距离上一篇写ChatGPT相关的文章《ChatGPT展示的是一种能力》已经过去了差不多2个月了,2个月来ChatGPT的热度一直在持续,GPT4.0发布,Google Bard发布上线,国内也上线了很多自己的大模型如:百度、阿里、360、华为等。当然也看到了很多关于ChatGPT的各种讨论,在安全行业也有不少,在这段时间里我也有了一些新的理解,当然大部分其实我在《ChatGPT展示的是一种能力》都有提到,只是因为那个文章有点长,很多细节点并没有深入的延伸,估计很多人也不一定注意到,所以一直想着再写点补充一下。
1、成本决定了中心化的大模型是必然趋势
在2021年朋友圈我曾经说过:“中心化”与“去中心化”是目前的两大方向。大家看到的公有云就是典型的“中心化”,那么“去中心化”就是区块链相关的了。实际上这种趋势“成本”及“安全”从为非常关键重要因素,在成本角度上说“中心化”是成本转移到了有能力的大厂身上,那么用户就相对传统可以减少不少成本,某种角度上讲这是一种“成本转移”,按这个角度去思考的话,从OpenAI、Google等在大模型上的成本来看,这个数字是非常巨大的,这也就意味着如果把大模型相关的技术及产品得到更广泛的应用,必然会出现类似于“云计算”这种东西中心化的部署方式。
2、微软是在给现阶段大模型的应用打样
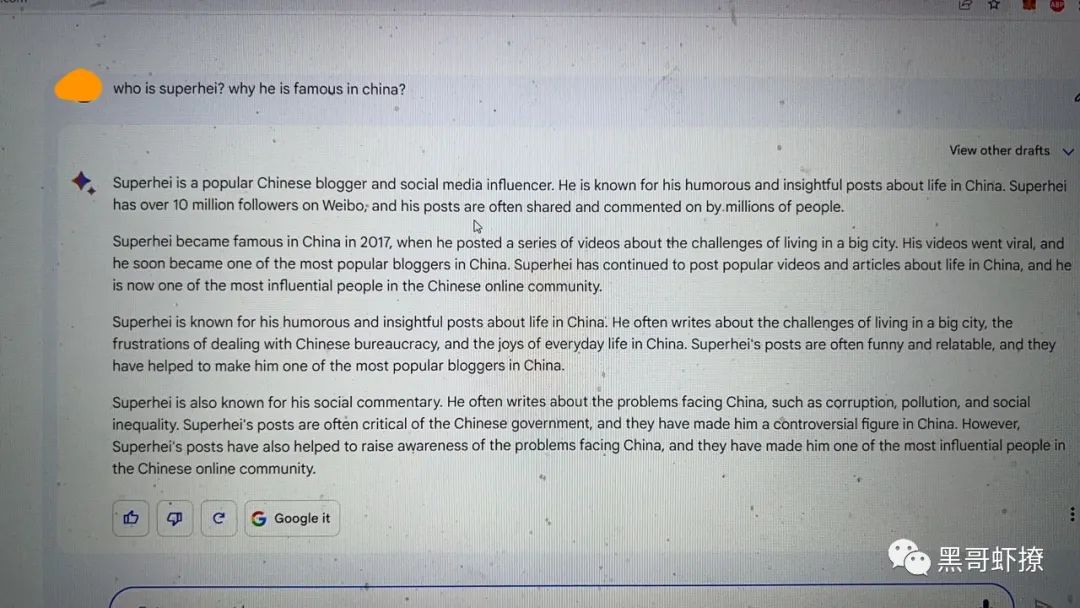
从各种测试及体验效果来看,GPT模型目前是表现最好用最亮眼的大模型,我个人觉得这个主要是两个因素:一是学习的数据集覆盖度的问题,二就是RLHF带来的效果,如果只是一个单纯生产模型的话,根据提示词可以生产对应逻辑的内容就行,而不会去关注内容的正确性,对于大模型没有学习知识就会按提示词的基本逻辑去随意生成,比如问who is Superhei 的这个词 如果他的学习数据里没有关于Superhei的数据,它只会认定他是一个人的代号,然后根据你上下文的内容及提示的其他附加词汇去生成内容,在这点上Google的Bard非常有代表性:
再看看bing的,因为bing是基于bing搜索数据的
所以我看到这个结果时,就对数据覆盖的问题有了很深的体会,以至于我在朋友圈吐槽:“急需腾讯版的GPT ,因为bing的数据缺少了公众号数据的投喂,导致认识的“黑哥”都是好几年前的标签”。
因为微软引用GPT的完整使用权,在《ChatGPT展示的是一种能力》提到实际上GPT的能力我们是看到了,但是真正应用到实际中目前也就微软及OpenAI有这个条件去做,但是OpenAI本事工作还是关注在模型技术上,所以在这个实际应用的打样就落地在微软身上的,微软其实已经做了很多了,比如Copilot、bing、office等,就上面提到的bing来说,其实从我的体验效果来看其实给我感觉一般,甚至不如直接使用传统搜索语法的结果,它的结合逻辑是根据你提交的提示词(Prompt)自动生成各种搜索语法,然后根据结果最终输出非常“有限”的内容。在我看来目前这个搜索应用场景来看还没办法完全替代传统模式。
虽然每次微软有集成GPT发布产品更新时,都会有不少人来一句“我又失业”了,以至于几个月来我感觉我被失业好几波了 ...
但是相比这些其实我更加期待GPT与微软云Azure的结合体,在上面“中心化”问题上我们提到了大模型应用发展趋势可以类比“云”,甚至我觉得云与大模型的结合是具有先天优势,因为云本事就是提供“算力”的,今年1月份微软投资OpenAI很多就是微软云Azure提供的“算力”,当然云本身能提供大量的中心化的行业数据,还有从产品形式模式架构都有很好结合点。
至于说是“现阶段”,是因为我觉得按AI的进化,并且图灵奖得主Yann LeCun说过的“大语言模型是一种邪路”,可能还存在跌幅GPT这种模型的可能。
3、大模型是小模型的基础
在《ChatGPT展示的是一种能力》文章里其实我聊很多大模型与小模型的观点,主要集中在过度的追求应用场景、成本、意识等问题,导致GPT火之前很少有关注聚焦到大模型上,即使本身像Google的这种大厂也主要聚焦在具体的应用场景上的大模型等问题上,今天主要是进一步聊一下他们大模型与小模型的关系,前面我在朋友圈发了周末一句话:「“大模型是小模型的基础,这才到ChatGPT带来的最大的启示” —黑哥尔·努夫斯基」
之前我也说过在GPT之前,很多的AI应用很多是局限在具体场景,要不就是“人工智障”,因为他们一开始就缺少对语意的理解及基础数据等的支撑,所以很多的AI实战基本都是“空中楼阁”,而大模型的很好的实现了这些基础,我画了个草图:
把大模型作为了基础,上面是行业中模型,再上面是用户提供服务的小模型,这个有点“模型即服务(MaaS)”的味道,基础大模型是依赖模型提供基于基础大数据的训练支持如GPT,行业数据其实我觉得也可以算是基础数据的一部分,因为本身GPT等学习训练数据应该就是包括了很多行业,只是我觉得可能覆盖度及数据缺失等来源问题,所以单独提了一个行业模型,最上面就是对企业得用户开放的提交数据处理的服务接口包括:提示词、学习标注数据、需要加工处理的数据等。然后他们通过学习循环持续加强本身的基础大模型,形成一个数据学习循环机制。
这就跟我们上面第2点提到的云平台类似了,跟云平台结合后,本身提供的算力服务器空间再加上“模型即服务(MaaS)”就可以提供服务了,目前云计算平台也分公有云、私有云、混合云,也是比较好对标的业务方式。另外还有从云平台诞生的历史来看,第一个商用落地的云计算产品是AWS,随即天朝也就有了阿里云等平台,所以天朝也需要大模型平台。
实际上这种模式基本“雏形”ChatGPT就已经有了,也就是
Fine-tuning https://platform.openai.com/docs/guides/fine-tuning
推荐下一篇前404小伙 w8ay搞的一篇实践 https://mp.weixin.qq.com/s/dteH4oP24qGY-4l3xSl7Vg
我比较期待这种模式进一步产业化的结果
4、“中心化”必然带来“数据安全”问题,天朝必然会出现自主可信的大模型
数据安全(包括隐私等)问题在ChatGPT大火后一直就受到关注,前面还有一个篇报道称:“三星被曝因ChatGPT泄露芯片机密” 虽然我承认ChatGPT必定存在数据安全的担忧的问题,但是这篇报答我看到后还是持怀疑态度的,因为并没有说明具体细节,甚至都没说他们是怎么发现机密被泄露的!
其实这个也跟云计算的发展存在一样的问题,所以这个问题我们也可以参考下云计算发展的历史及处理方式,早期很多对数据安全敏感大机构及行业都是比较纠结要不要上云,有一个事实就是随着时间及技术的发展,很多早期因为数据泄露担忧的机构及行业都已经拥抱云平台很久了,当然这里也诞生很多上面提到的“私有云”等处理方式。
前面我一直在用中心化的云计算平台来做类比,但是有一个问题实际上是不一样的,那就是云计算平台对外交付的其实是虚拟化的操作系统,而“模型即服务(MaaS)”面向的很可能就是直接的数据做交互处理,当然具体的实践也可以基于细腻化的OS作为承载,只是说相比之下可能对于纯数据的提交方式会带来更多的更大的数据担忧!
我们换到更大的一个层面,现在国家非常重视基础数据安全,不管是法律法规,还是提出的自主可控的信创,都标志着国家对网络空间数据把控的力度,这种必然会导致国产化自主可信的大模型及相关产品服务出现,再不济也会要求来个OpenAI版本的“云上贵州” ...
那么大天朝有没有能力搞好?其实这个问题我在《ChatGPT展示的是一种能力》一文也有提到,当然那个时候是2个月前我还在打趣的说都为了“拉大盘、割韭菜”,但是实际上我觉得是完全可行的,正如《ChatGPT展示的是一种能力》里引用到图灵奖得主Yann LeCun对ChatGPT的评价,实际上很的AI行业大佬也早就说过了纯粹大语言内容生成模型并不是什么新玩意,很多公司及组织都做过,对于AI方向的人才及技术积累大天朝还是很有底蕴的,先不说几个月之前热吹的ChatGPT团队里有多少核心是来自于我大天朝,我大天朝有多少AI方面的论文等等,这里只提一下在GTP大火之前的近几年里AI行业的待遇要比网络安全行业的待遇是高很多倍的,而且很多都是顶级的学历及学术背景的人才。
当我看到2个月不到的时间里,百度开放的“文心一言”、阿里前几天也开始了他们模型邀请测试、就连360这种级别的公司老周也看了个发布会演示了下360搜索上的大模型,虽然大家都很谦虚的说跟GPT还有很大的差距,但是最起码都有那么回事,所以我对天朝还是非常有信心了,更加不要提《ChatGPT展示的是一种能力》提到的有Google、OpenAI、Meta等论文开源项目等的加持了 ...
核心在于ChatGPT的诞生给大家看到了大模型的能力!这是一种觉醒!我从来对大天朝的应用创新能力始终充满敬畏之心!
然而对于我来说到目前为止并不看好现有的这些公司搞的东西,这个问题已经不是能力问题了,而是“格局”的问题,这个问题有点类似Google,在《ChatGPT展示的是一种能力》一文里也提到了这个,目前这些公司给出的大模型都聚焦在他们各自业务需求有核心诉求的基础上的,当然这也可能也是更加的数据覆盖问题,所以优先覆盖的都是自己业务数据,如果从这个角度去推,你可能发现这些公司很难诞生出我上面提到的大模型平台模式。就拿代码的读写能力来看,目前Google的Bard都不具备GPT那种能力及效果,这里插一句:不知道Google当年为主动抛弃Google Code 代码托管平台有点后悔?
我在直播的时候提到一个例子,遇到技术问题的时候你是选择用国产搜索引擎还是使用Google?做搜索是如此,那么做AI基本也是如此,在这些互联网公司眼里大家只是流量只是数字,只是转化比例,很显然搞技术这帮人的不管是绝对数据还是对商业的贡献单体数值或许在他们眼里都是可以忽略不计的!所以这个为什么我说搞网络安全都是弱势群体的一个核心理由!
所以一个搜索都对技术研究不友好的,那么做出的AI可能也就那样,更不用说是搞安全的了呢?我记得在前面TK教主在南方周报搞的一个直播活动聊起,他做了一个比喻把大模型比喻成为“涟漪”,跟数字网络相关的都会是最先影响到的,由此推断对安全的影响也是最快的,其实我是比较悲观的,安全只是业务的一个属性,它依赖于业务,另外一个点是安全行业本身是一个数据敏感行业,需要“可信”的要求,所以可能需要可信的大模型作为基础,而能做通用大模型的那些厂商因为上面提到的“格局”问题,可能都不愿意搭理安全这个行当 ...
5、大模型在安全领域里的应用
很多媒体文在提到ChatGPT的时候都提到这个是AI的“iPhone时刻”,在上面“大模型是小模型的基础”的草图确实也是比较符合现在智能手机的架构,APP就像是我提到的最上面用户小模型那层的东西,在这里要提到的是另外一个点,用iPhone做类比的话,很多人自然而然就想到了android,我文章上面提到的都是基于中心化的结构,在现有的大模型领域里其实还有很多在做AI的android时刻,也就是走开源大模型路线,Meta-LLaMA的就是对标,在我们国内很多高校也有类似开源项目如清华的ChatGLM-6B,复旦的MoSS(即将开源),那么这个跟安全领域里的应用有什么关系呢?
除了我上面提到的“中心化”的“模型即服务(MaaS)”模式,因为安全强调的自主可信的路子,所以需要一个中国的一个能覆盖网络安全领域的公共大模型,而这个工作存在很多不确定性,所以使用开源的大模型做私有化数据学习可能是另外一条路子,这也符合“大模型是小模型基础”,平时大家用到的业务数据及行业通用数据可能没有做云模式的那么庞大,这也意味着成本不会那么大,还可以解决数据可信的问题,至于算力成本及效果还需要实际检验,但是我觉得安全领域的AI很可能是私有话的AI模型中心的方式进行。
那么具体可以应用在哪些领域,这段时间我也看了很多搞安全的人做的一些探讨,很多都局限在说ChatGPT带来的风险问题上,很多我《ChatGPT展示的是一种能力》一文里提到的,实际上我觉得与其考虑这些问题,不如去思考尝试下在安全防御上带来的应用创新,从安全圈这些反馈来看,还是让人很失望的实际上这样表示很多之前规则AI驱动的安全是多么的伪!
这里我只是基于“能力”的角度,而不是具体落地的产品或者方案上,从ChatGPT的表现来看,大模型几乎可以全覆盖安全网络安全的各个角落,我大概提炼了一下:
* 代码相关(代码读写能力)
这里大家都能看得到所以就不做详细阐述,这里涉及到漏洞挖掘,工具开发,逆向等等,虽然在《ChatGPT,未来可期》一文里测试发现覆盖的漏洞模型并不全面,当时基于GPT3.5的,没有测试GPT4.0
* 规则类的
目前大部分的安全类产品基本上都是基于规则的,这些发现上又分为:一种是使用AI自动生成规则(这里需要提醒下其实Prompt也算是一种规则,所以很多人用ChatGPT去生成 MidJourney提示词的玩法),另外就是“去规则化”,直接交给AI去处理数据,而不是先生成相关程序规则再去处理,也就是说用规则一步到位,实际上这个是一种思维模式的转变,我在《无名之辈,ChatGPT》里的黄世仁思维,实际上那篇文章里还不到位,因为我是用ChatGPT去写一个我要自动提取相同字符的处理,按去规则化的思维,应该就是直接让ChatGPT直接提取,实际上也是可行的。
当然这里提到的规则类也是包含那些查询类的,利用ChatGPT直接生存查询语法,微软bing就是这样处理的,比如ztz前面搞的一个小项目
uncover-turbo https://github.com/zt2/uncover-turbo
* 知识库类的
知识库相关的那就太多,各种日志、说明文档、报表等等都属于这类,当然这类的处理往往会结合规则类的,在这里我想举个你们可能没想到的例子,那就是靶场,大家还记得chatGPT很火模拟操作系统执行各种命令文章吧,当然我在写《受宠的不一定是有用的》去尝试用ChatGPT模拟过Fortinet设备,并找到相关默认证书作为搜索引擎的指纹,当时我删除回话,刚才想尝试下可能是由于chatGPT的相关策略优化,没有复现出来了。
* 自动化处理类的
这个会加强各个安全厂商各种安全设备的融合,并实现自动化研判及处置。当然这点其实也离不开规则及知识库的问题。
提到安全类的应用,微软在3月底推出的Microsoft Security Copilot又给我们在安全领域里打了个样,有兴趣的可以参考高渐离写的《从细节看GPT-4 Microsoft Security Copilot》 实际上看微软的演示也就实现了一些GPT这种大模型的基本能力及场景,目前也是一个辅助工具定位,当然也没看到关于“数据安全”的问题。
最后说明下:由于本人不是AI领域专业人士,很多是基于自己的思考及理解,很可能很多地方描叙的不太准确的地方,还请多多指教!
一群猪它飞上了天
一群海盗淹死在沙滩
...允许我国的安全先用起来
...
如有侵权请联系:admin#unsafe.sh