关于安全运营其实已经有很多的文章去写了,很多企业在多年前就或早或晚的进入了运营时代。得益于我自己经历过几次0-1的安全建设,本文且从团队和架构的角度回过头再看一看SOC的相关设计。经验有限,请运营的大佬们轻拍。
另外大家可以带着疑问去阅读后面的内容。比如你买了很多产品、软件、设备,有没有真正的用起来?什么时候需要成立/拆分出SOC团队了?安全平台工程师和安全运营工程师需不需要互相training?你定了很多运营指标,是不是真的能够反映运营质量?工程师写了几十上百条规则,有哪些被触发了?
1.1 团队协作
基本上安全团队在搭建完基础设施之后,就开始进入到运营阶段,随后运营团队规模逐渐扩大,安全负责人很快被各种各样的看板淹没。至于是否能够理解和衡量运营团队的质量,我们后面再说。先看一下SOC团队的大概样子,从响应流程上来说通常会有Tier 1到Tier 3。从职责上来看,大型的SOC team一般会负责监控运营,红蓝对抗,威胁智能,取证应急这几大块。至于Team够不够大,就要看SOC的Leader是Manager还是Director了。
从能力成熟度模型上CMM-SOC来说,一个可正常运营的SOC至少需要具备Level 2的相关特性。往往大厂的SOC已经在Level 3了(起码宣传上至少已经在Level 3 之上了,记得之前阿里某安全专家已经开始提出了数智化安全运营的概念。),并且具备7*24的oncall能力,也能和NOC联动处置一些问题。
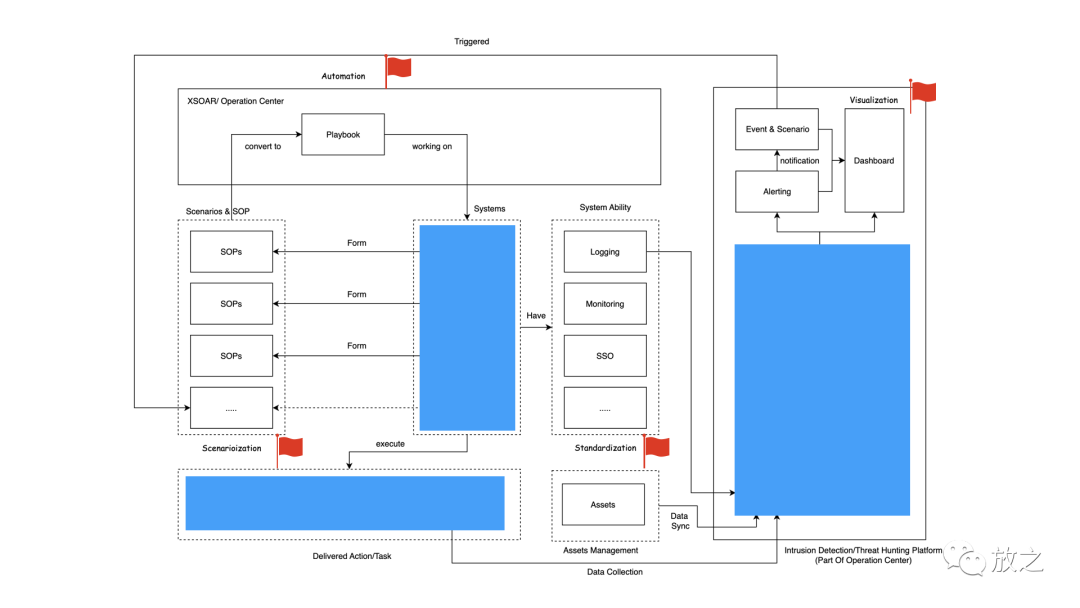
至于协作流程,此处依旧采用上篇博客 里的图。这里面的system一般是安全运维负责维护稳定性,平台工程师负责开发新的系统或者整合系统,数仓建设来自风控或者数据中心团队,安全运营需要事件流程,监控告警等等。以及与此对应的安全BP,作为接口人快速处理到业务条线上的问题。
当然这些取决于企业的组织架构,不同的组织架构配合起来的方式肯定不尽相同。总体来说都是有专门的团队维护平台及产品,让运营能够专注于自动化场景化的事件检测。当然也有的SOC团队可能只是个告警运营团队,那这种团队的可替代性就非常强,一般由甲方外包的乙方驻场。
1.2 数据平台
数据计算平台是运营过程中至关重要的,大部分安全运营工程师的工作都应该在这上面。通过对Data Sources进行Batch Ingestion并将其存储到Data Lake,现在云上的Blob Storage,都已经能够承担数据湖的角色,以AWS为例,可以用Redshift也可以用S3。之后对数据进行清洗,一般是在一个Pipeline内完成清洗,标准化以及验证。这里需要指出的是在标准化的过程中需要数据字典,能够将不同的字段统一mapping成预设字段(标准数据字典的建立也需耗精力)。
之后就可以写规则了,规则除了作用在各自单独的系统之外,最多的产出地就是在数据计算平台,后面也会讲一下衡量运营的指标。Spark配Groovy去写是OK的,Splunk自带的SPL也是OK的。当然这些大多是基于条件规则,如果说要采用一些机器学习的方法就需要另一个关键的过程——特征工程(话说实际除了商业产品自带的机器学习之外,我并没有在大厂之外看到能用机器学习/深度学习做入侵检测的)。特征工程简单的可以理解为一个多项式函数的系数集合。挖掘特征可以通过专家经验,也可以让神经网络自动去寻找。我已经有一段时间没关注过这一块了,翻了翻之前的特征工程笔记还是2018年的。最后通过对模型训练及验证(tarin & evaluate)后进行部署并对外提供API接口。一方面可以通过API消费模型,一方面可以完成可视化,以及完成自动化等。在数据计算平台这里还可以引入很多外部数据,例如购买的Threat Intelligence,目前Splunk Enterprise Security就支持类似的功能。不过需要注意TI是按查询次数收费的,可以适当的缓存名单数据24h内的重复查询。并提供给其他系统使用。(BTW:Virustotal的工程师嘲讽某步是盗用他们的数据)。
注:我对以Hadoop为底层实现数仓没有实际的架构经验,工作中也仅使用过ODPS、SLS和Splunk、Groovy、Spark。云上的方案只做过AWS和Azure的POC,并不清楚具体在生产环境的容量和性能表现。(理论上来说,云上只需要加大充值就可以实现具体的性能,架构本身不受影响)
1.3 运营质量
假设我们以数据驱动(data-driven)安全运营为原则,把自动化,标准化,场景化,可视化作为目标。(往往缺什么,越喜欢强调什么😓)
过程
我们用IPDRR模型来表示过程,并把安全运营可能涉及到的内容mapping进去。如图所示,安全运营在识别过程主要会做资产管理和风险评估(这个评估标准需要由治理或架构团队提供)。在防御过程会涉及到安全控制的实施,规则的开发等等,类似的在后续过程进行实时的监控告警,事件管理,灾难恢复等。另外我们还可以换个视角,例如以Detect视角看IPDRR。
Identify过程其实就是做Threat Modeling,Protect过程就要去做一些Rule Tuning的工作(设备和服务提供的职责由安全运维或安全平台组提供),以及等等。
指标
如何衡量运营的质量,需要有指标评估。在以上的过程,除了MTTA,MTTD,MTTR,还需要通过关注以下实体的指标去衡量SOC运营的质量。可以看到这里有告警、事件、SOP、规则、Playbook等实体,这里我们关注除System以外的实体(System有另外的指标,这里仅关注SOC运营时的指标)。
例如:Volume(总量、新增量)、Accuracy(T-P、 F-P、T-N、 F-N)、 Priority(P0事件 - PN事件)、 Cost(时间/开发时间,溯源时间等、人力)。
在这个过程可以考虑每个实体的准确率。例如告警里有多少正确的,Playbook有没有正确执行等等。各个的总量以及新增数量(一旦这些数据接入了数据平台,只需要洗出相应报表即可,具备日,周,月,季度视图。在汇报时,领导并不关注细节,甚至除了运营团队自身之外,其他团队都更关注质量而非过程)。除此之外,还需要关注伴生指标以及对立指标。例如考虑覆盖率的同时,需要考虑健康度作为伴生指标。否则你可能100%覆盖率,80%健康度(另外的20%可能由于CPU,MEM反复重启,或者无法正常执行进程等等),类似的培训完成率以及钓鱼中招率。对立指标有T-P以及F-P,即要看正确触发警报的实际问题的比例,也要看没有实际问题时触发的警报的比例。除此之外你一定还听过很多框架,例如在内部探讨SOC架构设计的时候。也曾听到过一些声音,说框架很多不便选择,比如SOC已经采用了ATT&CK框架。其实这里并不冲突。SOC采用ATT&CK衡量在数据平台覆盖检测场景,ATT&CK恰恰是作为场景化目标的一个参考框架。但这里就引出了一个新的问题,就是你参考ATT&CK覆盖了20个场景,上线了70条规则,真的有效吗?怎么衡量?在计算平台上触发检测还是把规则同步到每个System上执行?与此类似的还有采购了威胁情报。我们知道威胁情报可以提供domain, ip, url, cert, ja3, email, hash等IOC,那这些IOC也可以被应用到其他不同的系统中去,比如说SIEM、ASM、WAF等。
这里需要新的一些衡量指标。比如场景被触发的数量,由威胁情报产生的告警数(命中率),这部分告警的准确率,覆盖在哪些场景上。
最后还需要一些统计学维度的指标,例如:Top10的告警来自哪些规则,分别触发的Playbook(以及执行了多少次),命中在KillChain的哪些阶段,命中了ATT&CK中的哪些场景,事件分别是什么类别,以及新增类型的事件哪些被转换成了SOP。以此来衡量SOC团队的运营质量。你需要把主要的威胁攻击防御自动化掉,以便投入更多的精力在高优先级事件中。
回到本节最开始说的几个目标,我们就可以挑选适当的指标去衡量场景化,自动化的进度了。另外不得不提一下微微一软家的产品在管理端下发一次配置,技术支持的标准回答往往是:生效时间在24h以上,取决于用户数量。但实际上有时是6h左右,有时候是则在24h以上。尤其是当你做了SOD之后,如果处理需要激活特权账户,那么在激活一次权限之后可能需要10分钟左右生效,有时甚至需要登入登出才能刷新看到对应的管理界面。
最早了解到集体智慧(Collective Intelligence)这个词是来源于《集体智慧编程》这本书。但集体智慧这个词真的是让我感觉既陌生又熟悉。虽然听到过不少次,但实际又很少在现实中见到过。总结起来似乎是一方面由于个体水平不同导致不同程度的傲慢和偏见,另一方面团体协作也带来了一定程度的混乱。我相信每个企业都有一些“生不逢时”的工程师,一边认为自己是千里马,期待同伯乐来个相见恨晚,一边又懊悔公司没人能够慧眼识珠。但实际因集体智慧获得收益时,往往又忽略了平台的作用。那些工作未逢伯乐的同事,他们长期以来,逐渐建立了一层针对工作的情绪滤网,不断的负反馈(不加薪,不升职,不给项目,被challenge)让他们愈发抵触来自对立面的输入。即便在某个方向是专业的,也丧失了推广自己方案的主动性。这对于团队来说是不利的。因为提升个体智慧不一定能增益集体智慧,反之却使整体水平下降。
从四个方面去看,产生集体智慧的关键有信息共享、集体决策、沟通、创新。主要体现为协作与决策。而你的协作和决策只能基于你的可理解程度。这里就不得不提到另一个概念——可理解输入与可理解输出。因为集体智慧需要个体参与,信息共享和沟通正是集体协作的关键。可理解输入能够帮助个体主动学习提升自己,可理解输出可以帮助个体推广自己。
以SOC运营为例,毫无疑问SOC的成立与运转需要依赖大量的协作。内部需要在tier 1、tier 2、 tier 3同事之间协作,对外需要在风控、合规、数据等部门进行配合。不难发现从事件应急,事故复盘,汇报,写文档,培训等日常工作都需要大量的沟通和配合,几乎处处涉及到集体决策。同时又涉及到个体决策与集体决策的平衡点。我们大可以使用专家经验或者领导力(强硬派)进行决断,但也可以使用集体智慧。很多时候面临来自领导的决策,是不是能够用集体智慧去弥补个体智慧的不足?(你所在的集体中有极为突出的个人智慧吗?)。我们再次回到可理解输入输出的概念上,假如当Manager提出了个一个方案需要去实施的时候,你可能有一个更优的解决方案,但你不能上来就否定他的方案,或者告诉他不能做亦或是难度很大。如果对方没有经受过职业经理人的训练,此时他获得了不可理解输入,内心一定是极为抵触的。当你再次提出新方案的时候,就难免遇到一些阻碍。如果其中还涉及到一些知识是其尚未接触过的,那对于方案的推广来说将更加困难。你可以给出一些选择,让Manager去选择怎么样去实施,在选择过程中再逐渐倾向到新的解决方案,最后提供出来。这就是在个体智慧和集体智慧里博弈的一个简单例子。我的老板和其他部门负责人拉扯完之后经常跟我说:“你看这种拉扯是不是有理有据有节?多学习学习”。我在这个过程中发现的诀窍就是可理解输入与输出。因为你不能指望其他部门的人和你拥有相同的技术背景,你也不能指望相同部门的人和你有同样的技术深度。 但这种博弈过程,你的leadership告诉你需要推广最有利/适合的方案时,那就需要向集体提供可理解输出。除此之外还可以通过一些流程和机制确保这个过程的可行性,例如可以通过安全治理委员会来规避安全团队内部的不合理决策,通过业务方周会来规避部门间的不合理决策。
注:可理解输入指的是只获取i+1(恰好比你理解的多一点)的知识,它有三个条件:有趣、足量、可理解。当趣味度大于压力水平的时候,更多的知识可以通过个人的情绪滤网(affective filter),能够被有效的吸收。这个理论是来自Dr. Stephen的英语教学,反之你对外提供可理解输入时就是你的可理解输出。
其实企业对安全运营工程师的招聘要求一直以来是比较宽松的,因为大部分情况只需要先能够快速上手重复的任务即可。作为架构师,我跟踪了几个月SOC团队的工作状况后略有收获,也针对SOC团队做了一些设计,但是实际效果一般。同样的在更早之前,我曾认为架构团队的输出有限。当时认为是因为信息差和参与度不够,但即便后来成立了安全治理委员会也未能完全解决这个问题。现在我也将其归结于集体智慧工程的失败。因为参与只能解决信息差的问题,能不能理解且另说,作为第一步,还需要通过沟通与“创新”解决剩下的问题。另外由于执行过程往往在其他团队,还需要针对执行结果进行一定的验证。由此完成团队的协作及输出。
另外大厂搞自研不必瞧不起小厂,小厂也不必觉得大厂就多厉害;买商业产品的也不要觉得比开源厉害多少,用开源的也不用羡慕有预算采购的的;互联网大可不必吹嘘所谓技术,银行也不用接受互联网行业的忽悠。没有最好的,只有最适合的。有优势必有劣势,场景化定制度很高,那就不易于通用。买了E5,也不代表着能有定制化,不少东西依旧需要单独付费。
参考内容:
* MLOps foundation roadmap for enterprises with Amazon SageMaker
* 维基百科-集体智慧
* 安全运营中心能力成熟度模型 (CMM-SOC) 构建
如有侵权请联系:admin#unsafe.sh