原文标题:SYSML: StYlometry with Structure and Multitask Learning: Implications for Darknet Forum Migrant Analysis
原文作者:Pranav Maneriker, Yuntian He, Srinivasan Parthasarathy
原文链接:https://doi.org/10.18653/v1/2021.emnlp-main.548
发表会议:Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing(EMNLP)
PDF:https://aclanthology.org/2021.emnlp-main.548.pdf
视频:https://aclanthology.org/2021.emnlp-main.548.mp4
主题类型:暗网分析
笔记作者:周依萍@Web攻击检测与追踪
主编:黄诚@安全学术圈
1、研究概述
暗网市场论坛作为一类典型的加密市场,通常指托管在Tor网络在暗网上运营的在线交易平台。暗网市场一般用于非法毒品交易的资源、成人内容、假冒商品和信息、泄露的数据、欺诈和其他非法服务。所以该类平台使用加密技术来确保交易匿名性和安全性,市场常使用例如比特币的加密货币作为流通货币,且由于使用Tor网络,进一步保证IP匿名性以及位置跟踪的额外匿名化。
个人用户在加密市场上的身份一般只与一个用户名相关联,因此暗网市场上建立信任的体系并不遵循普通电子商务中流行的传统模式。且这些论坛上的互动手段主要是依靠用户发布的文本。这使得对这些论坛文本风格的分析成为一个引人注目的问题。同时,暗网市场因其违法属性存在较高频率关闭市场的情况,当一个论坛关闭时,用户会迁移到新的论坛。
图1 执法部门查获丝绸之路市场
在此背景下,论文将了解文本风格和信任信号策略在暗网市场迁移时的演变规律作为研究目标,旨在提高多个暗网论坛中用户识别和跟踪的准确性和效率。作者提出了基于文体测定学(Stylometry)的面向自然语言的多任务学习方法SYSML,并采用图嵌入(Graph Embedding)对用户的活动进行低维表征用于论坛文本的作者归属判断。
图2 SYSML整体工作流
图2表示SYSML的整体工作流程,包含数据建模,特征提取以及任务学习模块。数据建模方面,作者引入集(Episode)概念对暗网论坛的帖子进行建模,每一集包括若干相同作者帖子的文本内容(Text)、发布时间(Time)以及上下文信息(Context)的嵌入信息,具体而言分为文本嵌入、时间嵌入与上下文结构嵌入。
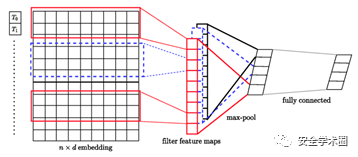
文本嵌入针对具体的帖子,首先对帖子的文本信息进行标记(Tokenize)得到嵌入向量,然后输入到CNN经过最大池化以及全连接层以及dropout得到最终的文本嵌入向量,如图3所示;时间信息嵌入较为简单,由于不同论坛的时间粒度不一致所以直接采用日期信息,使用每个帖子的星期来计算时间嵌入;最后上下文结构嵌入采用了社交网络常用的异构图(Heterogeneous Graph)方法进行表征,将节点分为用户(Users)、主题线(Thread)和子论坛(Subforum),通过定义7种元路径来捕捉暗网论坛建立的异构图中所有的语义关系。将以上三种嵌入向量进行拼接后得到一条帖子的特征表示,在按照之前提到的集的概念,将若干帖子的特征拼接得到集的向量。
图3 文本嵌入CNN
得到集的特征向量后,下一步是对集进行嵌入,使用Transformer Pooling完成,如图4所示,得到最后任务学习的输入向量。
图4 Transformer Pooling结构
最后一步是任务学习,包括单任务学习及多任务学习。对于 SYSML,每个任务是一个度量学习(Metric Learning),用于学习不同集之间的距离,使其能够用于作者身份归因和交互建模任务。
2、贡献分析
a) 贡献点1:论文针对暗网论坛中用户表示问题,提出了使用文体测定学、异构图、元路径方法,实现了将含有时间信息的帖子利用文体测定学与访问标识(通过元路径图上下文信息表征论坛用户交互)耦合的表示学习方法来建模和增强用户表示。
b) 贡献点2:论文针对跨暗网市场的用户关联问题,提出了多任务学习方法,实现了一个新的框架,用于在多个暗网市场的多任务环境中训练提出的度量学习模型。
c) 贡献点3:论文针对模型效果问题,提出了消融实验,实现了消融研究下讨论各种优化的影响,强调了异构图上下文信息和多任务学习在Black Market Reloaded、Agora Marketplace、Silk Road和Silk Road 2.0这4个暗网市场数据集上优异的表现。
3、代码分析
代码链接:https://github.com/pranavmaneriker/sysml
a)代码使用类库分析,是否全为开源类库的集成?
代码主要包括三部分:数据预处理、异构图嵌入以及训练模型(CNN嵌入模型、度量学习的单任务和多任务学习):
(1)数据预处理代码语言为Python,主要使用Pandas库以及BeautifulSoup库处理原始数据集;另外包括文本Tokenize以及集的构造也是用Python到相关库进行编写 (2)异构图嵌入代码主要是开源代码,语言为C及C++语言,使用包含CSV parser、pbar和metapath2vec三个类库 (3)训练模型代码主要使用Pytorch深度学习框架,根据各个模型的架构进行编写
b)代码实现难度及工作量评估;
实现难度为中等偏上,一些特征的构建借助了现成的开源库,但都进行了不同程度的改造,模型方面基本是在pytorch框架的基础上自行编写。工作量丰满。
c)代码关键实现的功能(模块)。
market_parser:4个暗网市场的原始数据集,封装为包并编写脚本一键粗清洗 graph embeddings:异构图嵌入特征生成 custom_tokenizers:文本数据标记类 custom_dataset:数据集类 custom_models:包括单任务训练类SingleDatasetModel,多任务训练类MultiDatasetModel以及具体的各种模型(CNNEmbedding,TransformerPooling,…)
4、论文点评
结论:论文提出的方法在四个不同的暗网论坛(SR,SR2, Agora, BMR)上实现了最先进的性能,使用信息检索类指标MRR和Recall@k分别提高了2.5倍和2倍。并且对实验结果从用户角度,参数角度进行详细解释,例如结果发现“新用户”的关联效率更高,因为暗网论坛一般要求新入用户需要在指定板块发布一定数量的帖子才能解锁相应的权限。总体上来说,论文在对应方向有创新点(图嵌入、多任务学习),整体上工作量也比较饱满,实验进行了相关参数的消融测试,对结论也从多角度进行了解释。
缺点1:模型只考虑了文本,风格测定其实和帖子中图片的使用,或者一些用户元数据可能也有较大关联;
改进方向1:数据集加入用户元数据的关联,引入图片等数据后模型可以向多模态的方向升级。
缺点2: 目前不清楚在用户故意试图混淆其写作风格或使用多种写作风格的情况下方法的表现情况;
改进方向2:加入更多实验测试,可以考虑向对抗模型的方向进一步研究,使用对抗训练来提高方法的稳健性。
缺点3:实验仅在实验环境下对特定收集好的数据集进行评估,不知道在真实环境下的泛化能力表现如何,且理论上能在暗网论坛上进行用户关联,也可以在一般社交媒体上使用;
改进方向3:可以探讨使用迁移学习来提高所提方法的泛化性能。
5、论文文献
[1] Maneriker P, He Y, Parthasarathy S. SYSML: StYlometry with Structure and Multitask Learning: Implications for Darknet Forum Migrant Analysis[A]. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing[C]. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021: 6844–6857.
6、论文团队
Pranav Maneriker是一名俄亥俄州立大学博士,感兴趣的领域是自然语言处理和机器学习的交叉点。https://pranavmaneriker.github.io/ Srinivasan Parthasarathy,领导俄亥俄州立大学数据挖掘研究实验室,隶属于人工智能研究实验室,对以下领域广泛感兴趣高性能数据分析、图分析和网络科学、机器学习和数据库系统。http://web.cse.ohio-state.edu/~parthasarathy.2/
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh