn.off as i64) as u64;
815| 26| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u32);
^19
816| 19| reg[dst] = unsafe { *host_ptr as u64 };
817| | },
818| | ebpf::LD_DW_REG => {
819| 5| let vm_addr = (reg[src] as i64).wrapping_add(insn.off as i64) as u64;
820| 5| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Load, pc, u64);
^1
821| 1| reg[dst] = unsafe { *host_ptr as u64 };
822| | },
823| |
824| | // BPF_ST class
825| | ebpf::ST_B_IMM => {
826| 8| let vm_addr = (reg[dst] as i64).wrapping_add( insn.off as i64) as u64;
827| 8| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u8);
^1
828| 1| unsafe { *host_ptr = insn.imm as u8 };
829| | },
830| | ebpf::ST_H_IMM => {
831| 11| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
832| 11| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u16);
^6
833| 6| unsafe { *host_ptr = insn.imm as u16 };
834| | },
835| | ebpf::ST_W_IMM => {
836| 9| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
837| 9| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u32);
^6
838| 6| unsafe { *host_ptr = insn.imm as u32 };
839| | },
840| | ebpf::ST_DW_IMM => {
841| 16| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
842| 16| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u64);
^11
843| 11| unsafe { *host_ptr = insn.imm as u64 };
844| | },
845| |
846| | // BPF_STX class
847| | ebpf::ST_B_REG => {
848| 9| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
849| 9| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u8);
^2
850| 2| unsafe { *host_ptr = reg[src] as u8 };
851| | },
852| | ebpf::ST_H_REG => {
853| 8| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
854| 8| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u16);
^3
855| 3| unsafe { *host_ptr = reg[src] as u16 };
856| | },
857| | ebpf::ST_W_REG => {
858| 7| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
859| 7| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u32);
^2
860| 2| unsafe { *host_ptr = reg[src] as u32 };
861| | },
862| | ebpf::ST_DW_REG => {
863| 7| let vm_addr = (reg[dst] as i64).wrapping_add(insn.off as i64) as u64;
864| 7| let host_ptr = translate_memory_access!(self, vm_addr, AccessType::Store, pc, u64);
^2
865| 2| unsafe { *host_ptr = reg[src] as u64 };
866| | },
867| |
868| | // BPF_ALU class
869| 136| ebpf::ADD32_IMM => reg[dst] = (reg[dst] as i32).wrapping_add(insn.imm as i32) as u64,
870| 18| ebpf::ADD32_REG => reg[dst] = (reg[dst] as i32).wrapping_add(reg[src] as i32) as u64,
871| 94| ebpf::SUB32_IMM => reg[dst] = (reg[dst] as i32).wrapping_sub(insn.imm as i32) as u64,
872| 14| ebpf::SUB32_REG => reg[dst] = (reg[dst] as i32).wrapping_sub(reg[src] as i32) as u64,
873| 226| ebpf::MUL32_IMM => reg[dst] = (reg[dst] as i32).wrapping_mul(insn.imm as i32) as u64,
874| 15| ebpf::MUL32_REG => reg[dst] = (reg[dst] as i32).wrapping_mul(reg[src] as i32) as u64,
875| 98| ebpf::DIV32_IMM => reg[dst] = (reg[dst] as u32 / insn.imm as u32) as u64,
876| | ebpf::DIV32_REG => {
877| 4| if reg[src] as u32 == 0 {
878| 2| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
879| 2| }
880| 2| reg[dst] = (reg[dst] as u32 / reg[src] as u32) as u64;
881| | },
882| | ebpf::SDIV32_IMM => {
883| 0| if reg[dst] as i32 == i32::MIN && insn.imm == -1 {
884| 0| return Err(EbpfError::DivideOverflow(pc + ebpf::ELF_INSN_DUMP_OFFSET));
885| 0| }
886| 0| reg[dst] = (reg[dst] as i32 / insn.imm as i32) as u64;
887| | }
888| | ebpf::SDIV32_REG => {
889| 0| if reg[src] as i32 == 0 {
890| 0| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
891| 0| }
892| 0| if reg[dst] as i32 == i32::MIN && reg[src] as i32 == -1 {
893| 0| return Err(EbpfError::DivideOverflow(pc + ebpf::ELF_INSN_DUMP_OFFSET));
894| 0| }
895| 0| reg[dst] = (reg[dst] as i32 / reg[src] as i32) as u64;
896| | },
897| 102| ebpf::OR32_IMM => reg[dst] = (reg[dst] as u32 | insn.imm as u32) as u64,
898| 13| ebpf::OR32_REG => reg[dst] = (reg[dst] as u32 | reg[src] as u32) as u64,
899| 46| ebpf::AND32_IMM => reg[dst] = (reg[dst] as u32 & insn.imm as u32) as u64,
900| 16| ebpf::AND32_REG => reg[dst] = (reg[dst] as u32 & reg[src] as u32) as u64,
901| 4| ebpf::LSH32_IMM => reg[dst] = (reg[dst] as u32).wrapping_shl(insn.imm as u32) as u64,
902| 32| ebpf::LSH32_REG => reg[dst] = (reg[dst] as u32).wrapping_shl(reg[src] as u32) as u64,
903| 2| ebpf::RSH32_IMM => reg[dst] = (reg[dst] as u32).wrapping_shr(insn.imm as u32) as u64,
904| 4| ebpf::RSH32_REG => reg[dst] = (reg[dst] as u32).wrapping_shr(reg[src] as u32) as u64,
905| 54| ebpf::NEG32 => { reg[dst] = (reg[dst] as i32).wrapping_neg() as u64; reg[dst] &= u32::MAX as u64; },
906| 90| ebpf::MOD32_IMM => reg[dst] = (reg[dst] as u32 % insn.imm as u32) as u64,
907| | ebpf::MOD32_REG => {
908| 20| if reg[src] as u32 == 0 {
909| 6| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
910| 14| }
911| 14| reg[dst] = (reg[dst] as u32 % reg[src] as u32) as u64;
912| | },
913| 96| ebpf::XOR32_IMM => reg[dst] = (reg[dst] as u32 ^ insn.imm as u32) as u64,
914| 14| ebpf::XOR32_REG => reg[dst] = (reg[dst] as u32 ^ reg[src] as u32) as u64,
915| 59| ebpf::MOV32_IMM => reg[dst] = insn.imm as u32 as u64,
916| 7| ebpf::MOV32_REG => reg[dst] = (reg[src] as u32) as u64,
917| 15| ebpf::ARSH32_IMM => { reg[dst] = (reg[dst] as i32).wrapping_shr(insn.imm as u32) as u64; reg[dst] &= u32::MAX as u64; },
918| 236| ebpf::ARSH32_REG => { reg[dst] = (reg[dst] as i32).wrapping_shr(reg[src] as u32) as u64; reg[dst] &= u32::MAX as u64; },
919| 2| ebpf::LE => {
920| 2| reg[dst] = match insn.imm {
921| 1| 16 => (reg[dst] as u16).to_le() as u64,
922| 1| 32 => (reg[dst] as u32).to_le() as u64,
923| 0| 64 => reg[dst].to_le(),
924| | _ => {
925| 0| return Err(EbpfError::InvalidInstruction(pc + ebpf::ELF_INSN_DUMP_OFFSET));
926| | }
927| | };
928| | },
929| 2| ebpf::BE => {
930| 2| reg[dst] = match insn.imm {
931| 1| 16 => (reg[dst] as u16).to_be() as u64,
932| 1| 32 => (reg[dst] as u32).to_be() as u64,
933| 0| 64 => reg[dst].to_be(),
934| | _ => {
935| 0| return Err(EbpfError::InvalidInstruction(pc + ebpf::ELF_INSN_DUMP_OFFSET));
936| | }
937| | };
938| | },
939| |
940| | // BPF_ALU64 class
941| 16.7k| ebpf::ADD64_IMM => reg[dst] = reg[dst].wrapping_add(insn.imm as u64),
942| 26| ebpf::ADD64_REG => reg[dst] = reg[dst].wrapping_add(reg[src]),
943| 145| ebpf::SUB64_IMM => reg[dst] = reg[dst].wrapping_sub(insn.imm as u64),
944| 25| ebpf::SUB64_REG => reg[dst] = reg[dst].wrapping_sub(reg[src]),
945| 480| ebpf::MUL64_IMM => reg[dst] = reg[dst].wrapping_mul(insn.imm as u64),
946| 13| ebpf::MUL64_REG => reg[dst] = reg[dst].wrapping_mul(reg[src]),
947| 191| ebpf::DIV64_IMM => reg[dst] /= insn.imm as u64,
948| | ebpf::DIV64_REG => {
949| 5| if reg[src] == 0 {
950| 3| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
951| 2| }
952| 2| reg[dst] /= reg[src];
953| | },
954| | ebpf::SDIV64_IMM => {
955| 0| if reg[dst] as i64 == i64::MIN && insn.imm == -1 {
956| 0| return Err(EbpfError::DivideOverflow(pc + ebpf::ELF_INSN_DUMP_OFFSET));
957| 0| }
958| 0|
959| 0| reg[dst] = (reg[dst] as i64 / insn.imm) as u64
960| | }
961| | ebpf::SDIV64_REG => {
962| 0| if reg[src] == 0 {
963| 0| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
964| 0| }
965| 0| if reg[dst] as i64 == i64::MIN && reg[src] as i64 == -1 {
966| 0| return Err(EbpfError::DivideOverflow(pc + ebpf::ELF_INSN_DUMP_OFFSET));
967| 0| }
968| 0| reg[dst] = (reg[dst] as i64 / reg[src] as i64) as u64;
969| | },
970| 115| ebpf::OR64_IMM => reg[dst] |= insn.imm as u64,
971| 19| ebpf::OR64_REG => reg[dst] |= reg[src],
972| 93| ebpf::AND64_IMM => reg[dst] &= insn.imm as u64,
973| 19| ebpf::AND64_REG => reg[dst] &= reg[src],
974| 19| ebpf::LSH64_IMM => reg[dst] = reg[dst].wrapping_shl(insn.imm as u32),
975| 48| ebpf::LSH64_REG => reg[dst] = reg[dst].wrapping_shl(reg[src] as u32),
976| 4| ebpf::RSH64_IMM => reg[dst] = reg[dst].wrapping_shr(insn.imm as u32),
977| 5| ebpf::RSH64_REG => reg[dst] = reg[dst].wrapping_shr(reg[src] as u32),
978| 94| ebpf::NEG64 => reg[dst] = (reg[dst] as i64).wrapping_neg() as u64,
979| 141| ebpf::MOD64_IMM => reg[dst] %= insn.imm as u64,
980| | ebpf::MOD64_REG => {
981| 19| if reg[src] == 0 {
982| 4| return Err(EbpfError::DivideByZero(pc + ebpf::ELF_INSN_DUMP_OFFSET));
983| 15| }
984| 15| reg[dst] %= reg[src];
985| | },
986| 98| ebpf::XOR64_IMM => reg[dst] ^= insn.imm as u64,
987| 17| ebpf::XOR64_REG => reg[dst] ^= reg[src],
988| 89| ebpf::MOV64_IMM => reg[dst] = insn.imm as u64,
989| 10| ebpf::MOV64_REG => reg[dst] = reg[src],
990| 14| ebpf::ARSH64_IMM => reg[dst] = (reg[dst] as i64).wrapping_shr(insn.imm as u32) as u64,
991| 294| ebpf::ARSH64_REG => reg[dst] = (reg[dst] as i64).wrapping_shr(reg[src] as u32) as u64,
992| |
993| | // BPF_JMP class
994| 327k| ebpf::JA => { next_pc = (next_pc as isize + insn.off as isize) as usize; },
995| 116| ebpf::JEQ_IMM => if reg[dst] == insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^76 ^40
996| 131k| ebpf::JEQ_REG => if reg[dst] == reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^131k ^11
997| 163k| ebpf::JGT_IMM => if reg[dst] > insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^147k ^16.4k
998| 131k| ebpf::JGT_REG => if reg[dst] > reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^131k ^34
999| 65.5k| ebpf::JGE_IMM => if reg[dst] >= insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^65.5k ^8
1000| 65.5k| ebpf::JGE_REG => if reg[dst] >= reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^65.5k ^11
1001| 65.5k| ebpf::JLT_IMM => if reg[dst] < insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^65.5k ^3
1002| 6| ebpf::JLT_REG => if reg[dst] < reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^4 ^2
1003| 131k| ebpf::JLE_IMM => if reg[dst] <= insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^131k ^2
1004| 65.5k| ebpf::JLE_REG => if reg[dst] <= reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^65.5k ^2
1005| 3| ebpf::JSET_IMM => if reg[dst] & insn.imm as u64 != 0 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1 ^2
1006| 2| ebpf::JSET_REG => if reg[dst] & reg[src] != 0 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^0
1007| 196k| ebpf::JNE_IMM => if reg[dst] != insn.imm as u64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^196k ^3
1008| 131k| ebpf::JNE_REG => if reg[dst] != reg[src] { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^131k ^3
1009| 65.5k| ebpf::JSGT_IMM => if reg[dst] as i64 > insn.imm as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^65.5k ^6
1010| 14| ebpf::JSGT_REG => if reg[dst] as i64 > reg[src] as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^1 ^13
1011| 65.5k| ebpf::JSGE_IMM => if reg[dst] as i64 >= insn.imm as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^65.5k ^12
1012| 65.5k| ebpf::JSGE_REG => if reg[dst] as i64 >= reg[src] as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^65.5k ^4
1013| 131k| ebpf::JSLT_IMM => if (reg[dst] as i64) < insn.imm as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^131k ^20
1014| 147k| ebpf::JSLT_REG => if (reg[dst] as i64) < reg[src] as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^147k ^23
1015| 65.5k| ebpf::JSLE_IMM => if (reg[dst] as i64) <= insn.imm as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^65.5k ^4
1016| 131k| ebpf::JSLE_REG => if (reg[dst] as i64) <= reg[src] as i64 { next_pc = (next_pc as isize + insn.off as isize) as usize; },
^131k ^2
1017| |
1018| | ebpf::CALL_REG => {
1019| 0| let target_address = reg[insn.imm as usize];
1020| 0| reg[ebpf::FRAME_PTR_REG] =
1021| 0| self.stack.push(®[ebpf::FIRST_SCRATCH_REG..ebpf::FIRST_SCRATCH_REG + ebpf::SCRATCH_REGS], next_pc)?;
1022| 0| if target_address < self.program_vm_addr {
1023| 0| return Err(EbpfError::CallOutsideTextSegment(pc + ebpf::ELF_INSN_DUMP_OFFSET, target_address / ebpf::INSN_SIZE as u64 * ebpf::INSN_SIZE as u64));
1024| 0| }
1025| 0| next_pc = self.check_pc(pc, (target_address - self.program_vm_addr) as usize / ebpf::INSN_SIZE)?;
1026| | },
1027| |
1028| | // Do not delegate the check to the verifier, since registered functions can be
1029| | // changed after the program has been verified.
1030| | ebpf::CALL_IMM => {
1031| 17| let mut resolved = false;
1032| 17| let (syscalls, calls) = if config.static_syscalls {
1033| 17| (insn.src == 0, insn.src != 0)
1034| | } else {
1035| 0| (true, true)
1036| | };
1037| |
1038| 17| if syscalls {
1039| 6| if let Some(syscall) = self.executable.get_syscall_registry().lookup_syscall(insn.imm as u32) {
^0
1040| 0| resolved = true;
1041| 0|
1042| 0| if config.enable_instruction_meter {
1043| 0| let _ = instruction_meter.consume(*last_insn_count);
1044| 0| }
1045| 0| *last_insn_count = 0;
1046| 0| let mut result: ProgramResult<E> = Ok(0);
1047| 0| (unsafe { std::mem::transmute::<u64, SyscallFunction::<E, *mut u8>>(syscall.function) })(
1048| 0| self.syscall_context_objects[SYSCALL_CONTEXT_OBJECTS_OFFSET + syscall.context_object_slot],
1049| 0| reg[1],
1050| 0| reg[2],
1051| 0| reg[3],
1052| 0| reg[4],
1053| 0| reg[5],
1054| 0| &self.memory_mapping,
1055| 0| &mut result,
1056| 0| );
1057| 0| reg[0] = result?;
1058| 0| if config.enable_instruction_meter {
1059| 0| remaining_insn_count = instruction_meter.get_remaining();
1060| 0| }
1061| 6| }
1062| 11| }
1063| |
1064| 17| if calls {
1065| 11| if let Some(target_pc) = self.executable.lookup_bpf_function(insn.imm as u32) {
^0
1066| 0| resolved = true;
1067| |
1068| | // make BPF to BPF call
1069| 0| reg[ebpf::FRAME_PTR_REG] =
1070| 0| self.stack.push(®[ebpf::FIRST_SCRATCH_REG..ebpf::FIRST_SCRATCH_REG + ebpf::SCRATCH_REGS], next_pc)?;
1071| 0| next_pc = self.check_pc(pc, target_pc)?;
1072| 11| }
1073| 6| }
1074| |
1075| 17| if !resolved {
1076| 17| if config.disable_unresolved_symbols_at_runtime {
1077| 6| return Err(EbpfError::UnsupportedInstruction(pc + ebpf::ELF_INSN_DUMP_OFFSET));
1078| | } else {
1079| 11| self.executable.report_unresolved_symbol(pc)?;
1080| | }
1081| 0| }
1082| | }
1083| |
1084| | ebpf::EXIT => {
1085| 39| match self.stack.pop::<E>() {
1086| 0| Ok((saved_reg, frame_ptr, ptr)) => {
1087| 0| // Return from BPF to BPF call
1088| 0| reg[ebpf::FIRST_SCRATCH_REG
1089| 0| ..ebpf::FIRST_SCRATCH_REG + ebpf::SCRATCH_REGS]
1090| 0| .copy_from_slice(&saved_reg);
1091| 0| reg[ebpf::FRAME_PTR_REG] = frame_ptr;
1092| 0| next_pc = self.check_pc(pc, ptr)?;
1093| | }
1094| | _ => {
1095| 39| return Ok(reg[0]);
1096| | }
1097| | }
1098| | }
1099| 0| _ => return Err(EbpfError::UnsupportedInstruction(pc + ebpf::ELF_INSN_DUMP_OFFSET)),
1100| | }
1101| |
1102| 2.16M| if config.enable_instruction_meter && *last_insn_count >= remaining_insn_count {
1103| | // Use `pc + instruction_width` instead of `next_pc` here because jumps and calls don't continue at the end of this instruction
1104| 33| return Err(EbpfError::ExceededMaxInstructions(pc + instruction_width + ebpf::ELF_INSN_DUMP_OFFSET, initial_insn_count));
1105| 2.16M| }
1106| | }
1107| |
1108| 683| Err(EbpfError::ExecutionOverrun(
1109| 683| next_pc + ebpf::ELF_INSN_DUMP_OFFSET,
1110| 683| ))
1111| 886| }
Now we see that jump and call instructions are actually used, and that we execute the content of the interpreter loop significantly more despite having approximately the same amount of successful calls to the interpreter function. From this, we can infer that not only are more programs successfully executed, but also that, of those executed, they tend to have more valid instructions executed overall.
While this isn’t hitting every branch, it’s now hitting significantly more – and with much more interesting values.
The development of this version of the fuzzer took about an hour, so we’re at a total of one hour of development.
JIT and differential fuzzing
Now that we have a fuzzer which can generate lots of inputs that are actually interesting to us, we can develop a fuzzer which can test both JIT and the interpreter against each other. But how do we even test them against each other?
Picking inputs, outputs, and configuration
As the definition of pseudo-oracle says: we need to check if the alternate program (for JIT, the interpreter, and vice versa), when provided with the same “input” provides the same “output”. So what inputs and outputs do we have?
For inputs, there are three notable things we’ll want to vary:
- The config which determines how the VM should execute (what features and such)
- The BPF program to be executed, which we’ll generate like we do in “smart”
- The initial memory of the VMs
Once we’ve developed our inputs, we’ll also need to think of our outputs:
- The “return state”, the exit code itself or the error state
- The number of instructions executed (e.g., did the JIT program overrun?)
- The final memory of the VMs
Then, to execute both JIT and the interpreter, we’ll take the following steps:
- The same steps as the first fuzzers:
- Use the rBPF verification pass (called “check”) to make sure that the VM will accept the input program
- Initialise the memory, the syscalls, and the entrypoint
- Create the executable data
- Then prepare to perform the differential testing
- JIT compile the BPF code (if it fails, fail quietly)
- Initialise the interpreted VM
- Initialise the JIT VM
- Execute both the interpreted and JIT VMs
- Compare return state, instructions executed, and final memory, and panic if any do not match.
Writing the fuzzer
As before, I’ve split this up into more manageable chunks so you can read them one at a time outside of their context before trying to interpret their final context.
Step 1: Defining our inputs
#[derive(arbitrary::Arbitrary, Debug)]
struct FuzzData {
template: ConfigTemplate,
... snip ...
prog: FuzzProgram,
mem: Vec<u8>,
}
Step 2: Setting up the VM
fuzz_target!(|data: FuzzData| {
let mut prog = make_program(&data.prog, Arch::X64);
... snip ...
let config = data.template.into();
if check(prog.into_bytes(), &config).is_err() {
// verify please
return;
}
let mut interp_mem = data.mem.clone();
let mut jit_mem = data.mem;
let registry = SyscallRegistry::default();
let mut bpf_functions = BTreeMap::new();
register_bpf_function(&config, &mut bpf_functions, ®istry, 0, "entrypoint").unwrap();
let mut executable = Executable::<UserError, TestInstructionMeter>::from_text_bytes(
prog.into_bytes(),
None,
config,
SyscallRegistry::default(),
bpf_functions,
)
.unwrap();
if Executable::jit_compile(&mut executable).is_ok() {
let interp_mem_region = MemoryRegion::new_writable(&mut interp_mem, ebpf::MM_INPUT_START);
let mut interp_vm =
EbpfVm::<UserError, TestInstructionMeter>::new(&executable, &mut [], vec![interp_mem])
.unwrap();
let jit_mem_region = MemoryRegion::new_writable(&mut jit_mem, ebpf::MM_INPUT_START);
let mut jit_vm =
EbpfVm::<UserError, TestInstructionMeter>::new(&executable, &mut [], vec![jit_mem_region])
.unwrap();
// See step 3
}
});
Step 3: Executing our input and comparing output
fuzz_target!(|data: FuzzData| {
// see step 2
if Executable::jit_compile(&mut executable).is_ok() {
// see step 2
let mut interp_meter = TestInstructionMeter { remaining: 1 << 16 };
let interp_res = interp_vm.execute_program_interpreted(&mut interp_meter);
let mut jit_meter = TestInstructionMeter { remaining: 1 << 16 };
let jit_res = jit_vm.execute_program_jit(&mut jit_meter);
if interp_res != jit_res {
panic!("Expected {:?}, but got {:?}", interp_res, jit_res);
}
if interp_res.is_ok() {
// we know jit res must be ok if interp res is by this point
if interp_meter.remaining != jit_meter.remaining {
panic!(
"Expected {} insts remaining, but got {}",
interp_meter.remaining, jit_meter.remaining
);
}
if interp_mem != jit_mem {
panic!(
"Expected different memory. From interpreter: {:?}\nFrom JIT: {:?}",
interp_mem, jit_mem
);
}
}
}
});
Step 4: Put it together
Below is the final code for the fuzzer, including all of the bits I didn’t show above for concision.
#![no_main]
use std::collections::BTreeMap;
use libfuzzer_sys::fuzz_target;
use grammar_aware::*;
use solana_rbpf::{
elf::{register_bpf_function, Executable},
insn_builder::{Arch, Instruction, IntoBytes},
memory_region::MemoryRegion,
user_error::UserError,
verifier::check,
vm::{EbpfVm, SyscallRegistry, TestInstructionMeter},
};
use crate::common::ConfigTemplate;
mod common;
mod grammar_aware;
#[derive(arbitrary::Arbitrary, Debug)]
struct FuzzData {
template: ConfigTemplate,
exit_dst: u8,
exit_src: u8,
exit_off: i16,
exit_imm: i64,
prog: FuzzProgram,
mem: Vec<u8>,
}
fuzz_target!(|data: FuzzData| {
let mut prog = make_program(&data.prog, Arch::X64);
prog.exit()
.set_dst(data.exit_dst)
.set_src(data.exit_src)
.set_off(data.exit_off)
.set_imm(data.exit_imm)
.push();
let config = data.template.into();
if check(prog.into_bytes(), &config).is_err() {
// verify please
return;
}
let mut interp_mem = data.mem.clone();
let mut jit_mem = data.mem;
let registry = SyscallRegistry::default();
let mut bpf_functions = BTreeMap::new();
register_bpf_function(&config, &mut bpf_functions, ®istry, 0, "entrypoint").unwrap();
let mut executable = Executable::<UserError, TestInstructionMeter>::from_text_bytes(
prog.into_bytes(),
None,
config,
SyscallRegistry::default(),
bpf_functions,
)
.unwrap();
if Executable::jit_compile(&mut executable).is_ok() {
let interp_mem_region = MemoryRegion::new_writable(&mut interp_mem, ebpf::MM_INPUT_START);
let mut interp_vm =
EbpfVm::<UserError, TestInstructionMeter>::new(&executable, &mut [], vec![interp_mem])
.unwrap();
let jit_mem_region = MemoryRegion::new_writable(&mut jit_mem, ebpf::MM_INPUT_START);
let mut jit_vm =
EbpfVm::<UserError, TestInstructionMeter>::new(&executable, &mut [], vec![jit_mem_region])
.unwrap();
let mut interp_meter = TestInstructionMeter { remaining: 1 << 16 };
let interp_res = interp_vm.execute_program_interpreted(&mut interp_meter);
let mut jit_meter = TestInstructionMeter { remaining: 1 << 16 };
let jit_res = jit_vm.execute_program_jit(&mut jit_meter);
if interp_res != jit_res {
panic!("Expected {:?}, but got {:?}", interp_res, jit_res);
}
if interp_res.is_ok() {
// we know jit res must be ok if interp res is by this point
if interp_meter.remaining != jit_meter.remaining {
panic!(
"Expected {} insts remaining, but got {}",
interp_meter.remaining, jit_meter.remaining
);
}
if interp_mem != jit_mem {
panic!(
"Expected different memory. From interpreter: {:?}\nFrom JIT: {:?}",
interp_mem, jit_mem
);
}
}
}
});
Theoretically, an up-to-date version is available in the rBPF repo.
And, with that, we have our fuzzer! This part of the fuzzer took approximately three hours to implement (largely due to finding several issues with the fuzzer and debugging them along the way).
At this point, we were about six hours in. I turned on the fuzzer and waited:
$ cargo +nightly fuzz run smart-jit-diff --jobs 4 -- -ignore_crashes=1
And the crashes began. Two main bugs appeared:
- A panic when there was an error in interpreter, but not JIT, when writing to a particular address (crash in 15 minutes)
- A AddressSanitizer crash from a memory leak when an error occurred just after the instruction limit was past by the JIT’d program (crash in two hours)
To read the details of these bugs, continue to Part 2.