通过request库无法直接爬取,返回521
1 | >>> import requests |
通过浏览器访问,第一次访问时候明显有几秒延迟,之后页面正常打开
分析其521状态返回的js脚本
1 | var x = "document@charAt@while@catch@7@Jun@parseInt@Path@1496825590@window@10@3@DOMContentLoaded@String@join@5CMN@fromCharCode@0@09@36@f@l@href@captcha@53@toString@2@X@cd@var@658@if@dc@cookie@3D@false@GMT@i@__phantomas@1500@e@challenge@for@Ek@function@_phantom@replace@1y@07@try@addEventListener@Expires@26l3@__jsl_clearance@Wed@17@location@setTimeout@q@1@length@eval@x@return@else@attachEvent@onreadystatechange".replace(/@*$/, "").split("@"), |
脚本经过一系列的转发界面之后执行eval,我们将eval替换为console.log可以看到其实执行了如下代码
1 | var l = function() { |
进一步分析while (window._phantom || window.__phantomas) {}; 当发现是_phantom或者__phantomas后就直接进入死循环了。
而最终l函数进一步解码,到的dc变量,并设置__jsl_clearance的cookies。
另外也找到了之所以第一次访问seebug的时候会出现1.5秒的延迟的原因
setTimeout('location.href=location.href.replace(/[\?|&]captcha-challenge/,\'\')', 1500);
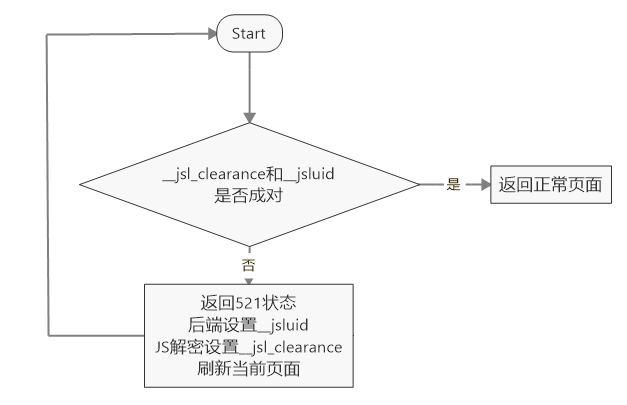
分析反爬逻辑
通过控制变量法,尝试清除每一个seebug的cookies,发现当没有__jsl_clearance或__jsluid这两个cookies的时候就会出现521状态码
进一步测试,__jsl_clearance和__jsluid两个cookies如果不是成对的话,也会出现521状态码。

python如何爬取
爬取转换为如何获得成对的__jsl_clearance和__jsluid
__jsluid可直接从头中获得
__jsl_clearance获得通过修改eval为eavl_s
1 | var eval_s=function (str) { |