反编译原理控制流分析
说明最近在整理反编译器设计和实现相关的知识,看看能不能有新的灵感。发现 vasthao 大哥的《[原创]反编译原理(5)-控制流分析》https://bbs.kanxue.com/thread-247 2023-9-24 17:5:50 Author: mp.weixin.qq.com(查看原文) 阅读量:14 收藏
说明最近在整理反编译器设计和实现相关的知识,看看能不能有新的灵感。发现 vasthao 大哥的《[原创]反编译原理(5)-控制流分析》https://bbs.kanxue.com/thread-247 2023-9-24 17:5:50 Author: mp.weixin.qq.com(查看原文) 阅读量:14 收藏
说明
预置模式
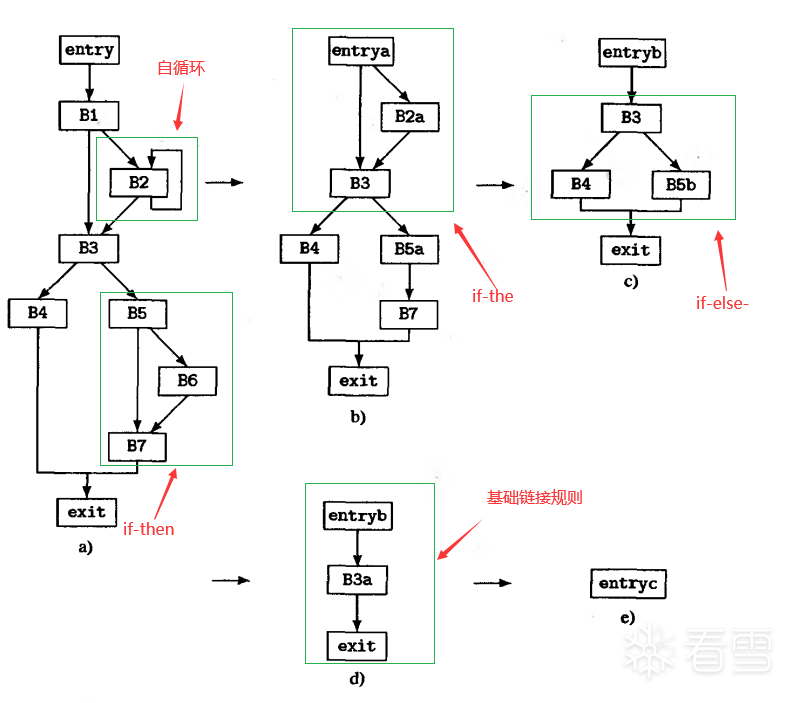
流图塌缩
int fun(int a, int b)
{
int ret = 0;
if (getchar() > 0x10) {
ret = a+b;
} else {
ret = a-b;
if (getchar()>0x20) {
printf("hello");
printf("ret=xx");
return ret;
}
}
printf("hi");
printf("ret=xx");
return ret;
}
int fun(int a, int b)
{
int ret = 0;
if (getchar() > 0x10) {
ret = a+b;
} else {
ret = a-b;
if (getchar()>0x20) {
printf("hello");
goto LABEL
}
}
printf("hi");
LABEL:
printf("ret=xx");
return ret;
}
看雪ID:wInFoG_2017
https://bbs.kanxue.com/user-home-985676.htm
# 往期推荐
3、安卓加固脱壳分享
球分享
球点赞
球在看
文章来源: https://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458518567&idx=1&sn=92d799d8624be2e9bd51db952212ebd5&chksm=b18d34ad86fabdbb8baf88b8914fd2643d6ccb7439cd08bc6d7c9f181f63770a355d71005563&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh