I recently wrote a post about the concept of the Data Lakehouse, which in some ways, b 2021-2-9 00:25:58 Author: raffy.ch(查看原文) 阅读量:20 收藏
I recently wrote a post about the concept of the Data Lakehouse, which in some ways, brings components of what I outlined in the first post around my desires for a new database system to life. In this post, I am going to make an attempt to describe a roll-up of some recent big data developments that you should be aware of.
Let’s start with the lowest layer in the database or big data stack, which in many cases is Apache Spark as the processing engine powering a lot of the big data components. The component itself is obviously not new, but there is an interesting feature that was added in Spark 3.0, which is the Adaptive Query Execution (AQE). This features allows Spark to optimize and adjust query plans based on runtime statistics collected while the query is running. Make sure to turn it on for SparkSQL (spark.sql.adaptive.enabled) as it’s off by default.
The next component of interest is Apache Kudu. You are probably familiar with parquet. Unfortunately, parquet has some significant drawbacks, like it’s innate batch approach (you have to commit written data before it’s available for read). Specifically when it comes to real-time applications. Kudu’s on-disk data format closely resembles parquet, with a few differences to support efficient random access as well as updates. Also notable is that Kudu can’t use cloud object storage due to it’s use of Ext4 or XFS and the reliance on a consensus algorithm which isn’t supported in cloud object storage (RAFT).
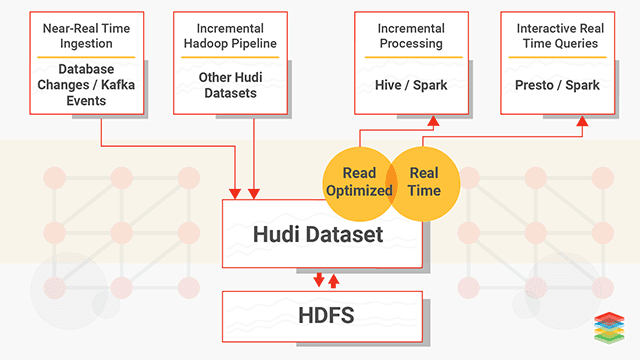
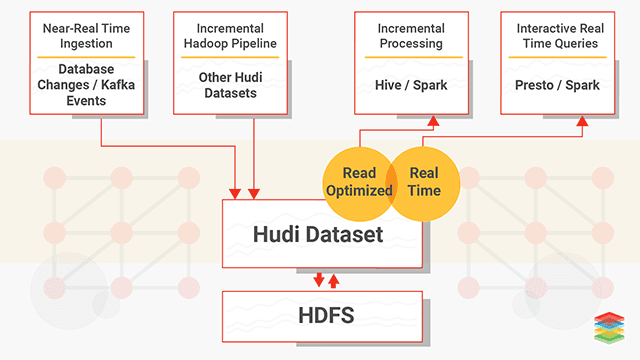
At the same layer in the stack as Kudu and parquet, we have to mention Apache Hudi. Apache Hudi, like Kudu, brings stream processing to big data by providing fresh data. Like Kudu it allows for updates and deletes. Unlike Kudu though, Hudi doesn’t provide a storage layer and therefore you generally want to use parquet as its storage format. That’s probably one of the main differences, Kudu tries to be a storage layer for OLTP whereas Hudi is strictly OLAP. Another powerful feature of Hudi is that it makes a ‘change stream’ available, which allows for incremental pulling. With that it supports three types of queries:
- Snapshot Queries : Queries see the latest snapshot of the table as of a given commit or compaction action. Here the concepts of ‘copy on write’ and ‘merge on read’ become important. The latter being useful for near real-time querying.
- Incremental Queries : Queries only see new data written to the table, since a given commit/compaction.
- Read Optimized Queries : Queries see the latest snapshot of table as of a given commit/compaction action. This is mostly used for high speed querying.
The Hudi documentation is a great spot to get more details. And here is a diagram I borrowed from XenoStack:
What then is Apache Iceberg and the Delta Lake then? These two projects yet another way of organizing your data. They can be backed by parquet, and each differ slightly in the exact use-cases and how they handle data changes. And just like Hudi, they both can be used with Spark and Presto or Hive. For a more detailed discussion on the differences, have a look here and this blog walks you through an example of using Hudi and Delta Lake.
Enough about tables and storage formats. While they are important when you have to deal with large amounts of data, I am much more interested in the query layer.
The project to look at here is Apache Calcite which is a ‘data management framework’ or I’d call it a SQL engine. It’s not a full database mainly due to omitting the storage layer. But it supports multiple storage engines. Another cool feature is the support for streaming and graph SQL. Generally you don’t have to bother with the project as it’s built into a number of the existing engines like Hive, Drill, Solr, etc.
As a quick summary and a slightly different way of looking at why all these projects mentioned so far have come into existence, it might make sense to roll up the data pipeline challenge from a different perspective. Remember the days when we deployed Lambda architectures? You had two separate data paths; one for real-time and one for batch ingest. Apache Flink can help unify these two paths. Others, instead of rewriting their pipelines, let developers write the batch layer and then used Calcite to automatically translate that into the real-time processing code and to merge the real-time and batch outputs, used Apache Pinot.
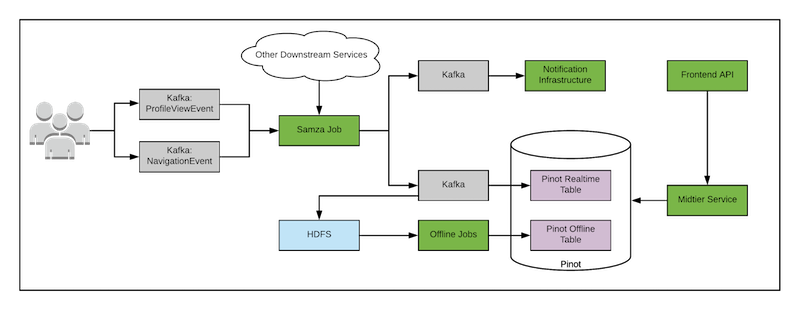
The nice thing is that there is a Presto to Pinot connector, allowing you to stay in your favorite query engine. Sidenote: don’t worry about Apache Samza too much here. It’s another distributed processing engine like Flink or Spark.
Enough of the geekery. I am sure your head hurts just as much as mine, trying to keep track of all of these crazy projects and how they hang together. Maybe another interesting lens would be to check out what AWS has to offer around databases. To start with, there is PartiQL. In short, it’s a SQL-compatible query language that enables querying data regardless of where or in what format it is stored; structured, unstructured, columnar, row-based, you name it. You can use PartiQL within DynamoDB or the project’s REPL. Glue Elastic views also support PartiQL at this point.
Well, I get it, a general purpose data store that just does the right thing, meaning it’s fast, it has the correct data integrity properties, etc, is a hard problem. Hence the sprawl of all of these data stores (search, graph, columnar, row) and processing and storage projects (from hudi to parquet and impala back to presto and csv files). But eventually, what I really want is a database that just does all these things for me. I don’t want to learn about all these projects and nuances. Just give me a system that lets me dump data into it and answers my SQL queries (real-time and batch) quickly.
Until next time …
如有侵权请联系:admin#unsafe.sh