2016-7-8 08:52:0 Author: reusablesec.blogspot.com(查看原文) 阅读量:5 收藏
Alt Title: An Embarrassment of Riches
Backstory:
Sometime around 2008, a hacker or disgruntled employee managed to break into MySpace and steal all the usernames, e-mails, and passwords from the social networking site. This included information covering more than 360 million accounts. Who knows what else they stole or did, but for the purposes of this post I'll be focusing only on the account info. For excellent coverage of why the dataset appears to be from 2008 let me refer you to the always superb Troy Hunt's blog post on the subject. Side note, most of my information about this leak also comes from Troy's coverage.
This dataset has been floating around the underground crime markets since then, but didn't gain widespread notoriety until May 2016 when an advertisement offering it for sale was posted to the "Real Deal" dark market website. Then on July 1st, 2016, another researcher managed to obtain a copy and then posted a public torrent of then entire leak for anyone to download. That's where things stand at this moment.
Unpacking the Dataset:
The first thing that stands out about the dataset is how big it is. When uncompressed the full dump is 33 Gigs. Now, I've dealt with database dumps of similar size but they always included e-mails, forum posts, website code, etc. The biggest password dataset I previously had the chance to handle was RockYou set which weighed in at 33 million passwords and took up 275 MB of disk. Admittedly that didn't include user info and passwords were stored as plaintext, (the plaintexts are generally shorter than hex representation of hashes), but still that's a huge leap in data to process. Heck, even the full RockYou list is a bit of a pain to processes.
Let me put this another way. Here is a simple question, "How many accounts are in the MySpace list?" Normally that's quick and easy. Just run:
wc -l
And then you wait ... and wait ... and wait ... and then Google if there is a faster way to count lines .. and then wait. 16 minutes and 24 seconds later, I fount out there were 360,213,049 lines in the file. Does that equal the number of total accounts or is there junk in that file? Well, I don't want to spend the 30+ minutes to run a more complicated parser so that sounds about right to me ¯\_(ツ)_/¯. Long story short, doing anything with this file takes time. Eventually I plan on moving over to a computer with a SSD and more hardware which should help but it's something to keep in mind.
That being said, the next question is "What does the data look like?" Well here is a screenshot of the first couple of lines.
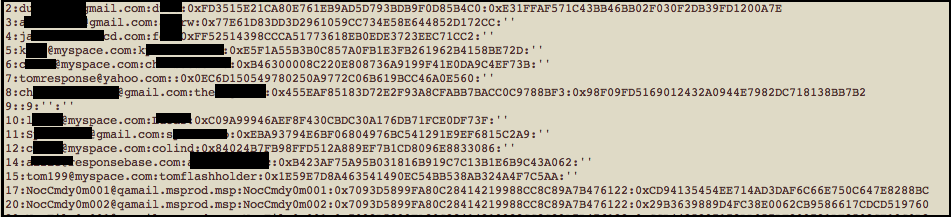
As you can see, it takes the form of unique ID that increments, e-mail address, username, and then two hashes. All of the fields except the unique ID can be blank.To answer the next question, "Why two hashes?" well ... ¯\_(ツ)_/¯. That's something I plan on looking at but I haven't gotten around to it yet.
Update: 7/7/16: Just as I was finalizing this post, I ran across CynoSure Prime's analysis where they managed to crack almost every single hash in this dataset. You can find their blog post here. It turns out the second hash is actually the original password, (full length with upper case characters) salted with the user_id. I'm going to leave most of this blog entry unmodified even though how to parse the list can certainly be optimized based on this new info. </Update>
Other random tidbits: The final unique ID is 1005290998. That's significantly higher than the number of accounts in this dataset so there are large chunks of accounts that were deleted at some point in time. My guess is when a user deleted their MySpace account it really was deleted in which case, kudos to MySpace for doing that! That's just a guess though. As you would expect the first accounts were administrative accounts and system process accounts. I know I blocked out the user e-mails but I will admit I googled the first name. When I found his LinkedIn profile my first reaction was, "Wow, he needs brag about his accomplishments more than just saying:"
Developed, and launched the initial Myspace community which currently has over 100 million members and was acquired by Fox Corp. for $580 million.
I mean if it was me I would post that database dump on my resume! Of course further googling led me to to the book "Stealing MySpace." Reading about all the drama that went on and suddenly there went my evening. Needless to say, the general layout of the dataset looks legit but one more interesting fact was all those gmail accounts. MySpace was created in 2003, Gmail opened for invitation access in 2004, and the lead engineer of MySpace left in 2003. So employees were able to update their accounts after they had left the company. Once again, kudos to MySpace but that was surprising.
Password Hash Format:
I initially learned from Troy Hunt's posts that the hashes were unsalted SHA1 with the plaintext lowercased and then truncated to 10 characters long. Therefore the password:
123#ThisIsMyPassword
would be saved as:
123#thisis
I've heard some people say that this means hackers can just brute force the entire key-space. If I was feeling nit-picky I could argue *technically* that's beyond the reach of commercial setups as 70^10 is still a really big number (27 characters + 10 digits, + 33 special characters). In reality though by intelligently searching the key-space, (who uses commas in their password?), a vast majority of unsalted password hashes can be cracked under that format. It's a bit of a moot point though since the real issue is using such a fast unsalted hash. Ah 2008, when it was still acceptable to claim ignorance for using a bad hashing set-up.
Long story short, from my experiments so far I can confirm that it appears all the hashes had their plaintexts lowercased and truncated to 10 characters. Also, yes, serious attackers are very likely to crack almost every password in this list.
Cracking MySpace Passwords With John the Ripper (Take 1):
After glancing around the dataset, the next thing I wanted to do was start cracking. To do this, I needed to extract and format the hashes. My first attempt to do this yielded the following script:
cat Myspace.com.txt | awk -F':' '{if (length($2) > 3) {print "myspace_big_hash1:" substr($4,3); if (length($5) > 3) {print "myspace_big_hash2:" substr($5,3)}}}' > myspace_clean_big.hsh
To point out a couple of features, I was labeling my data-sets so they are correctly identified in my input file, (I maintain different input files for different data sets but still having that name there has saved me trouble in the past), and I was removing blank hashes. Also I was stripping the username and e-mail addresses since I really didn't want to see passwords associated with names. The problem was the resulting file was huge. I didn't save it, but it was bigger than the original list! I couldn't afford the full naming convention. Therefore I switched to to following script:
cat Myspace.com.txt | awk -F':' '{if (length($2) > 3) {print substr($4,3); if (length($5) > 3) {print substr($5,3)}}}' > myspace_temp.hsh
And then to remove duplicates I ran:
sort -u myspace_temp.hsh > myspace_big.hsh
The resulting file was a little under 8 gigs which was better. Problems occurred though when I tried to load the resulting hash file into JtR. More specifically after letting it run overnight, JtR still hadn't loaded up the password list and started making guesses. That kind of makes sense, That's way more passwords than normal to parse and my laptop only had 8 gigs of ram so even in an ideal case the whole list probably couldn't be stored in memory. That's not an ideal cracking situation. Being curious, I then decided to try and load it up in Hashcat.
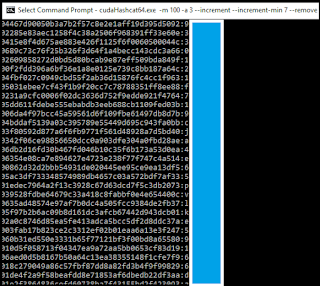
Cracking MySpace Passwords With Hashcat:
Loading up the dump in Hashcat was interesting since it gave me warnings about records in the dataset that weren't parsed correctly.

Regardless, once all was said and done, I ended up with the following error:
ERROR: cuMemAlloc() 2
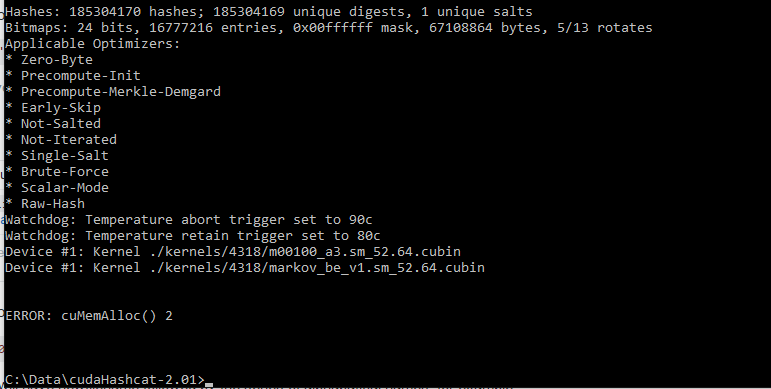
Doing some quick Googling, I found out the cause was that the GPUs ran out of memory trying to load the hashes. Not surprising but it meant I had to take a different approach if I wanted to crack any hashes from this set.
The easiest way to do this was to split the full list up into smaller chunks and then crack each section by itself. One way to do that is with the split command
split -l 5000000000 myspace_big.hs myspace_split_
This will break up the list into 5 million hash chunks that follow the line of myspace_split_aa, myspace_split_ab .... The downside is since you have to crack each file individually, the total cracking time has been increased by close to a factor of 40. I'd recommend playing with the file size to maximize the total number of hashes per file that your GPU supports. On the plus side, after all that I can now finally crack passwords!
 |
| Finally cracking passwords |
One issue I had was that there were so many hashes cracking all the time that it was hard to see the status of my session. It's not that my attack was effective, but with a list that large it's hard not to crack something. I belatedly realized I could pause hashcat, print the status and then resume. Or are Jeremi Gosney replied on Twitter, I could have used the following switch with Hashcat:
-o /dev/null
Closing Thoughts:
I'll admit I'm writing this conclusion with CynoSure Prime's analysis fresh in my mind. While the MySpace list is great for giving me a real world challenge to knock my head against, I'm not sure how useful it'll be from a research perspective. The 66 million salted hashes that were created from the original plaintexts will be nice for new training and testing sets so researcher's don't have to keep using RockYou for everything. That being said, MySpace is actually an older list than RockYou. Also I fully expect there to be a lot of overlap in the passwords between the two datasets. RockYou's entire business model was allowing apps to work across multiple social networking sites in the era before federated logins. RockYou was storing MySpace + LiveJournal + Facebook passwords in the clear so its app could post cross-post across all of them. Statistically I expect MySpace and RockYou to be very similar.
What worries me though, and what makes the MySpace list special, is it has user information associated with all those 360 million accounts + password hashes. Just about everyone who did any social networking and is between the ages of 24 and 40 is in this dump. I realize this list has been in the hands of criminals for the last eight years and a lot of the damage has already been done. Still, now that this list is public it enables many more targeted attacks to be carried out by malicious actors from all over the internet. How long before we start seeing the top 100 celebrity passwords posted on sites like Gawker? What about ex's using this information against former partners? Previous public password dumps have been much more limited or didn't contain e-mail addresses. I really don't know what will happen with this one. Hopefully I'm being overly paranoid but it's hard not to think about the downsides associated with this dump being widely distributed. On the plus side, hopefully this is the only mega-breach we'll see with weak password storage. Sites like Google and Facebook are now using very strong hashes which will limit a lot of damage if their user information is disclosed in the future.
如有侵权请联系:admin#unsafe.sh