刚写asm项目时,爬虫服务是通过service对外提供服务。
爬虫服务容器编排yaml文件见 https://github.com/leveryd-asm/asm/blob/f6c481efbe/templates/crawler.yaml
工作流中调用服务的例子见 https://github.com/leveryd-asm/asm/blob/f6c481efbe5820fb682bc1dc4113ec168cd2275e/templates/argo-workflow-template/argo-workflow-atom-template-crawler.yaml
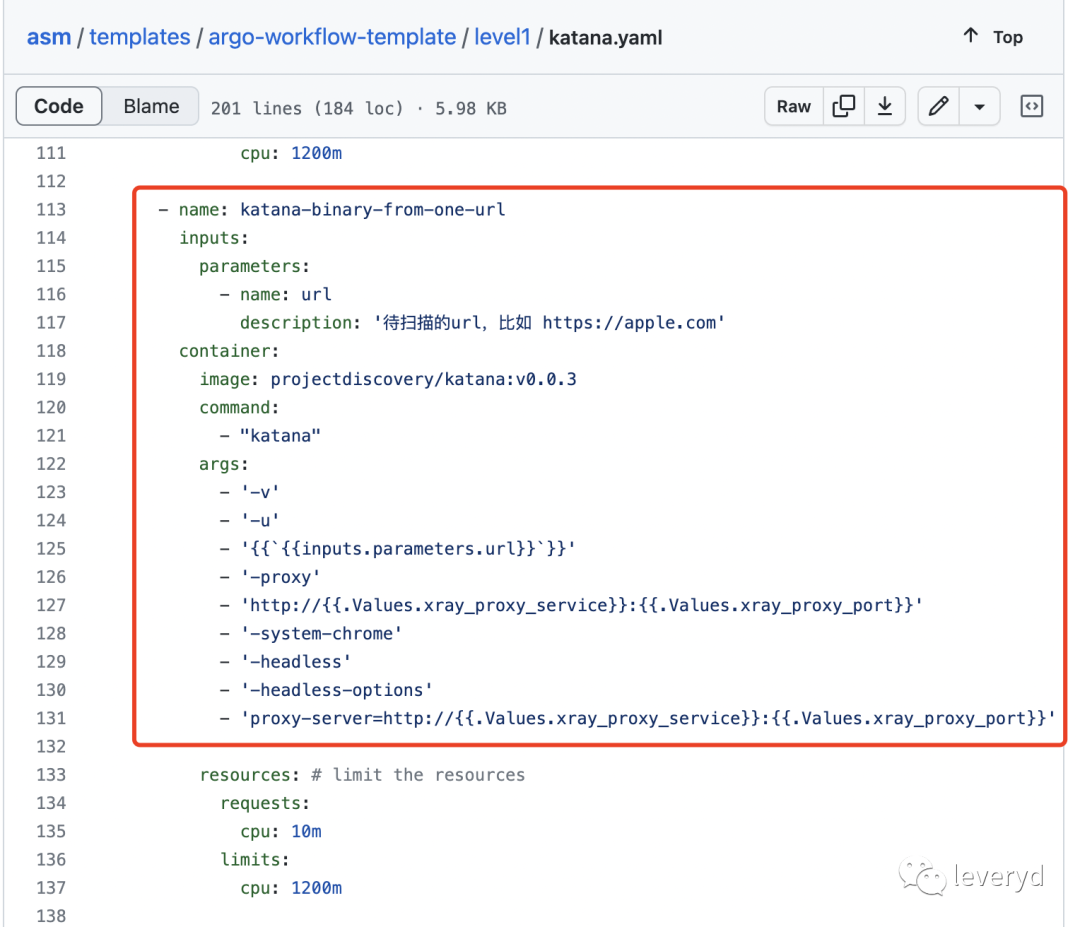
但现在工作流中直接调用爬虫二进制文件
刚好有师傅问到这个,所以简单记录一下为什么要做这个改变。
我现在也不记得确切的原因,估计当时是觉得爬虫可能会是一个很重要的模块,会对外提供很多能力,如果以api形式提供服务,以后调用起来就更方便。
爬虫服务内部组件包含一个生产者和消费者,通过kafka通信。这种架构很常见,它有一些优点,包括 通过消息队列解耦、扩展性较好,通过创建多个消费者实例提高性能。
代码见 https://github.com/leveryd-asm/crawler 。
但爬虫服务存在一些问题,比如爬虫任务没有启停功能、我对kafka了解得很少、没有任务进度信息。
基于上面的问题背景,因为argo ui提供了任务启停功能、任务进度也容易估算出来,也不需要kafka中间件、避免给自己挖坑,所以选择在argo-workflows工作流中直接调用爬虫二进制文件。
文章来源: https://mp.weixin.qq.com/s?__biz=MzkyMDIxMjE5MA==&mid=2247485304&idx=1&sn=d1432252c6162e9cd8ca7b7561825bc4&chksm=c19700c9f6e089dfa20d908b8480d666aa5ec68f4334352aea2100091ad2ca7876cd50b656a1&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh