原文标题:Not The End of Story: An Evaluation of ChatGPT-Driven Vulnerability Description Mappings
原文作者:Xin Liu, Yuan Tan, Zhenghang Xiao, Jianwei Zhuge, Rui Zhou
原文链接:https://aclanthology.org/2023.findings-acl.229/
主题类型:LLMs
笔记作者:周金飞@SEU、杨望@SEU
主编:黄诚@安全学术圈
为了更好的管理和研究漏洞,经常需要对漏洞数据进行结构化处理。漏洞描述映射(VDM)是指将漏洞映射到常见弱点枚举 (CWE)、常见攻击模式枚举和分类、ATT&CK 技术和其他分类。随着漏洞数量越来越多,仅靠人力难以对大量漏洞数据进行结构化处理,有人提出使用大语言模型(LLM)来进行漏洞描述映射(VDM)。为了测试大语言模型(LLM)在漏洞描述映射(VDM)的表现,论文设计了一个评估框架,并针对两种任务类型(Vulnerability-to-CWE和Vulnerability-to-ATT&CK)构建了基于CVE的三个数据集,以评估ChatGPT在漏洞描述映射(VDM)任务上的性能。
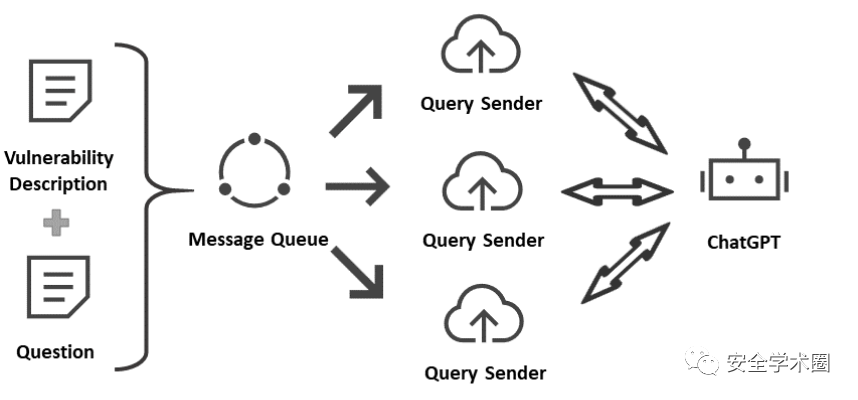
测试框架
如图是与ChatGPT的交互流程,给ChatGPT一定的提示,然后从ChatGPT的回答中正则提取所需要的信息。ChatGPT会根据不同提示产生不同回答,论文分别用弱prompt和强prompt测试ChatGPT的性能表现。
弱prompt:提问方式如“此漏洞描述与哪个CWE-ID匹配?”并附上漏洞描述。
强prompt:首先要求ChatGPT据漏洞描述提供五个可能的类别(前5个)及其定义。然后要求ChatGPT从它们中找到最合适的一个(1个)。
测试数据集
CVE-CWE:该数据集涵盖了2021年所有CVE数据(CVE-2021-*),包含13,513 个漏洞。数据集包括三个字段:CVE-ID、漏洞描述和CWE-ID。
CVE-ATT&CK:该数据集是CVE-ATT&CK Technique数据集涵盖2021年的7,013 个CVE漏洞 (CVE-2021*),包含三个字段:CVE-ID、漏洞描述和ATT&CK Technique ID。
CVE-ATT&CK-builtOnBRON:该数据集是基于BRON构建的CVE-ATT&CK 技术数据集由三个字段组成:CVE-ID、漏洞描述和ATT&CK Technique ID列表。
测试结果
CVE-ID映射效果
上表是ChatGPT在弱prompt和强prompt情况下对CVE-ID识别的情况,可以看到超过一半的漏洞CWE-ID可以通过ChatGPT准确确定。
ATT&CK Technique ID映射效果
上表是ChatGPT在数据集CVE-ATT&CK和CVE-ATT&CK-builtOnBRON下对ATT&CK技术ID映射的结果,可以看到ChatGPT对两个数据集的表现区别不大。同时也可以看到,ChatGPT在CVE-ATT&CK 任务上的表现并不理想,勉强满足现实需求。
通过比较其他提取ATT&CK Technique ID可以发现专业的提取方法都明显优于ChatGPT,尤其是Ampel等人提出的CVET方法性能显著超过ChatGPT。
本文分析了ChatGPT在强prompt和弱prompt下处理Vulnerability-to-CWE和Vulnerability-to-ATT&CK任务的性能表现,制作了三个数据集来做测试。证明了ChatGPT在映射CWE编号上的良好表现和映射ATT&CK Technique ID的欠佳表现。
论文针对LLM在VDM上的能力设计了两个测试框架,以ChatGPT为例对不同数据集进行了测试,观察其性能表现,给研究LLMs在VDM上应用的人员一定参考,但是只测试了ChatGPT,未针对其他开源LLMs进行测试。
Xin Liu, 兰州大学, https://aclanthology.org/people/x/xin-liu/
Yuan Tan, 兰州大学
Zhenghang Xiao, 湖南大学
Jianwei Zhuge, 清华大学,中关村实验室
Rui Zhou, 兰州大学
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh