神奇的X指标
一位分析师发表文章“出现X特征的公司将迎来持续增长”。文中详细描述了其发现的独特规律——X指标,并列举了五家热点企业的案例分析,五张图表如出一辙地显示出X指标的优越性。
股民小A看后,回想到之前关注的几支股票走势,深感认同,开始购买出现X指标的股票。
几次交易后,损失惨重。
小A反思,觉得之前的判断过于轻率,有必要更精确的测量一下X指标的效果。于是基于X指标实现了一个交易策略,不断调优参数后,历史五年数据回测显示出一条稳定的高增长曲线。
实盘运行之后,发现业绩平平、起伏不定,一段时间后,小A停止了策略。
---
“出现X特征的公司将迎来持续增长” 这句话可以称之为一个观点、判断、方法、命题...等其他名字,本文中统一用「知识」一词指代。
小A对于一种新「知识」的两次反应,引申出两个问题:
如何评判一个知识的有效性?
有效性降低时,如何进行加工修正?
知识的演进
知识的产生
人们理解事物时,首先产生感性认识,后形成理性认识(知识),理性认识指导实践,实践对客观世界产生改变,然后再认识、再实践,循环往复,永无止境。
想象一个双螺旋:知识不断进化,同时实践对世界造成影响,导致客观世界也在不断变化,其变化又引发新知识的产生。
知识有效性的衰减
出版物(专业书籍、论文等)是知识发展过程中一些具有代表性的“检查点”,这一历史数据可供我们测算知识的变化速度。
人类知识的增长被认为呈现指数形态,尤其是在科学和技术领域,科学文献的数量每9年翻倍 [1]。知识的增长向摩尔定律靠近,同时 对客观世界产生的改变(社会的进步)也是指数性的 [2] 。
[1] Bornmann, Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references, 2015.
[2] Ian Morris, The measure of civilization, 2013.
基于对历史各领域出版物勘误及引用量的统计,我们甚至可以估计出不同领域知识的“半衰期”。
粗略而言,针对基础学科,新研究发现将在10年左右时间丧失热度 [1],45年后一半研究将被推翻 [2]。
[1] Tang Rong, Citation Characteristics and Intellectual Acceptance of Scholarly Monographs, 2008
[2] Thierry Poynard, Truth Survival in Clinical Research: An Evidence-Based Requiem, 2002
我们可以直观地将知识分为长周期知识(物理、数学)和短周期知识(前文“神奇的X指标”、朋友的某个生活经验)。
以短周期知识指导实践是危险的,除非我们知道如何迭代它。
跨越认知偏差
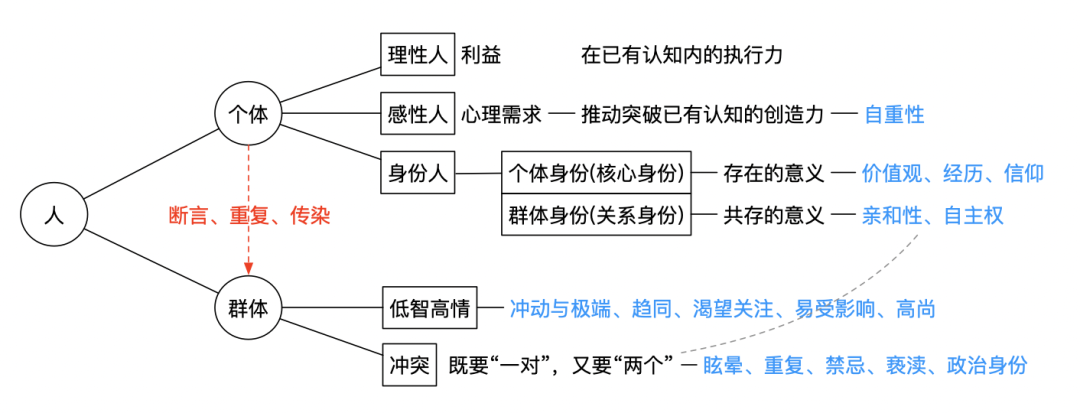
心理学中的认知偏差指的是人们在思考、评估和记忆信息时的非理性和非客观错误。
这些偏差是由我们的大脑在处理大量信息时采取的认知简化策略导致的。虽然这种大脑的“节能模式”、“本能反应”在人进化的过程中诞生,用于帮助我们快速处理信息,但它们也可能导致错误的知识和不准确的判断。例如:
确认偏差(Confirmation Bias):人们倾向于寻找和重视支持自己观点的证据,而忽视或贬低与自己观点相悖的证据。这种偏差可能导致我们坚持错误的观点,即使有反驳证据存在。
自我服务偏差(Self-serving Bias):人们倾向于将自己的成功归因于自身能力和努力,而将失败归因于外部因素。这种偏差可能导致我们对自己的能力和知识过于自信,无法看到自己的不足和错误。
集体思维(Groupthink):在集体中,个体为了维护团队的和谐和一致性,而倾向于抑制异议和批评,从而导致决策质量下降。这种现象可能导致团队成员接受错误的观点和信息,而无法发现和纠正这些错误。
除了感性因素以外,个体的身份标签往往更隐晦的影响我们思考。
和外界交流、学习的过程是收集信息的过程,而形成最终决策的推演,一定要找个安静的空间独立完成。这种冷清的“孤独感”就是思考的一部分。
认识偏差是可以通过长期训练来识别、跨越的。看政治人物的演讲、辩论比赛有助于训练识别观点植入,可同时关注其方法、逻辑漏洞和自身的情绪反应。
加工知识的理性工具
演绎
演绎推理是从一个或多个已知的前提出发,通过逻辑推理得出一个结论。
前提1:所有人都会死亡。
前提2:苏格拉底是人。
结论:苏格拉底会死亡。
演绎推理的结论通常被认为是必然的,即如果前提正确、推理过程正确,则结论一定是正确的,其有效性评估主要为:
前提是否正确:如果前提错误,那么结论有可能是错误的。
推理形式是否正确:如果推理形式存在错误,那么结论是无效的。
归纳
归纳推理是通过观察一系列特定的实例,总结出一个更普遍的规律或原则。
观察1:这个湖里的天鹅都是白色的。
观察2:那个湖里的天鹅也都是白色的。
观察3:另一个湖里的天鹅同样都是白色的。
结论:所有的天鹅都是白色的。
归纳推理的结论通常是概率性的,即基于观察到的实例,我们可以得出一个相对可能正确的结论,其有效性评估主要考虑:
样本的代表性:样本应该足够大且具有代表性,以便我们从中推导出普遍规律。
观察的一致性:观察到的实例应该具有相似的特征,以便我们得出一个可靠的结论。
统计
《三体》讲述了这样一个故事:
一个农场里有一群火鸡,农场主每天中午11点来给他们送食。火鸡中有一位科学家观察这个现象,以致观察了近乎一年都没有例外,于是他也发现了一个自己宇宙中的伟大定理“每天早上11点食物降临”。他在感恩节的早晨向火鸡们公布了这个定理,但11点食物没有降临,农场主进来把火鸡全杀了。
这个故事源自罗素的“火鸡问题”,无论是演绎的前提还是归纳的结论,我们都无法找到某个命题“绝对正确”。
“正确”的含义即“这件事情出现的可能性很高”。
统计方法的实际应用往往是演绎与归纳的融合:我们需要基于先验知识设计实验,同时也要求一定的样本表现支撑其结论。
例如辉瑞-BioNTech COVID-19疫苗有效性验证的论文中,使用Cox比例风险回归模型量化疫苗的有效性,并在4.4万名志愿者中进行了临床试验。
如果我们不认可实验方案(算法、实验过程、样本的代表性及真实性)那么结论就是存疑的。
如果实验结果发现实验组和对照组没有明显差别,那么结论也是存疑的。
回到X指标问题
开头的故事中,小A犯的错误除了心理因素外还有:
1. 不了解产生这种知识产生的原理
它是由什么交易演绎而来的,这一理念的假设是什么、得出结论的推理过程正确吗 -> 适用于哪些情况,不适用于哪些情况?
作者给出的验证方式(5个公司的业绩表现)有说服力吗?
2. 验证知识的方法不合理
用一个固定的指标 y=kx 去测试历史数据存在「过拟合」问题,k这个参数是现在确定的,用现在确定的指标测试历史数据无疑是“考试作弊”。
我们需要把训练数据和测试数据分离。
考虑一个N年周期的滑动窗口,用每N年的历史数据训练K的值,然后用y=kx去预测N+1年的效果,基于此计算每年的表现。
除此之外,还有一层隐藏的过拟合问题,也就是说,y=kx这个系统/算法的设计出自于当下的人,人在设计这个算式的过程中仍然包括了历史数据(经验)。
人不能通过时光机回到历史,但对此也必须谨慎。
更多的想法?
除此之外,我们也许会假设:今天的情况将会和昨天强相关,而和一年前的某一天弱相关,那么我们需要对历史数据进行时间维度加权处理?以及,我们是否需要评估,这一X指标适用于哪些类型目标、不适用于哪些类型目标?相对Y指标而言,X指标更好吗?如果我把X指标和其他指标一起使用,如何组合并分配权重?——都需要数据检验。
数据够吗?我们能承担这种验证的成本吗?
绝大部分情况下,我们不会对短周期知识进行验证,它们迭代的太快了。
但是我们可以做一些改变:
1. 了解知识的动态性,保持谦虚谨慎的态度。
2. 基于长周期知识,多使用演绎方法,降低验证成本。
决策流程的改进
将静态知识抽象为动态系统。
我们要把一个知识的“检查点” y=0.6 上升为一个可迭代的系统 y=f(x) 其中系统的输入参数来源于现实世界的数据,让输出的知识能够跟随客观情况变化。
以系统思维对问题进行解构。
以长周期知识为前提,通过演绎的方式,提出解决问题的理论依据。过程中需排除心理因素影响。
对系统进行建构。
用历史数据测试系统的表现,发现问题,重复第二步。
记录实践数据,评估记录系统的真实表现,发现问题,重复第二步。
*关于「系统思维」的详细描述,参考之前的文章(下节链接)。
结语
认识到知识的变化性,辨识其前提假设,在能力允许的情况下理性检验,然后谦虚谨慎地实践,持续地迭代。
---
本文是对22年4月《解决复杂问题的一般性方法》的一次迭代,刚好满一年。
当时希望总结出处理日常工作问题的一般性流程,引入「系统思维」这个概念去解构问题、建构方案——即PDCA中“Plan与Action”的部分。
后来又逐渐意识到情绪、心态问题是个大坑,于是给自己做了一份PDCA量表,在Plan阶段用一个checklist来主观检验心理状态——本文中的第三部分:跨越认知偏差。这个过程非常之痛苦。
再后来是PDCA中Check的部分,理论验证和实际偏差很大,不稳定,于是有了本文的第四部分,其间深刻感受到知识的变化速度远比我想象中的快。
偶然和朋友聊到 交易系统和交易日志,感觉有异曲同工之妙,于是加上了开头的小故事。
延展阅读
知识与世界的变化速度
《The Half-Life of Facts: Why Everything We Know Has an Expiration Date》, Samuel Arbesman
这本书提出了「知识半衰期」概念,汇集多个领域的研究成果,展示了知识更新的速度,指出知识的增长速度符合摩尔定律。
《The Art of Doing Science and Engineering: Learning to Learn》, Richard W. Hamming
汉明码的作者,回顾了一生科研经验,提出“掌握基础知识和基本原理是实现长期成功的关键”,鼓励读者投资于那些跨越时代的核心概念,而非仅关注短期热门领域。
《科学革命的结构/The Structure of Scientific Revolutions》, Thomas Kuhn
提出了科学发展是通过「范式转换」和科学革命实现的观点,挑战了科学发展是线性、累积的传统观念。我们可以看到即使是学生时代被认作「真理」的基础科学结论是如何被迭代的。
《The Measure of Civilization》, Ian Morris
提出了一个综合性指标——社会发展指数,用于评估文明的发展水平。包含能源利用、城市化、信息处理和战争能力四个主要维度,让我们看到世界发展的进程也是非线性的,该指标在现代更是以爆炸式速度发展。
认知偏差、假设演绎、统计
《思考,快与慢/Thinking, Fast and Slow》, Daniel Kahneman
提出「快思考」、「慢思考」的概念。快思考是指我们的直觉反应和自动化思维,而慢思考是指我们的分析和逻辑思考。快思考易于受到认知偏差的影响,导致我们在判断和决策过程中出现错误。
《社会心理学/Social Psychology》, David G.Myers, 人民邮电出版社
教材。介绍了人类在社会互动中的心理过程,包括情感、态度、群体行为、人际关系等方面。也讨论了一些与认知偏差相关的概念。
《逻辑学导论/Introduction to Logic》, Irving M.Copi, 中国人民大学出版社
教材。介绍了包含假设、演绎等逻辑学基本概念及有效性评价标准,同时给出了诸多名人演讲/文章中的逻辑谬误供思维训练。
《女士品茶:统计学如何变革了科学和生活/The Lady Tasting Tea: How Statistics Revolutionized Science in the Twentieth Century》, David Salsburg
回顾20世纪统计学的发展历程,介绍一些经典的统计学方法,展现了统计学的实际应用和统计假设检验的重要性,同时告诉你“世界上没什么是绝对准确的”。
系统思维
如有侵权请联系:admin#unsafe.sh