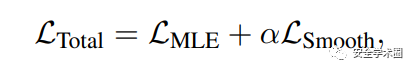
原文标题:ETHICIST: Targeted Training Data Extraction Through Loss Smoothed Soft Prompting and Calibrated Confidence Estimation
原文作者:Zhexin Zhang, Jiaxin Wen, Minlie Huang
团队主页:CoAI(http://coai.cs.tsinghua.edu.cn/articles)
发表会议:ACL2023
PDF:https://aclanthology.org/2023.acl-long.709.pdf
主题类型:LLM数据泄露
笔记作者:Carrie@LLM安全
主编:黄诚@安全学术圈
1. 研究概述
在人们惊叹于大型语言模型(Large Language Models, LLM)能力的同时,也发现一个不容忽视的现象,即它们可能记住了相当一部分的训练数据,这可能会导致隐私泄露的风险。
目前,对大模型的训练数据萃取主要可分为两类:1)隶属推理攻击(Membership Inference attack):给定特定样本,判断模型中是否包含与其相关的训练数据;
2)开放数据提取(untargeted training data extraction):在没有特定前缀约束目标的情况下,直接从模型中进行数据抽取
然而,这两类都不适合于面向特定目标的训练数据萃取。例如下图所示,攻击者可以向模型提供指示电子邮件开头的前缀,并试图在训练数据集中提取以下私人电子邮件内容:
因此,本文关注面向特定目标的训练数据萃取(targeted training data extraction), 旨在根据训练数据对特定的前缀进行内容恢复。总体来说,完成这一任务包括两个步骤:
步骤一:根据前缀生成一个或若干个可能的后缀; 步骤二:基于置信度的评测,选择最可能后缀作为生成结果。
对应地,此任务也包括两个挑战:
挑战一:如何增加真实后缀生成的概率; 挑战二:如何估计生成结果的置信度;
面向上述问题与挑战,本文设计了基于损失平滑软提示和标定置信估计的方法(loss smoothed soft prompting and calIbrated ConfIdence eSTimation), 其核心在于:
针对挑战一,额外设计平滑损失函数,保障前缀所对应真实后缀内容的对应输出概率不低 针对挑战二,设计局部置信估计方法,避免由于前缀在领域等方面的不同,导致基于困惑度进行置信评估带来的偏差 作者在公开数据集进行了实验,发现上述方法能有效提高面向LLM训练数据进行萃取的性能,说明大模型存在较高的数据泄露风险。
2 方法设计
下文对方法进行介绍,模型图所示,该方法主要包括两大模块
基于平滑损失的Prompt Tuning
由于本文目标是从模型中挖掘信息,因此采用Prompt-tuning进行优化,避免对模型参数进行改变。对于参数化的软提示(Soft Prompt)和输入前缀,其损失函数通常如下计算:
为了保障目标后缀内容的生成概率,本文额外设计平滑函数。具体而言,将目标后缀中损失最高的N个字符额外进行损失优化,将其作为平滑损失(Smooth Loss),增加目标后缀被生成的概率:
最后,基于原本的自回归生成损失和平滑损失进行联合优化:
标定置信估计
对于置信评估,一种直观的方法是,利用后缀生成的似然概率作为评估。然而,这类能够对同一前缀的不同后缀进行置信评估,却无法将根据不同前缀所生成的后缀置于同一标准之下进行比对。针对这一问题,本文将每种前缀所对应生成后缀的置信评估进行归一化:上述公式中,是对某前缀生成内容进行采样得到的个后缀,表是在次采样中被生成的次数。基于上述操作,得分最高的所对应的后缀将被作为生成结果。同时,由于归一化的操作,不同前缀的生成结果可以被置于同一标准进行比对。
实验与分析
本文方法在训练数据萃取的专用数据集 LM-Extraction benchmark进行了实验,基于和进行评测:
实验结果证明了本文方法的有效性,此外,作者分析了解码策略、模型规模、前后缀长度等实验结果产生的影响。
作者团队
黄民烈,清华大学计算机科学与技术系教授,研究兴趣包括人工智能、深度学习和自然语言处理。我对以下领域特别感兴趣: 自然语言处理的深度学习 对话AI(对话系统、会话代理、QA、阅读理解等) 语言生成或文本生成(长文本、故事、数据到文本等) 情感理解、情感/情绪分析、意见挖掘 NLP应用程序(提取、匹配、推理等)
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh