从人们开始探索代码扫描这件事情开始,市面上就在不断地诞生着各种各样的工具,经过了几年的演变以及发展,对于白盒代码扫描这件事情来说,大家的观念也在逐渐趋同。
无论是基于IR(Intermediate Representation)、AST(abstract syntax trees)、CFG(control flow graphs)、PFG(program dependence graphs),又或者是其他的什么中间态。白盒代码扫描工具都在这个基础上做模拟执行、污点传播等等方案来分析挖掘漏洞。
而随着CodeQL的概念逐渐被大家接受之后,现在的代码扫描工具越来越趋近于将底层和上层拆解开来,由底层的引擎将代码统一化处理,然后使用者在上层通过编写规则或者语句就可以。主流的CodeQL、Checkmarx其实都使用了类似的方案。今天要说的Joern也是如此。
今天介绍的Joern有什么特殊的呢?
首先CodeQL本身不开源只能使用,偏偏微软还做了商业化限制,以微软喜欢秋后算账的风格来讲,实在无法确定深入研究CodeQL是否值得。
除此之外,市面上的很多白盒扫描工具其实是非静态的,扫描的时候不但需要配置复杂的运行环境,而且本身可能依赖编译过程,无论是自己使用还是商业化这都非常不实用。
个人认为白盒工具有着几个很重要的点
静态扫描,静态扫描的优势和便利程度才是白盒比较优势的一环,毕竟白盒不是灰盒,如果对编译环境和运行环境有依赖那为什么不使用更准确的灰盒
扫描速度,虽然这点是很多商业化白盒软件的通病,但无论在哪家公司的DevSecOps中,最终目标肯定是把安全检测加载上线前,那么无论是1分钟、3分钟还是5分钟,扫描速度会是第一优先级,比如CheckMarx动辄几小时的扫描肯定是不现实的
可diy性,当然对于大部分人来说这点其实并不是很重要,但能对引擎进行深入改造会是优化开发非常重要的一点,joern是开源的,在这方面他有很大的优势
可拓展性,市面上大部分的白盒扫描工具动辄支持几十种语言,比如说snoarqube这种,但实际上大部分拓展语言只支持非常简单的正则拓展,我一直觉得现代白盒软件很重要的一条路就是走通用性,这也是比较有名的一些白盒工具都选择的路,在白盒扫描过程中会刻意将统一结构拆分出去再做分析扫描。
今天介绍的joern的其实就是这类工具的一员,他最大的特点其实就是开源。
joern是ShiftLeft 开发的一款基于CPG制作的白盒静态扫描工具,诞生的时间不算早应该就是2021年(具体记不清了)
https://github.com/joernio/joern
和其他工具不同,他引用了一种叫做CPG(Code Property Graph)的中间结构作为处理结构,是由AST + CFG + PDG叠加而来,最终生成一张图,然后在图的基础上做分析和检测。和传统的基于单一AST或者CFG的工具相比,图结构一方面能承载更多的代码信息,另一方面,CPG也让后续的分析程序更具有通用性。
这就是一张很经典的范例图,用来展示CPG和其他几种的区别。
另一方面,在用户使用的Joern命令行上,Joern构建了一套基于OverflowDb的查询语言以供使用者可以在不需要知晓底层原理的基础上查询分析。
至于OverflowDB具体是什么,不是很关键,我们只需要了解joern就行了。
关于CPG可以看一篇官方写的基础的理论文章。
https://blog.shiftleft.io/why-your-code-is-a-graph-f7b980eab740
以下部分内容大量取材于上面这篇文章。
还有就是比较重要的joern的CPG标准文档
https://cpg.joern.io/
https://github.com/ShiftLeftSecurity/codepropertygraph
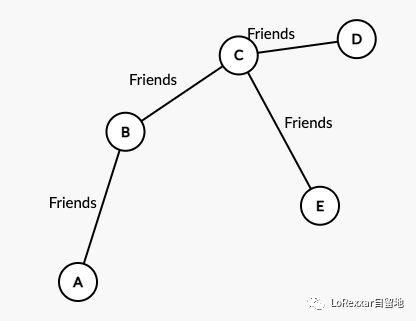
在介绍CPG之前,首先要先对图结构有个基础的概念,无论是图数据库又或者是图结构其实说白了就是把节点以及节点之间的关系以图的方式展示出来。就比如下图表明A和B就是朋友,B和C也是朋友。
换到代码中说白了就是通过图的方式展示代码中不同节点之间的关系,而这个节点可能是代码块,可能是函数块,可能是变量块,他们之间会通过边的属性来展示节点之间的关系。
而代码在编译执行前会经过几个复杂的步骤,在经过最简单的词法分析和语法分析,代码就会被转为AST(abstract syntax trees)也就是抽象语法树,这也是普遍会用到的通用结构,因为从AST开始不同语言的差异就是就很小了,也会有非常标准的结构。
AST则是一个经典的树结构,这算是数据结构当中非常经典的一个,通过遍历树结构我们就能得到更底层的某种结构,比如IR就是这类结构的一种,这种结构会具有更强的执行顺序,相应的也会模糊掉一些语法。
而CFG(control flow graphs)是一种更强调执行流的结构,节点和节点之间只有调用关系,而且会有比较强的代码执行顺序,边上会展示执行相应的条件。
而另一个比较有用但是比较少见的就是PDG(program dependence graphs),PDF也是一种图关系,通过图来展示代码节点之间的依赖关系,他更强调的是节点和节点之间的关系,节点之间的边会展示数据节点的影响关系,所以图结构会更复杂,但会更易于寻找节点之间的关系。
下面这张图就是一张PDG,上面的两个对于x和y的定义会单向影响后续节点的变化,这种联动关系很清晰,这就是PDG的优势。
但无论是AST、CFG、PDG或者是IR等数据结构,又或者是某个原创的中间结构,他们的目标都是一致的,就是用更通用的方式解释代码,这整体可以算作编译原理的前端。它本质上没有实际的区别,无非就是哪种通用结构被拿来做代码分析。
而CPG在这个环境下主体由AST、CFG、PDG多种结构融合而来,我觉得它最大的特点就是利用了图结构庞大的信息容纳能力(毕竟图本身并不是二维的,图结构可以很复杂),可以保证我们在代码分析中遇到任何情况都可以在CPG中找到相应的答案和场景。这是图结构相比其他中间结构解决方案难以比拟的优势。
而joern作为一个白盒的代码分析工具,主要做了两部分。
第一部分是实现了一种方案来比较通用的代码转CPG,他的原理也很简单,用已经有的某个组件来实现语义分析部分,然后把不同的AST转成统一的AST,最终转成目标CPG。
而第二部分就是,在已有的CPG基础上,实现了一套查询语法,类似CodeQL,这种,允许通过这种语法来构造不同的查询逻辑实现最终的目标
> def source = cpg.identifier.typeFullName(".*HttpServletRequest.*")
> def sink = cpg.call("exec|eval").argument
> sink.reachableBy(source)拿上面这段代码举例子就是,寻找java当中的代码执行漏洞范围,通过简单的指定source和sink就能实现漏洞挖掘,中间的步骤被封装起来。
它同样支持你使用复杂的Scala脚本进行代码的扫描和处理。通过Scala可以实现更复杂的查询和数据流分析。
相比其他的某个白盒工具来说,joern的优势有一点儿非常特例,这点在CodeQL中也有很强烈的体现,就是大部分的白盒扫描工具对于底层的包裹非常严密,很多工具你只能简单的拿来扫描漏洞。
一方面你无法清楚的知道,从这次扫描中你做了什么事情得到了什么东西,甚至无法知道这些漏洞是怎么被扫描或者是没有被扫描到。
另一方面,如果你的目标并不是单纯的扫描漏洞,而是想要通过工具辅助分析代码,比如想知道某个函数如何访问到,这种问题大概率没有答案。
如果对Joern的设计理念感兴趣,可以看看设计者写的文章
https://blog.shiftleft.io/semantic-code-property-graphs-and-security-profiles-b3b5933517c1
或者看看设计师的PPT
https://github.com/joernio/workshops/blob/master/2021-RSA/RSA-LAB2-R08.pdf
根据官网的文档,我们可以快捷的安装joern环境
https://github.com/joernio/joern
wget https://github.com/joernio/joern/releases/latest/download/joern-install.sh
chmod +x ./joern-install.sh
sudo ./joern-install.sh
joern ██╗ ██████╗ ███████╗██████╗ ███╗ ██╗
██║██╔═══██╗██╔════╝██╔══██╗████╗ ██║
██║██║ ██║█████╗ ██████╔╝██╔██╗ ██║
██ ██║██║ ██║██╔══╝ ██╔══██╗██║╚██╗██║
╚█████╔╝╚██████╔╝███████╗██║ ██║██║ ╚████║
╚════╝ ╚═════╝ ╚══════╝╚═╝ ╚═╝╚═╝ ╚═══╝
Version: 2.0.1
Type `help` to begin
joern>
windows也可以用同样的方式安装,当然你需要有能跑sh的环境和wget/curl。
如果需要做joern做二次开发,还需要下载idea的scala插件
https://plugins.jetbrains.com/plugin/1347-scala/versions/stable
joern的使用方法算是比较简单但是怎么用就要看需求了,可以多关注官网提供的很多查询语句帮助理解
https://queries.joern.io/
这里我们下一个java-sec-code作为范例代码
https://github.com/JoyChou93/java-sec-code
导入到joern的方式也很简单
在运行代码的时候joern也给出了提示,如果想要扫描特别大的项目,建议把前端的cpg转化过程拆分出去。
javasrc2cpg.bat -J-Xmx8092m ../../java-sec-code/ --output D:\program\joern\joern-cli\workspace\java-sec-code\cpg.bin.zip然后在打开joern后将刚才生成的cpg导入进来
importCpg("path/to/cpg")但其实这个转化CPG的过程不会太慢,因为Joern为了优化这个速度,是把转化和连接这两部分拆开做的,换句话说,就是第一步只是把代码转成了CPG,而其中节点之间的关系并不会在转化过程中连接,而是在语句查询过程中完成,这大大节省了扫描所需的时间。
这里转化的CPG会存在workspace里,用workspace命令可以看到之前转过的所有cpg。
你可以用openroject(java-sec-code)来切换当前激活的工作区
这里最终生成的cpg变量就是代码的CPG,所有的代码数据都会存在这个变量,比如cpg.metaData就是基础元数据,一般来说后面会加个.l,这个l就是tolist,结果会转成list格式。
比较重要的一点是,joern的shell模式为了易用性是优化了tab的,如果不知道命令可以多tab补全命令,会有一个实时的补全,很实用。
通过method可以获取cpg中的所有方法,并获取节点的详细信息。
cpg.method.take(1).l信息太多,你还可以构造返回的map结构,比如行号,方法名,对应的代码。
cpg.method.map(n=>List(n.lineNumber, n.name, n.code)).take(1).l查询调用了getRequestBody的方法,并获取文件名、行数、方法名
cpg.method.name("getRequestBody").caller.map(n=>List(n.filename, n.lineNumber, n.fullName, n.code)).l这里第一行就表示,在XStreamRce.java这个文件的23行调用了getRequestBody这个函数。当然这里我们仅仅找到了一个入口,想要确定这是否可能是个问题,还需要追这个入口(source)是否可以通往敏感函数点,那我们就需要对数据流做分析了。
首先我们需要知道如何访问到调用了getRequestBody的方法,由于这是个SpiringBoot项目,所以可以从@RequestMapping的注解入手,先查询出所有的web入口。
cpg.method.where(_.annotation.name(".*Mapping")).map(n=>(n.name, n.annotation.code.l)).l然后我们可以在@RequestMapping的节点和调用getRequestBody的方法节点中间寻找路径,在Joern它提供了两个方案
正向搜索,从每一个RequestMapping的节点向下搜索寻找有没有调用getRequestBody方法的节点
cpg.method.where(_.annotation.name(".*Mapping")).repeat(_.callee)(_.until(_.name("getRequestBody"))).l反向搜索,从调用getRequestBody方法的节点向上搜索寻找@RequestMapping的注解
cpg.method.name("getRequestBody").repeat(_.caller)(_.until(_.annotation.name(".*Mapping"))).l关于正向搜索和反向搜索的优劣其实没有特别简单的优劣性,最简单的一个方式是从少的节点往多的节点找,这是最简单的也最不容易浪费资源,只需要执行少的节点数量次数即可。
这里使用的语法是repeat...until...语法,大意是一直向上寻找调用上级/下级,直到满足某个条件为止。
上面的语法只是显示了满足条件的节点,但真正到漏洞挖掘中,我们必须在source和sink中找到数据流才行,当然在Joern中这个也给了非常简单的基础使用方法,也就是reachableBy。
这里用一个比较简单的例子,是java-sec-code最简单的rce例子
首先我们指定exec调用点为sink,然后照例指定含有Mapping注解的方法参数为source
def source = cpg.method.where(_.annotation.name(".*Mapping")).parameterdef sink = cpg.call.name("exec")
然后直接用reachableBy来做数据流分析获取
sink.reachableByFlows(source).p可以看到这里已经找到了刚才那条数据流。
当然静态分析远不止这么简单,是否有效,是否被过滤都是问题,而且数据流当中也会有复杂的问题变化,而joern在这方面是提供了sc脚本的方案来构建复杂的查询逻辑。
./joern --script test.sc --params cpgFile=/src.path.zip,outFile=output.log这部分的内容后面再讲
如有侵权请联系:admin#unsafe.sh