目录
前言 开源治理落地关键技术
一、 为什么需要二进制软件成分分析
二、 二进制文件可以分析哪些风险
三、 什么是二进制文件
四、 二进制文件是如何生成的
五、 二进制文件基本结构
六、 二进制软件成分分析原理
七、 二进制软件成分分析实践应用
本文字数:4718 阅读时长:6分钟
小 序
数字经济时代,随着开源应用软件开发方式的使用度越来越高,开源组件逐渐成为软件开发的核心基础设施,但同时也带来了一些风险和安全隐患。为了解决这些问题,二进制软件成分分析技术成为了一种有效的手段之一。通过对二进制软件进行成分分析,可以检测其中的潜在风险,并提供对用户有价值的信息。
本文将从二进制软件成分分析诞生背景、二进制文件可以分析哪些安全风险、二进制技术原理以及实践应用等维度深度剖析二进制软件成分分析关键技术。
01 为什么需要二进制软件成分分析
在工业系统、车联网系统、银行券商系统和嵌入式系统中,有无数的二进制程序和库,这些源程序可能长期丢失或是私有的,这意味着无法使用常规方法对这些程序和库进行修补或在源代码级别上评估其安全性。
供应链场景下,对于采购的交付件制品,大多无法提供源码,对于此类采购产品需要上线,或者需要集成到自研产品中的,则需要提前进行二进制制品的检测,进行安全评估。
在整个数字供应链的场景下,二进制检测的需求越发重要。
SCA的二进制检测可以对源代码检测起到很好的补充:
二进制 SCA 检测对象为二进制构建产物,无需源码。
二进制 SCA 和源代码 SCA 检测阶段不同,源代码 SCA 在开发阶段检测,二进制 SCA 在测试、交付阶段检测。
在语言支持上互补,对 C++、C、Java、Go 等语言良好支持。
在检测结果上给予补充,可检测静态链接库和在构建过程中引入的开源软件。
当然二进制成分分析也存在一些技术挑战:
无法准确地确定程序中的变量和函数名。
分析过程可能会因为一些代码混淆和程序加固技术而变得困难或无法进行。
二进制软件成分分析和源代码成分分析都不可或缺,在不同的阶段和场景下具备各自的优势。
02 二进制文件可以分析哪些风险
高级语言和二进制机器语言之间存在很大的语义鸿沟,因此很难知道它们如何进行联系。编译后的程序不一定会符合开发者的意图。存在二进制级别的后门程序和恶意代码植入等可能被忽视的风险。
二进制软件成分分析可以对提供的软件包/固件进行全面分析,通过解压获取包中所有待分析文件,基于组件特征识别技术以及各种风险检测规则,获得相关被测对象的组件SBOM清单和潜在风险清单。
主要包括以下几类:
开源软件风险:检测包中的开源软件风险,如已知漏洞、License合规等。
安全配置风险:检测包中配置类风险,如硬编码凭证、敏感文件(如密钥、证书、调试工具等)问题、OS认证和访问控制类问题等。
信息泄露风险:检测包中信息泄露风险,如IP泄露、硬编码密钥、弱口令、GIT/SVN仓泄露等风险。
安全编译选项:支持检测包中二进制文件编译过程中相关选项是否存在风险。
在了解二进制成分分析是如何分析出上述风险项之前,需要对二进制文件的定义,二进制文件的生成过程,以及二进制文件的基本结构和运行时的内存结构进行了解。
03 什么是二进制文件
二进制文件通常指将属于每个程序的所有二进制代码(机器指令) 和数据(变量、常量等) 存储在一个自包含文件中。这些文件包含可在对应系统直接运行执行的二进制文件,所以它们被称为二进制可执行文件,或者二进制文件。
狭义的二进制文件被定义为除文本文件以外的文件。即:文件内容由0、1组成,均可被称为二进制文件。
ELF格式和PE格式是Linux和Windows操作系统上使用最广泛的二进制格式。
PE格式(Portable Executable):应用于Windows操作系统,包括可执行文件“EXE、SCR”、动态链接库“DLL、OCX、CPL、DRV”、驱动“SYS、VXD”、对象文件“OBJ”;
ELF格式(Executable and Linkable Format):应用于Unix、Linux系统,包括可执行文件、动态链接库“so”、可重定位文件“o”、内核模块“ko”;
Mach-O格式(Mach Object File Format):应用于MacOS系统,类似于 Linux 和大部分 UNIX 的原生格式 ELF(Extensible Firmware Interface);
其他格式:移动设备应用程序“APK、IPA”,压缩文件“lzma、xz、zip、bz、tar、arj、lzo 、tar.gz、rar、7z、rpm、deb”,固件镜像“uimage、fit image、zimage、IMG0、TR”,文件系统“cramfs、yaffs、jffs2、cpio、squashfs、ubi”等。
04 二进制文件是如何生成的
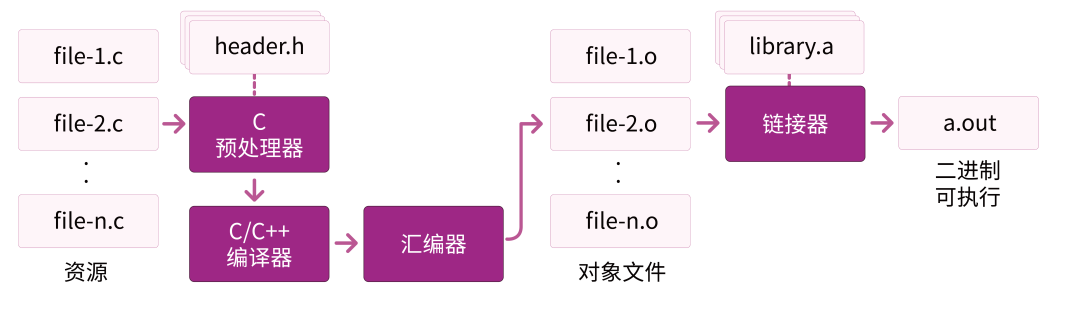
图1 二进制文件生成流程
二进制文件生成主要有四个步骤,以C语言为例:
预处理: 使用预处理器(cpp) 处理C语言文件中的预处理命令。这时候C语言文件还是一个.c文件;
编译: 使用C编译器gcc,将C语言源码文件编译成汇编文件file.s.;
汇编: 使用汇编器as将汇编代码汇编成二进制的.o文件 (又称目标文件);
链接:最后使用链接器ld将目标文件和目标文件中用到的一些库文件进行链接生成Linux下elf格式的可执行文件a.out,这个可执行文件才可以在Linux平台下面运行。
05 代码二进制文件基本结构
在开始分析二进制文件之前,我们需要先了解二进制文件的基本结构。一个ELF二进制文件通常包括以下几个部分:
.data:已经初始化的全局变量/局部静态变量;
.bss:未初始化的全局变量/局部静态变量;
.got.plt:全局偏移量表,保存全局变量引用的地址;
.rodata:只读数据;
.text:代码节,保存了程序执行的代码二进制指令;
.init:程序初始化和终止的代码;
Header:包含程序的基本信息,如入口地址、代码段的起始地址、数据段的起始地址等。
图2 二进制文件结构和运行内存结构关系
当运行可执行文件时,OS会fork一个进程,execve把可执行文件加载到进程的用户态内存,然后从内核返回,再跳转到ELF文件的入口地址_start,调用main()函数,进入代码段。
进程的内存段包括:
stack:栈,向低地址生长;
heap:堆,向高地址生长;
data:读写权限的数据段;
code:具有执行权限的数据段。
可以看到和源码相关的是代码段,对应二进制文件的.rodata节,.text节,.init节,header。其中rodata(read-only-data)段存储常量数据,比如程序中定义为const的全局变量,#define定义的常量,以及诸如“Hello World”的常量。
06 二进制软件成分分析原理
1
二进制检测技术分类
图3 悬镜SCA检测能力分类树形结构
可以将二进制成分分析技术分为两类,或是这两类的组合,具体如下。
静态分析:静态分析技术可在不运行二进制文件的情况下对二进制文件进行分析。这种方法有两个优点: 可以一次性分析整个二进制文件,且不需要特定的CPU来运行二进制文件。可以在x86计算机上静态分析ARM二进制文件。
静态分析一般有两种方式:静态反汇编、基于多维特征提取的比对。
静态反汇编:涉及在非执行情况下提取二进制文件的指令。静态反汇编的目标是将二进制代码转换为汇编代码的过程。一些反汇编工具可以将二进制文件转换为汇编指令序列,以帮助分析程序的代码结构和控制流。通过反汇编可以还原程序的指令序列、跳转指令、条件分支等控制结构,从而构建控制流图。
源码->编译->二进制程序->反汇编-> 控制流图(CFG)有向图 G(V,E) 。
在生成控制流图后,可以结合语法相似特征,图相似性特征,函数相似特征,以及常量字符串和立即数进行综合分析,计算和开源组件的相似度和排名,来确定引入的成分信息。
但是反汇编也有一定的挑战,对于不同编译器,编译安全配置,编译优化等级,CPU架构等等都会导致汇编代码的巨大差异,这对分析会造成很大的不确定性。
基于多维特征提取的比对分析:从二进制文件中提取各类静态特征,并且从开源组件项目中也提取项目内部的多维度特征。通过比对二进制制品中的多维度特征和已知组件的特征,来建立相似度和排序分析,最终过滤出符合条件的开源组件成分。
动态分析:与静态分析相反,动态分析会运行二进制文件并在执行时对其进行分析。这种方法通常比静态分析更简单,因为可以了解整个运行时状态,包括变量的值和条件分支的结果。
在应用执行过程中,利用运行时插桩检测技术,检测应用真实运行加载的第三方组件,可排除未执行加载冗余的组件,检测精度高。
相对的,仅能看到执行的代码,因此这种方法可能会遗漏程序中一部分。但是遗漏的部分也可能是程序永远不会触达的部分,就算有风险也是可以忽略。具体需要结合漏洞可达性进行进一步分析。
图4 运行时SCA技术基本原理实现
2
基于多维特征二进制成分分析技术方案
二进制检测流程如下图所示:
图5 二进制成分分析-检测流程
对要检测的包文件先进行递归解包和解压缩,然后对解出的文件进行格式识别,判断所属的二进制文件格式。对不同格式的文件执行相应逻辑提取多维度特征,再运用相似度算法,结合开源组件知识库的静态特征进行相似度计算,过滤和排名,最终确定引入的开源组件名称和版本。
3
二进制文件风险分析
从二进制文件中提取开源组件漏洞风险、许可证风险、安全配置、敏感信息。
漏洞风险:通过相似度算法确认组件GAV信息后,通过组件漏洞风险库,可以确认是否有漏洞影响当前使用的软件版本,如果当前使用的软件版本不在影响范围内,则初步说明漏洞可能不涉及。如果当前使用的软件版本存在漏洞,可通过升级软件版本至推荐版本解决。紧急情况下也可以通过产品中收集的社区或者厂商给出的patch修复方式临时解决。
图6 源鉴SCA工具-二进制成分分析组件详情
许可证风险:基于组件GAV信息,可以分析出开源软件及对应的License。可分析软件是否合规,满足准入要求。如果使用的软件存在合规风险,则需要寻找相似功能且合规的开源软件进行替代或者有针对性的规避触发合规条款。
图7 源鉴SCA工具-二进制成分分析许可证详情
检测安全配置:二进制文件头里面有一些字段参数的配置信息可以提取出编译器上的不同编译选项。检测可执行二进制的编译选项,比如PIE, RELRO, Canaries, ASLR。识别二进制文件有哪些保护是没有开的。
检测敏感信息:密钥敏感信息、设备敏感信息、商业敏感数据、通用敏感信息检查可以有效避免打包过程中无意引入的敏感信息,避免信息泄漏。每种敏感信息类型都有特定的格式,通过正则或其他方式设计匹配规则,提取符合规则的信息。比如 邮箱,电话号码,用户密码,身份证号,IPv4,IPv6,URI,TOKEN, 私钥,公钥,MAC地址,GIT/SVN仓库弱口令、硬编码密钥等风险等等。
检测敏感文件:对用户上传的软件包/固件中存在的敏感文件如(密钥文件,证书文件,源码文件, 调试工具等)进行识别。
图8 源鉴SCA工具-二进制成分分析敏感信息详情
07 二进制软件成分分析实践应用
1
开发安全检测
源码级SCA结合二进制SCA的能力,预防开发流水线过程管控的疏漏,即使中途更换组件版本或配置错误的编译选项,仍可在编译构建和制品打包活动结束后进行二次检测。
图9 软件生产二进制检测阶段
无论在CI/CD Pipeline中自动拉取或手动上传,在检测后均可为软件制品的安全上线提供安全检测分析报告。
图10 丰富的接入二进制检测场景
2
供应链安全检测
利用二进制分析,将不同供应商的系统、自研应用集成之后进行统一的系统安全测试,厘清责任归属,发现问题及时通知供应商进行修复。
图11 二进制制品引入检测
源鉴SCA结合运用丰富的知识库指纹样本:文件结构特征、文件hash分析、各类静态特征等融合分析能力,全面提升扫描精度:
基于丰富的知识库特征样本:知识库覆盖主流的代码托管平台GitHub、GitLab、BitBucket、Gitee、Codeberg等,覆盖C C++开源项目数超过8W+,JAVA开源项目数5KW+,生成的指纹特征2亿+;
二进制基于多维特征的相似度检测算法:算法稳定高效,可以做到覆盖全面的CPU架构x86/x64,ARM/ARM64,PowerPC,MIPS;主流的操系统Linux,Android,Windows,MacOS,QNX;支持官方的文件格式APK文件,固件,镜像,文件系统等的检测;
精准定位:根据相似度算法的执行结果,能够准确定位到具体的开源项目、版本,并关联分析出子依赖的组件信息以及漏洞和许可的风险信息;
灵活的自适应:相似度阈值可动态调节,减少误报和漏报的概率。
源鉴SCA在满足实现源码级检测技术的基础上,结合二进制SCA技术、运行时SCA技术及漏洞可达性分析等技术,有效帮助开发人员更好地管理和维护软件成分,减少无效漏洞的运营干扰,提高软件的安全性和可靠性,助力企业建立并有效落地数字供应链安全治理体系,保障数字供应链安全。
+
推荐阅读
关于“悬镜安全”
悬镜安全,起源于北京大学网络安全技术研究团队“XMIRROR”,创始人子芽。作为DevSecOps敏捷安全领导者,始终专注于以“代码疫苗”技术为内核,凭借原创专利级“全流程数字供应链安全赋能平台+敏捷安全工具链”的第三代DevSecOps智适应威胁管理体系,创新赋能金融、车联网、泛互联网、智能制造、通信及能源等行业用户,构筑起适应自身业务弹性发展、面向敏捷业务交付并引领未来架构演进的共生积极防御体系,持续守护中国数字供应链安全。了解更多信息请访问悬镜安全官网:www.xmirror.cn
如有侵权请联系:admin#unsafe.sh