工作来源
ASIA CCS 2022
工作背景
恶意软件变种间在代码重用方面的复杂关系为恶意软件分析带来了挑战,包括标签、分类、家族与作者归因。反病毒引擎给出的标签通常不一致且粒度较粗,无法捕获 IoT 恶意软件间的代码重用。与此同时,旧的恶意软件通常会在新恶意软件出现时退场。机器学习模型对这种变化称为概念漂移,使用旧数据训练的模型在处理前所未见的新样本时挑战极大。为了构建有效且稳健的分类器,必须能够检测同一恶意软件家族中漂移的 IoT 变种,并解释漂移的成因。
检查 Mirai 家族样本在一年内的类内进化,如下所示。由于概念漂移,分类效果越来越差,一年后已经不足 50%。传统意义上解决概念漂移的方式,可能并不适用于安全领域。
样本数量与 IoT 文件普遍缺乏复杂的混淆,使得基于代码的分析成为可能。识别不断发展的恶意软件的变种几乎可以等同于二进制文件相似,只是在 IoT 领域内有一些挑战:
针对不同体系结构的二进制文件,即使源代码相同,编译出来指令也不相同。
函数级代码相似被证实无法解决代码相似判断问题
分析工具对函数的识别不可靠,但指令与基本块的识别仍然有效
工作准备
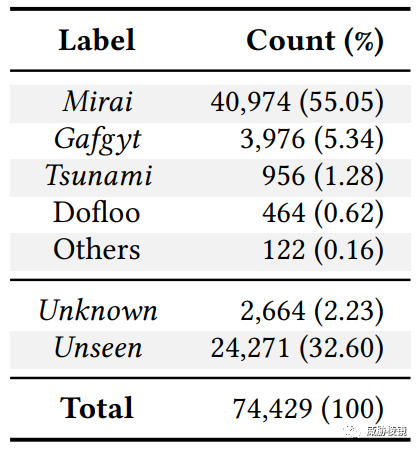
收集了从 2018 年到 2021 年超过 90000 个 IoT 恶意样本,过滤掉不可执行文件以及损坏的文件还剩下 74429 个。通过 VirusTotal 的分析报告,使用 AVClass 对其进行处理聚合家族归属。如下所示:
34% 的样本未能通过 AVClass 给出归属,其中 2664 个样本没有引擎给出与已知家族有关的标签、24271 个样本就没有对应的分析报告。
工作设计
整体方式如下所示:
特征提取与预处理
利用 IDA Pro 进行处理:将指令当作单词,将基本块当作句子。既不完全去掉立即数,也不完全保留立即数。而是:
区分跳转/调用目标、字符串之与内存引用
考虑 32 位寄存器的不同大小
保持堆栈指针或基址指针完整,并通过保留指针表达式维护内存访问信息
指令嵌入
采用 BERT 原始掩码语言模型(MLM)对规范化后的汇编指令进行编码,并且不使用 BERT 的下一句预测(NSP)任务。
对比学习
从传入的未标记恶意软件数据,转换成特征向量并学习如何比较向量以识别相同家族的样本。旧样本序列的特征将在新样本中得到保留,通过训练对比编码器将其投射到潜在空间的附近位置。这样即使没有明确的标签,也可以确保接近相似。
语义代码搜索引擎
评估跨体系结构代码嵌入的质量,可以用于查找变种:
工作评估
使用 Silhouette 指数衡量一个对象与自身簇和其他簇相比的相似程度,计算方式为:
比较了六千个随机选择的样本,对已识别的聚类总体来说十分优秀。
与开源的 CADE 进行比较,结果如下:
CADE 尽管在大多数情况下表现良好,但对 IoT 恶意软件时表现不佳。这也是 CADE 自身的局限,因为其主要关注 A 类概念漂移。
一共确定了 44 个 Mirai 的变种与 11 个 Gafgyt 的变种。抽取 10000 个 Mirai 样本与 3000 个 Gafgyt 样本构建连接图,如下所示:
较旧的 Mirai 变种具有更高的相似性,出现在密集与中心的区域。较新的 Mirai 变种相对分离且出现在更远的边缘区域。相比 Gafgyt 来说,Mirai 的连接更为紧密。在三个最密集的 Mirai 簇里,一共包含 7124 个样本文件。研究人员详细介绍了多个簇的情况,以显示能够以细粒度特征识别样本间的相似与区别。但此处不加以一一说明,感兴趣查看原文吧。
抽取 6 个变种(Omni、Apep、Yowai、Satori、Dark 与 Josho)的 587 个 Mirai 样本,构建语义搜索引擎的数据集。基于前文提到的代码嵌入,还使用 FAISS 与近似最近邻。基于 4 种基线(Word2vec、Doc2vec、Code2vec 与 Bi-LSTM)比较变种情况,如下所示:
此外,还使用 16 个手动选择的特征将基于基本块的机器学习分类(SVM)进行比较:
使用的具体特征为:
跨架构的样本也被正确分到了一起:
经过预处理后,Vocabulary 所受影响也更小。
工作思考
Mirai 作为一个大类,实际上早就已经泛化地超出了大家在传统意义表述上的“家族”的概念。研究人员实际上是通过更细的分类方法,来把共用源代码的 Mirai 进行细分,尽可能地划分成研究人员披露分析报告时的更细的分类。该工作尽管样本集不能开源,但工作代码本身已经开源,感兴趣的读者可以自行查阅。
EVOLIoT
https://github.com/IoTMalw/EVOLIoT
如有侵权请联系:admin#unsafe.sh