以及 Pod 是否已经完成调度,如果未完成调度的话就无法完成原地重启(无法使用部署到节点上的 kruise-daemon):
1 2 3 4 5
if !kubecontroller.IsPodActive(pod) { return admission.Errored(http.StatusBadRequest, fmt.Errorf("not allowed to recreate containers in an inactive Pod")) } elseif pod.Spec.NodeName == "" { return admission.Errored(http.StatusBadRequest, fmt.Errorf("not allowed to recreate containers in a pending Pod")) }
1.3 将 Pod 中的信息注入到 CRR
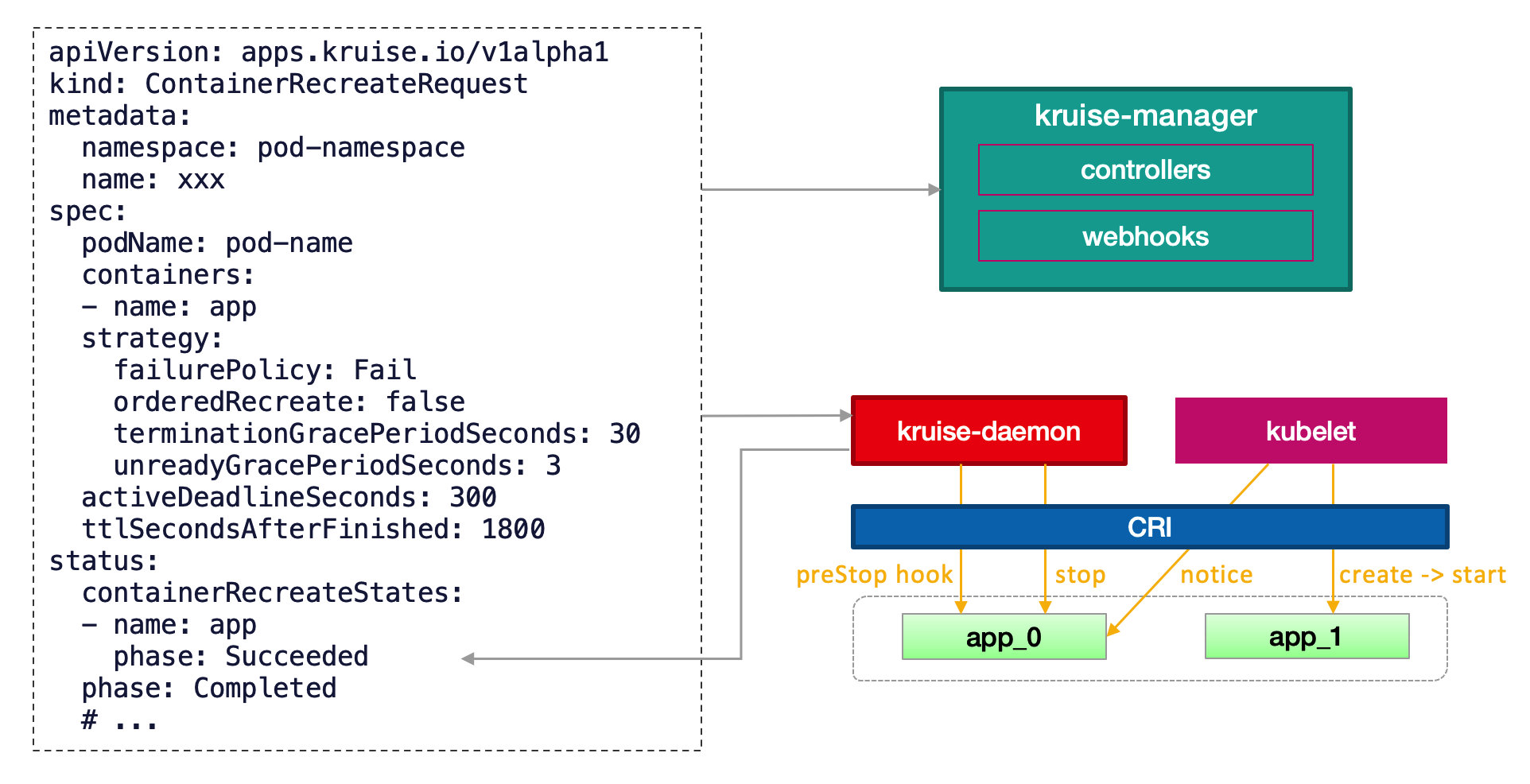
CRR 的运行需要获取 Pod 的信息,比如获取 Pod 中的 Lifecycle.PreStop 让 kruise-daemon 执行 preStop hook 后把容器停掉,获取指定容器的 containerID 来判断重启后 containerID 的变化等。
type ContainerRecreateRequestStatus struct { // Phase of this ContainerRecreateRequest, e.g. Pending, Recreating, Completed Phase ContainerRecreateRequestPhase `json:"phase"` // Represents time when the ContainerRecreateRequest was completed. It is not guaranteed to // be set in happens-before order across separate operations. // It is represented in RFC3339 form and is in UTC. CompletionTime *metav1.Time `json:"completionTime,omitempty"` // A human readable message indicating details about this ContainerRecreateRequest. Message string`json:"message,omitempty"` // ContainerRecreateStates contains the recreation states of the containers. ContainerRecreateStates []ContainerRecreateRequestContainerRecreateState `json:"containerRecreateStates,omitempty"` } type ContainerRecreateRequestContainerRecreateState struct { // Name of the container. Name string`json:"name"` // Phase indicates the recreation phase of the container. Phase ContainerRecreateRequestPhase `json:"phase"` // A human readable message indicating details about this state. Message string`json:"message,omitempty"` }
CRR controller 不断更新 container 的重启信息到 status 中。
1 2 3
func(r *ReconcileContainerRecreateRequest)syncContainerStatuses(crr *appsv1alpha1.ContainerRecreateRequest, pod *v1.Pod)error { ... }
controller 同步 container status 的逻辑非常重要,在这里笔者曾经遇到一个诡异的问题,就是创建了好几个 CRR 后,其中几个 CRR 一直卡在 Recreating 的状态,即使 container 已经重启完成或者 TTL 到期也不会发生变化,详情可以见这个 issue。原因就是同步 container status 的逻辑跟时钟同步有关:
1 2 3 4 5 6 7 8 9
containerStatus := util.GetContainerStatus(c.Name, pod) if containerStatus == nil { klog.Warningf("Not found %s container in Pod Status for CRR %s/%s", c.Name, crr.Namespace, crr.Name) continue } elseif containerStatus.State.Running == nil || containerStatus.State.Running.StartedAt.Before(&crr.CreationTimestamp) { // 只有 container 的创建时间晚于 crr 的创建时间,才认为 crr 重启了 container,假如此时 CRR 所处节点或者 Pod 所在节点的时钟发生漂移,那有可能出现 container 创建的时间早于 crr 创建时间,即使该 container 是由 crr 控制重启。 continue } ...
经过排查后发现确实是好多 k8s Node 的 NTP server 出现问题导致时钟漂移,再加上上述的逻辑,就不难解释为何 CRR 会卡住不动了。
2.2 make pod not ready
CRR 在重启 container 之前会给 Pod 注入一个 v1.PodConditionType - KruisePodReadyConditionType 并置为 false, 使 Pod 进入 not ready 状态,从 service 的 Endpoint 上摘掉流量。
// once first update its phase to recreating if crr.Status.Phase != appsv1alpha1.ContainerRecreateRequestRecreating { return c.updateCRRPhase(crr, appsv1alpha1.ContainerRecreateRequestRecreating) }
3.3 wait for unready grace period
CRR 中的 unreadyGracePeriodSeconds 表示在 2.2 步骤中将 Pod 设置为 not ready 后等待多久再执行 restart container。
1 2 3 4 5 6 7 8
// crr_daemon_controller.go
leftTime := time.Duration(*crr.Spec.Strategy.UnreadyGracePeriodSeconds)*time.Second - time.Since(unreadyTime) if leftTime > 0 { klog.Infof("CRR %s/%s is waiting for unready grace period %v left time.", crr.Namespace, crr.Name, leftTime) c.queue.AddAfter(crr.Namespace+"/"+crr.Spec.PodName, leftTime+100*time.Millisecond) returnnil }
if crr.Spec.ActiveDeadlineSeconds != nil { leftTime := time.Duration(*crr.Spec.ActiveDeadlineSeconds)*time.Second - time.Since(crr.CreationTimestamp.Time) if leftTime <= 0 { klog.Warningf("Complete CRR %s/%s as failure for recreating has exceeded the activeDeadlineSeconds", crr.Namespace, crr.Name) return reconcile.Result{}, r.completeCRR(crr, "recreating has exceeded the activeDeadlineSeconds") } duration.Update(leftTime) }