
2017-8-17 03:31:0 Author: reusablesec.blogspot.com(查看原文) 阅读量:1 收藏
"Software constraints are only confining if you use them for what they're intended to be used for"
-- David Byrne (Of the Talking Heads)
I recently had an ongoing conversation that spanned several days about the subject of solving mazes. A friend casually mentioned the "Same Wall Rule", (also known as the "Right Hand Rule"), for solving a maze. This is where if you want to find the exit of a maze you should pick a wall and follow it, with the assumption that you will eventually find the exit this way.
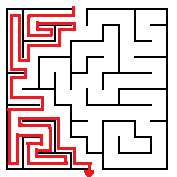 |
| Same Wall Rule for Solving a Maze |
I pointed out that while this rule generally works, you can't count on it as it can fail spectacularly. For example, what if you start out next to a free-standing wall?
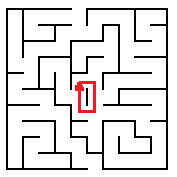 |
| Same Wall Rule Failing Horribly |
After that our conversation turned to other things but the next day my friend came back and said "I found the problem! The Same Wall Rule will work, but you have to start at the beginning of the maze! Then you can be guaranteed that you won't hit a free-standing wall".
Which is true in most cases, but what if what you are looking for an exit in a free-standing section of the maze? For example what if the treasure is in the middle or you are dealing with a 3-dimensional maze?
 |
| Same Wall Rule Failing to Find Treasure |
This reminded me of a paper that Cormac Herley recently wrote titled: Justifying Security Measures. I highly recommend reading it. It points out that in the security community we often say:
Security(X) > Security(~X)
When we really mean:
Outcome(X|ABCD) > Outcome(~X|ABCD).
Which is a fancy way of showing that when we say doing X is more secure than not doing X, there usually is a large number of assumptions, (ABCD....), that we're leaving out. Where this directly relates to the main topic of this blog, (password security), is that Herley specifically calls out the password field for the practice of ignoring constraints in our security advice. Or, to quote his paper:
"Passwords offers a target-rich environment for those seeking tautologies and
unfalsifiable claims."
Now back to the issue of maze solving, the same problem often arises. When we make a maze solving algorithm, we're making certain assumptions about the rules of the game. For example, the next iteration of a mapping algorithm might involve marking rooms that you have been in before to detect loops. Well there is a certain fairy-tale where that approach failed due to the marks being destroyed by a 3rd party actor:
 |
| Hansel and Gretel showing that marks aren't always permanent |
Even assuming you can safeguard your marks in the maze, that approach may still not be effective if the maze moves while you are traversing it.
 |
| I've never seen such an amazing premise turned into such a boring book |
Note, these assumptions go both ways. For example if you are designing a super hard maze, a snarky player can often do something completely unexpected.
 |
| Seriously, why would you want to go through the maze? |
I'd argue that coming up with a perfect maze solver that works for all mazes with no constraints is a near impossible problem. If you can design an algorithm, chances are someone else can come up with a situation where it will fail. On the plus side, the same goes for maze designers. If you come up with a maze with constraints, someone probably can solve it even if it's not how you expected the maze to be solved.
This is a point that I'm actually optimistic about. We deal with imperfect knowledge of the rules we're operating under every day. That's part of the human condition! Tying this back in with Herley's paper, I think there's some things to keep in mind.
- When giving advice to end users, I think it's fair to leave implied constraints out as long as the person giving the advice keeps them in mind. Aka telling your kids to follow the right hand wall to get through a corn maze is perfectly reasonable. Telling your kids this assumes there are no minotaurs or evil clowns waiting in the maze to eat them probably will not result in the end state you are aiming for.
- Unfortunately following the above can lead to those constraints being forgotten over time and that advice being applied to situations where it is no longer helpful.
- Therefore you need to be willing to question previously held beliefs and come up with new approaches when reality doesn't match your expected experiences.
The question then is, how do you discover/rediscover unknown constraints when your start experiencing issues?
One way to deal with this is through experimental design along with making hypothesis about what the results of those experiments will be before you run them. That's something I'm trying to get better at doing as seen in my previous blog post.
As an example: Hurley raises the question "Are lower-case pass-phrases better or worse than passwords with a mix of characters". If I construct an experiment I have to specify a set of constraints that experiment will run under. Now do those constraints match up with the real world use-cases. Of course not! But the fact that there are constraints can help myself and other people interpret how to use those results. Likewise before running an experiment it's important to have a theory and make a hypothesis about what the results will be. Once that's done, running the experiment can validate or falsify the hypothesis. I can then update theory as needed and the process continues.
To put it another way, I think there is a lot of areas where the academic side of computer security can help improve the practical impact that computer security choices impose on the end user ;p
如有侵权请联系:admin#unsafe.sh